网站(Web)压测工具Webbench源码分析
一、我与webbench二三事
Webbench是一个在linux下使用的非常简单的网站压测工具。它使用fork()模拟多个客户端同时访问我们设定的URL,测试网站在压力下工作的性能。Webbench使用C语言编写,下面是其下载链接:
http://home.tiscali.cz/~cz210552/webbench.html
说到这里,我赶脚非常有必要给这个网站局部一个截图,如下图:
第一次看到这张图片,着实吃了一精!居然是2004年最后一次更新,我和我的小伙伴们都惊呆了。不过既然现在大家还都使用,其中一定有些很通用的思想,所以我不妨学习一下,也能为以后的工具开发做铺垫。当然,另外一个让我冲动地想研究一下的原因是,webbench的代码实在太简洁了,源码加起来不到600行……
把webbench-1.5.tar.gz这个文件下载下来之后解压缩,进入webbench-1.5文件夹,然后执行make,就可以看到文件夹下多了一个可执行程序webbench。尝试运行一下,就可以得到如图所示的结果。
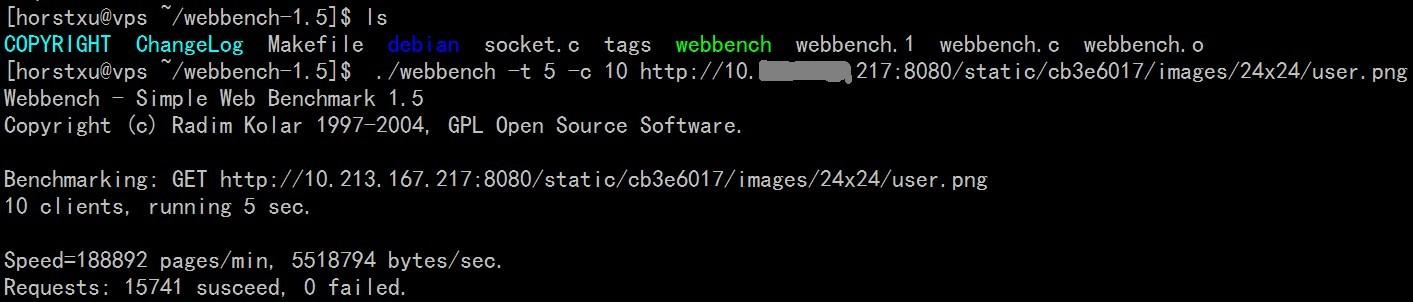
可以看到,我们模拟了10个client同时访问URL所示的某个图片,测试执行了5秒。最终得到的结果是,我们发送http
GET请求的速度为188892pages/min,服务器响应速度为5518794bytes/sec,请求中有15741个成功,0个失败。
大概知道了怎么用以后,我们就可以深入了解其源代码了。
二、与webbench的初步相识
我们首先来看一下webbench的工作流程,如下图:
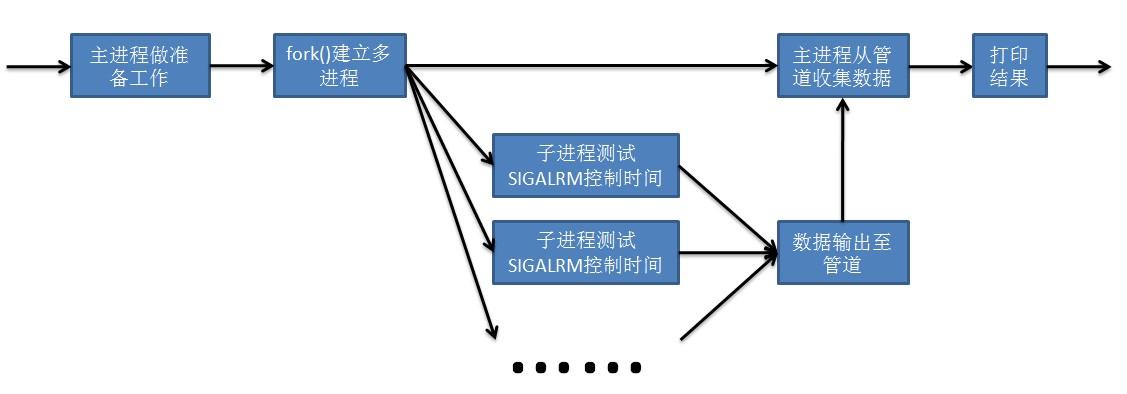
webbench主要的工作原理就是以下几点:
1. 主函数进行必要的准备工作,进入bench开始压测
2. bench函数使用fork模拟出多个客户端,调用socket并发请求,每个子进程记录自己的访问数据,并写入管道
3. 父进程从管道读取子进程的输出信息
4. 使用alarm函数进行时间控制,到时间后会产生SIGALRM信号,调用信号处理函数使子进程停止
5. 最后只留下父进程将所有子进程的输出数据汇总计算,输出到屏幕上
三、走进webbench的内心世界
接下来我们详细截图webbench的源代码。查看webbench的源代码,发现代码文件只有两个,Socket.c和webbench.c。首先看一下Socket.c,它当中只有一个函数int
Socket(const char *host, int clientPort),大致内容如下:

int Socket(const char *host, int clientPort)
{
//以host为服务器端ip,clientPort为服务器端口号建立socket连接
//连接类型为TCP,使用IPv4网域
//一旦出错,返回-1
//正常连接,则返回socket描述符
}
这段代码比较直观,因此就不列举其中的细节了。此函数供另外一个文件webbench.c中的函数调用。
接着我们来瞧一下webbench.c文件。这个文件中包含了以下几个函数,我们一一列举出来:
static void alarm_handler(int signal); //为方便下文引用,我们称之为函数1。
static void usage(void); //函数2
void build_request(const char *url); //函数3
static int bench(void); //函数4
void benchcore(const char *host, const int port, const char *req); //函数5
int main(int argc, char *argv[]); //函数6
下面我们分别做讲解。
(1)全局变量列表
源文件中出现在所有函数前面的全局变量,主要有以下几项,我们以注释的方式解释其在程序中的用途
volatile int timerexpired=0;//判断压测时长是否已经到达设定的时间
int speed=0; //记录进程成功得到服务器响应的数量
int failed=0;//记录失败的数量(speed表示成功数,failed表示失败数)
int bytes=0;//记录进程成功读取的字节数
int http10=1;//http版本,0表示http0.9,1表示http1.0,2表示http1.1
int method=METHOD_GET; //默认请求方式为GET,也支持HEAD、OPTIONS、TRACE
int clients=1;//并发数目,默认只有1个进程发请求,通过-c参数设置
int force=0;//是否需要等待读取从server返回的数据,0表示要等待读取
int force_reload=0;//是否使用缓存,1表示不缓存,0表示可以缓存页面
int proxyport=80; //代理服务器的端口
char *proxyhost=NULL; //代理服务器的ip
int benchtime=30; //压测时间,默认30秒,通过-t参数设置
int mypipe[2]; //使用管道进行父进程和子进程的通信
char host[MAXHOSTNAMELEN]; //服务器端ip
char request[REQUEST_SIZE]; //所要发送的http请求
(2)函数1: static void
alarm_handler(int signal);
首先,来看一下最简单的函数,即函数1,它的内容如下:
static void alarm_handler(int signal)
{
timerexpired=1;
}
webbench在运行时可以设定压测的持续时间,以秒为单位。例如我们希望测试30秒,也就意味着压测30秒后程序应该退出了。webbench中使用信号(signal)来控制程序结束。函数1是在到达结束时间时运行的信号处理函数。它仅仅是将一个记录是否超时的变量timerexpired标记为true。后面会看到,在程序的while循环中会不断检测此值,只有timerexpired=1,程序才会跳出while循环并返回。
(3)函数2 :static void
usage(void);
其内容如下:
static void usage(void)
{
fprintf(stderr,
"webbench [option]... URL\n"
" -f|--force Don't wait for reply from server.\n"
" -r|--reload Send reload request - Pragma: no-cache.\n"
" -t|--time <sec> Run benchmark for <sec> seconds. Default 30.\n"
" -p|--proxy <server:port> Use proxy server for request.\n"
" -c|--clients <n> Run <n> HTTP clients at once. Default one.\n"
" -9|--http09 Use HTTP/0.9 style requests.\n"
" -1|--http10 Use HTTP/1.0 protocol.\n"
" -2|--http11 Use HTTP/1.1 protocol.\n"
" --get Use GET request method.\n"
" --head Use HEAD request method.\n"
" --options Use OPTIONS request method.\n"
" --trace Use TRACE request method.\n"
" -?|-h|--help This information.\n"
" -V|--version Display program version.\n"
);
};
从名字来看就很明显,这是教你如何使用webbench的函数,在linux命令行调用webbench方法不对的时候运行,作为提示。有一些比较常用的,比如-c来指定并发进程的多少;-t指定压测的时间,以秒为单位;支持HTTP0.9,HTTP1.0,HTTP1.1三个版本;支持GET,HEAD,OPTIONS,TRACE四种请求方式。不要忘了调用时,命令行最后还应该附上要测的服务端URL。
(4)函数3:void build_request(const
char *url);
这个函数主要操作全局变量char request[REQUEST_SIZE],根据url填充其内容。一个典型的http
GET请求如下:
GET /test.jpg HTTP/1.1
User-Agent: WebBench 1.5
Host:192.168.10.1
Pragma: no-cache
Connection: close
build_request函数的目的就是要把类似于以上这一大坨信息全部存到全局变量request[REQUEST_SIZE]中,其中换行操作使用的是”\r\n”。而以上这一大坨信息的具体内容是要根据命令行输入的参数,以及url来确定的。该函数使用了大量的字符串操作函数,例如strcpy,strstr,strncasecmp,strlen,strchr,index,strncpy,strcat。对这些基础函数不太熟悉的同学可以借这个函数复习一下。build_request的具体内容在此不做过多阐述。
(5)函数6:int main(int
argc, char *argv[]);
之所以把函数6放在了函数4和函数5之前,是因为函数4和5是整个工具的最核心代码,我们把他放在最后分析。先来看一下整个程序的起始点:主函数(即函数6)。
int main(int argc, char *argv[])
{
/*函数最开始,使用getopt_long函数读取命令行参数,
来设置(1)中所提及的全局变量的值。
关于getopt_long的具体使用方法,这里有一个配有讲解的小例子,可以帮助学习:
http://blog.csdn.net/lanyan822/article/details/7692013
在此期间如果出现错误,会调用函数2告知用户此工具使用方法,然后退出。
*/ build_request(argv[optind]); //参数读完后,argv[optind]即放在命令行最后的url
//调用函数3建立完整的HTTP request,
//HTTP request存储在全部变量char request[REQUEST_SIZE] /*接下来的部分,main函数的所有代码都是在网屏幕上打印此次测试的信息,
例如即将测试多少秒,几个并发进程,使用哪个HTTP版本等。
这些信息并非程序核心代码,因此我们也略去。
*/ return bench(); //简简单单一句话,原来,压力测试在这最后一句才真正开始!
//所有的压测都在bench函数(即函数4)实现
}
这真是一件很浪费感情的事情,看了半天,一直到最后一句才开始执行真正的测试过程,前面的都是一些准备工作。好了,那我们现在开始进入到static int bench(void)中。
(6)函数4:static int bench(void);
源码如下:
static int bench(void){
int i,j,k;
pid_t pid=0;
FILE *f;
i=Socket(proxyhost==NULL?host:proxyhost,proxyport); //调用了Socket.c文件中的函数
if(i<0){ /*错误处理*/ }
close(i);
if(pipe(mypipe)){ /*错误处理*/ } //管道用于子进程向父进程回报数据
for(i=0;i<clients;i++){//根据clients大小fork出来足够的子进程进行测试
pid=fork();
if(pid <= (pid_t) 0){
sleep(1); /* make childs faster */
break;
}
}
if( pid< (pid_t) 0){ /*错误处理*/ }
if(pid== (pid_t) 0){//如果是子进程,调用benchcore进行测试
if(proxyhost==NULL)
benchcore(host,proxyport,request);
else
benchcore(proxyhost,proxyport,request);
f=fdopen(mypipe[1],"w");//子进程将测试结果输出到管道
if(f==NULL){ /*错误处理*/ }
fprintf(f,"%d %d %d\n",speed,failed,bytes);
fclose(f);
return 0;
} else{//如果是父进程,则从管道读取子进程输出,并作汇总
f=fdopen(mypipe[0],"r");
if(f==NULL) { /*错误处理*/ }
setvbuf(f,NULL,_IONBF,0);
speed=0; failed=0; bytes=0;
while(1){ //从管道读取数据,fscanf为阻塞式函数
pid=fscanf(f,"%d %d %d",&i,&j,&k);
if(pid<2){ /*错误处理*/ }
speed+=i; failed+=j; bytes+=k;
if(--clients==0) break;//这句用于记录已经读了多少个子进程的数据,读完就退出
}
fclose(f);
//最后将结果打印到屏幕上
printf("\nSpeed=%d pages/min, %d bytes/sec.\nRequests: %d susceed, %d failed.\n",
(int)((speed+failed)/(benchtime/60.0f)), (int)(bytes/(float)benchtime), speed, failed);
}
return i;
}
这段代码,一上来先进行了一次socket连接,确认能连通以后,才进行后续步骤。调用pipe函数初始化一个管道,用于子进行向父进程汇报测试数据。子进程根据clients数量fork出来。每个子进程都调用函数5进行测试,并将结果输出到管道,供父进程读取。父进程负责收集所有子进程的测试数据,并汇总输出。
(7)函数5:void benchcore(const
char *host,const int port,const char *req);
源码如下:
void benchcore(const char *host,const int port,const char *req){
int rlen;
char buf[1500];//记录服务器响应请求所返回的数据
int s,i;
struct sigaction sa;
sa.sa_handler=alarm_handler; //设置函数1为信号处理函数
sa.sa_flags=0;
if(sigaction(SIGALRM,&sa,NULL)) //超时会产生信号SIGALRM,用sa中的指定函数处理
exit(3);
alarm(benchtime);//开始计时
rlen=strlen(req);
nexttry:while(1){
if(timerexpired){//一旦超时则返回
if(failed>0){failed--;}
return;
}
s=Socket(host,port);//调用Socket函数建立TCP连接
if(s<0) { failed++;continue;}
if(rlen!=write(s,req,rlen)) {failed++;close(s);continue;} //发出请求
if(http10==0) //针对http0.9做的特殊处理
if(shutdown(s,1)) { failed++;close(s);continue;}
if(force==0){//全局变量force表示是否要等待服务器返回的数据
while(1){
if(timerexpired) break;
i=read(s,buf,1500);//从socket读取返回数据
if(i<0) {
failed++;
close(s);
goto nexttry;
}else{
if(i==0) break;
else
bytes+=i;
}
}
}
if(close(s)) {failed++;continue;}
speed++;
}
}
benchcore是子进程进行压力测试的函数,被每个子进程调用。这里使用了SIGALRM信号来控制时间,alarm函数设置了多少时间之后产生SIGALRM信号,一旦产生此信号,将运行函数1,使得timerexpired=1,这样可以通过判断timerexpired值来退出程序。另外,全局变量force表示我们是否在发出请求后需要等待服务器的响应结果。
四、昨天,今天,明天
了解了webbench的具体代码以后,下面一步就要考虑一下如何进行改进了。代码中有一些过时的函数可以更新一下,加入一些新的功能,例如支持POST方法,支持异步压测等,这些就留到以后去探索了。第一次写源码分析,望多多指教。希望本文能帮助大家在以后与webbench愉快地玩耍。且用且珍惜!
网站(Web)压测工具Webbench源码分析的更多相关文章
- [软件测试]网站压测工具Webbench源码分析
一.我与webbench二三事 Webbench是一个在linux下使用的非常简单的网站压测工具.它使用fork()模拟多个客户端同时访问我们设定的URL,测试网站在压力下工作的性能.Webbench ...
- [nghttp2]压测工具,源码编译并进行deb打包过程
编译环境:deepin 15.11桌面版 nghttp2下载地址:https://github.com/nghttp2/nghttp2 环境要求 emm只能在类Linux环境才能完整编译,想在Wind ...
- 并发工具CyclicBarrier源码分析及应用
本文首发于微信公众号[猿灯塔],转载引用请说明出处 今天呢!灯塔君跟大家讲: 并发工具CyclicBarrier源码分析及应用 一.CyclicBarrier简介 1.简介 CyclicBarri ...
- web压测工具http_load原理分析
一.前言 http_load是一款测试web服务器性能的开源工具,从下面的网址可以下载到最新版本的http_load: http://www.acme.com/software/http_load/ ...
- WebBench源码分析
源码分析共享地址:https://github.com/fivezh/WebBench 下载源码后编译源程序后即可执行: sudo make clean sudo make & make in ...
- 多渠道打包工具Walle源码分析
一.背景 首先了解多渠道打包工具Walle之前,我们需要先明确一个概念,什么是渠道包. 我们要知道在国内有无数大大小小的APP Store,每一个APP Store就是一个渠道.当我们把APP上传到A ...
- 移动web app开发必备 - Deferred 源码分析
姊妹篇 移动web app开发必备 - 异步队列 Deferred 在分析Deferred之前我觉得还是有必要把老套的设计模式给搬出来,便于理解源码! 观察者模式 观察者模式( 又叫发布者-订阅者模 ...
- bootstrap_栅格系统_响应式工具_源码分析
-----------------------------------------------------------------------------margin 为负 使盒子重叠 等高 等高 ...
- 云实例初始化工具cloud-init源码分析
源码分析 代码结构 cloud-init的代码结构如下: cloud-init ├── bash_completion # bash自动补全文件 │ └── cloud-init ├── Chan ...
随机推荐
- Python标准库笔记(7) — copy模块
copy-对象拷贝模块:提供了浅拷贝和深拷贝复制对象的功能, 分别对应模块中的两个函数 copy() 和 deepcopy(). 1.浅拷贝(Shallow Copies) copy() 创建的 浅拷 ...
- jQuery-对标签元素 文本操作-属性操作-文档的操作
一.对标签元素文本操作 1.1 对标签中内容的操作 // js var div1 = document.getElementById("div1"); div1.innerText ...
- 用Max导出Unity3D使用的FBX文件流程注解(转载)
http://www.cnblogs.com/wantnon/p/4564522.html 从max导出FBX到Unity,以下环节需要特别注意.1,单位设置 很多人在建模,动画的时候,默认的ma ...
- python基础--logging模块
很多程序都有记录日志的需求,并且日志中包含的信息即有正常的程序访问日志,还可能有错误.警告等信息输出,python的logging模块提供了标准的日志接口,你可以通过它存储各种格式的日志,loggin ...
- Isolate randomforest检测异常点的非监督方法
由于异常数据的两个特征(少且不同: few and different) 异常数据只占很少量; 异常数据特征值和正常数据差别很大. iTree的构成过程如下: l 随机选择一个属性Attr: l ...
- 基于RESTful API 设计用户权限控制
RESTful简述 本文是基于RESTful描述的,需要你对这个有初步的了解. RESTful是什么? Representational State Transfer,简称REST,是Roy Fiel ...
- 程序设计分层思想和DAO设计模式的开发
无论是一个应用程序项目还是一个Web项目,我们都可以按照分层思想进行程序设计.对于分层,当下最流行划分方式是:表现层+控制层+业务层+数据层.其中,业务层和数据层被统称为后台业务层,而表现层和控制层属 ...
- 静态链接库(lib)、动态链接库(dll)与动态链接库的导入库(lib)
静态链接库与动态链接库相对应.动态链接库的导入库不同于以上两种库. 1.静态链接库(lib) 程序编译一般需经编辑.编译.连接.加载和运行几个步骤.在我们的应用中,有一些公共代码是需要反复使用 ...
- CentOS7 64位下MySQL5.7安装与配置(YUM)转
安装环境:CentOS7 64位 MINI版,安装MySQL5.7 1.配置YUM源 在MySQL官网中下载YUM源rpm安装包:http://dev.mysql.com/downloads/repo ...
- PHP array_key_exists() 函数(判断某个数组中是否存在指定的 key)
定义和用法 array_key_exists() 函数判断某个数组中是否存在指定的 key,如果该 key 存在,则返回 true,否则返回 false. 语法 array_key_exists(ke ...