BS4爬取物价局房产备案价以及dataframe的操作来获取房价的信息分析
因为最近要买房子,然后对房市做了一些调研,发现套路极多。卖房子的顾问目前基本都是一派胡言能忽悠就忽悠,所以基本他们的话是不能信的。一个楼盘一次开盘基本上都是200-300套房子,数据量虽然不大,但是其实看一下也很烦要一页一页的翻,如果是在纸上的话,他们还不让你给带回去。所以就是在选一个价格楼层也合适的房子,基本上很不方便。但是幸运的是,合肥市的房子的所有的价格都在合肥是物价局上面公示出来了。所以这里考虑的就是先把房子的价格数据都给爬下来,然后分析房子的单价,总价来选个觉得最适合自己的房源。
这里涉及的技术点是这样
1. 发出post指令传入参数,获取url不变的分页网络信息
2. 解析网页的结构,用bs4去抓取自己需要的内容
3. 综合1,2两点编写完整的脚本代码,讲自己需要的房源的信息给爬取下来
4. pandas的对于dataframe的操作,选出适合自己的房子。
下面是操作步骤:
这里是我们要爬取的页面
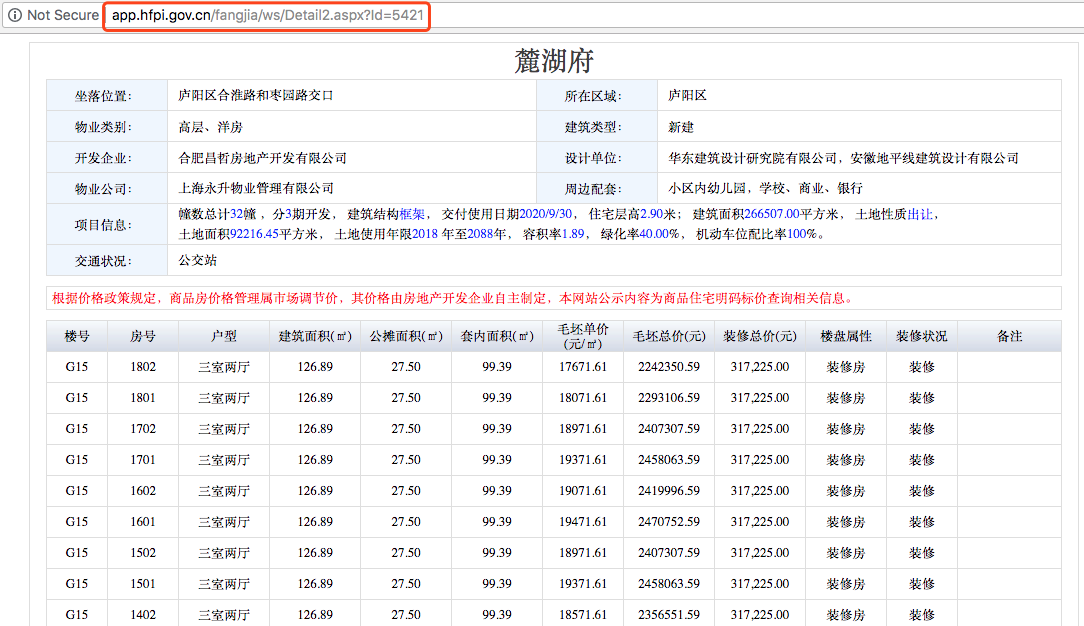
一共是15个分页,但是每个分页点进去的时候,url是没有变化的,也就是说我们没办法直接的通过更改url来访问页面。

打开Network,参数在这里,把他们用post请求发进去,就可以翻页了。
这时候我们需要找到我们需要爬取的数据的信息,看下网页的element,来定位到我们的数据信息
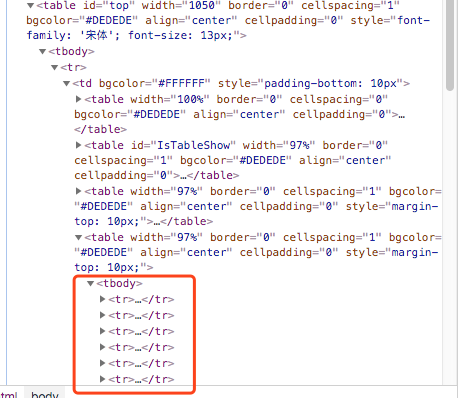
好像都在这里
那这个里面的子节点呢
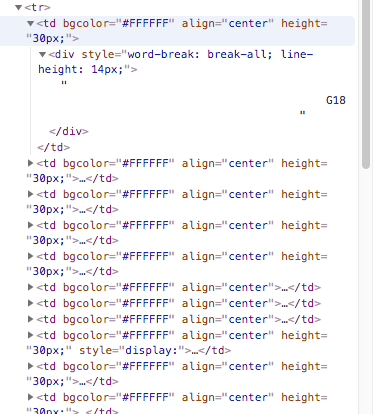
大概是这个样子。
下面是我写的爬虫:
# import libraray
import requests
import os
import pandas as pd
import re
from lxml import etree
from bs4 import BeautifulSoup # source url
url2 = "http://app.hfpi.gov.cn/fangjia/ws/Detail2.aspx?Id=5421"
headers = {"User-Agent":"Mozilla/5.0 (Macintosh; Intel Mac OS X 10_13_4) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/68.0.3440.106 Safari/537.36"} # 每次都更新下参数
def update_data_dict(soup):
data_dict['__VIEWSTATE'] = soup.find(id='__VIEWSTATE')['value']
data_dict['__EVENTTARGET'] = 'AspNetPager1'
data_dict['__EVENTARGUMENT'] += 1 #保存下来爬取的当页的数据
def save_data(soup):
x = soup('table',width='97%')
xx = x[2]
y = xx('tr') total = []
for item in y[1:-1]:
content1 = item('td')
empty = ''
for i in content1:
if i.find('div') == None:
continue
else:
infopiece = i.find('div').text.strip() + ' '
empty += infopiece
total.append(empty)
with open('result0.txt','a') as f:
for senc in total:
f.write(senc + '\n') # 接着去下一页继续爬
def get_next_page_data():
html2 = requests.post(url, data=data_dict).text
soup2 = BeautifulSoup(html2, 'lxml')
update_data_dict(soup2)
save_data(soup2) ## 现在开始爬取
html_jsy = requests.get(url2).text
soup_jsy = BeautifulSoup(html_jsy,'lxml')
save_data(soup_jsy)
update_data_dict(soup_jsy)
# 这里总页数我就设置20,如果后面没有了,也不会继续访问
for i in range(20):
get_next_page_data_2()
那么我们看下我们爬取的结果

美滋滋,数据我们拿下来了。
接着我们要开始读取数据开始分析了
import pandas as pd
df = pd.read_csv('result-jsy.txt', sep=' ',header=None)
#change column name
df.columns = ['BuildingNo','RmNo','Type','Area','ShareArea','RealArea','Price','totalPrice','','','','']
# 这次开盘只有16还有18, 先把16 18给选出来,然后合并
df_16 = df[df.BuildingNo =='G16']
df_18 = df[df.BuildingNo == 'G18']
p_list = [df_16,df_18]
df_temp = pd.concat(p_list)
因为这个楼盘有优惠,91折,所以单价我可以接受的范围我设置在14500
df_temp[df_temp.Price <= 14500.0]
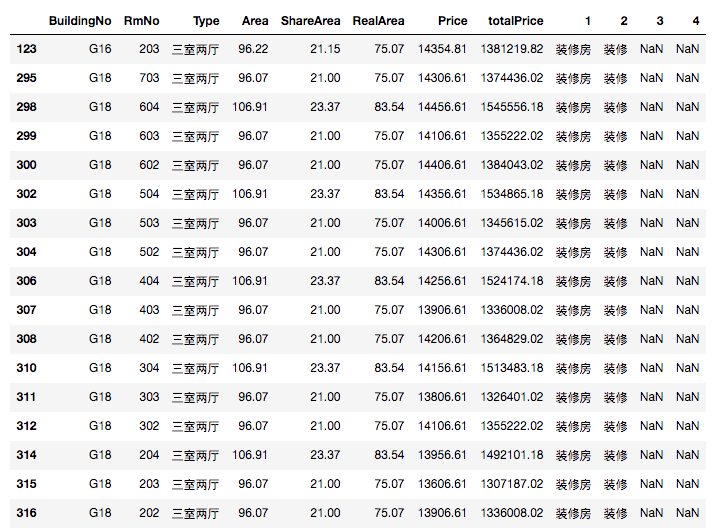
这里,我想住在5楼以上
df_select1[df_select1.RmNo > 500]

好吧,其实筛选就很简单了,这里因为明天就开盘了,所以首要就是看到价格然后楼层尽量高,
这里看,我的首选就是G18-703,但是上面其他的也都可以考虑。
BS4爬取物价局房产备案价以及dataframe的操作来获取房价的信息分析的更多相关文章
- python实战项目 — 使用bs4 爬取猫眼电影热榜(存入本地txt、以及存储数据库列表)
案例一: 重点: 1. 使用bs4 爬取 2. 数据写入本地 txt from bs4 import BeautifulSoup import requests url = "http:// ...
- 使用request+bs4爬取所有股票信息
爬取前戏 我们要知道利用selenium是非常无敌的,自我认为什么反爬不反爬都不在话下,但是今天我们为什么要用request+bs4爬取所有股票信息呢?因为他比较原始,因此今天的数据,爬取起来也是比较 ...
- BS4爬取糗百
-- coding: cp936 -- import urllib,urllib2 from bs4 import BeautifulSoup user_agent='Mozilla/5.0 (Win ...
- BS4爬取豆瓣电影
爬取豆瓣top250部电影 ####创建表: #connect.py from sqlalchemy import create_engine # HOSTNAME='localhost' # POR ...
- 针对源代码和检查元素不一致的网页爬虫——利用Selenium、PhantomJS、bs4爬取12306的列车途径站信息
整个程序的核心难点在于上次豆瓣爬虫针对的是静态网页,源代码和检查元素内容相同:而在12306的查找搜索过程中,其网页发生变化(出现了查找到的数据),这个过程是动态的,使得我们在审查元素中能一一对应看到 ...
- python使用bs4爬取boss静态页面
思路: 1.将需要查询城市列表,通过城市接口转换成相应的code码 2.遍历城市.职位生成url 3.通过url获取列表页面信息,遍历列表页面信息 4.再根据列表页面信息的job_link获取详情页面 ...
- python+selenium+bs4爬取百度文库内文字 && selenium 元素可以定位到,但是无法点击问题 && pycharm多行缩进、左移
先说一下可能用到的一些python知识 一.python中使用的是unicode编码, 而日常文本使用各类编码如:gbk utf-8 等等所以使用python进行文字读写操作时候经常会出现各种错误, ...
- bs4爬取笔趣阁小说
参考链接:https://www.cnblogs.com/wt714/p/11963497.html 模块:requests,bs4,queue,sys,time 步骤:给出URL--> 访问U ...
- requests+bs4爬取豌豆荚排行榜及下载排行榜app
爬取排行榜应用信息 爬取豌豆荚排行榜app信息 - app_detail_url - 应用详情页url - app_image_url - 应用图片url - app_name - 应用名称 - ap ...
随机推荐
- jquery正则表达式验证:验证身份证号码
需求说明: 前端页面使用正则表达式验证文本输入框输入的身份证号码是否符合规则. 代码说明: 这里只介绍正则表达式部分,其他部分的代码不做介绍.如有其它需求请自行修改即可. 步骤一:建立一个页面可以是h ...
- Linux indent命令
一.简介 indent可辨识C的原始代码文件,并加以格式化,以方便程序设计师阅读. 二.选项 http://www.cnblogs.com/xuxm2007/archive/2011/11/03/22 ...
- OpenSSL 结构体
X509_STORE 头文件:x509_vfy.h 定义 typedef struct x509_store_st X509_STORE; struct x509_store_st { /* The ...
- DNA motif 搜索算法总结
DNA motif 搜索算法总结 2011-09-15 ~ ADMIN 翻译自:A survey of DNA motif finding algorithms, Modan K Das et. al ...
- 模板练习(LUOGU)
1:并查集 P3183食物链 #define man 300050 ; int find(int x){ if(fa[x]==x) return fa[x]; return fa[x]=find(fa ...
- 如何处理好前后端分离的 API 问题(转载自知乎)
9 个月前 API 都搞不好,还怎么当程序员?如果 API 设计只是后台的活,为什么还需要前端工程师. 作为一个程序员,我讨厌那些没有文档的库.我们就好像在操纵一个黑盒一样,预期不了它的正常行为是什么 ...
- db2中如何获取当前日期前一周的日期
SELECT CURRENT_DATE - (DAYOFWEEK(CURRENT_DATE) - 2 + (ROW_NUMBER() OVER (ORDER BY 1) ) ) DAY AS resu ...
- HTML5/CSS3基础
1. HTML 1.1 什么是HTML HTML是用来制作网页的标记语言 HTML是Hypertext Markup Language的英文缩写,即超文本标记语言 HTML语言是一种标记语言,不需要编 ...
- 2018.08.09 bzoj4719: [Noip2016]天天爱跑步(树链剖分)
传送门 话说开始上文化课之后写题时间好少啊. 这道题将一个人的跑步路线拆成s->lca,lca->t,然后对于第一段上坡路径要经过的点,当前这个人能对它产生贡献当且仅当dep[s]-dep ...
- UVa 10340 All in All (水题,匹配)
题意:给定两个字符串,问第一个串能不能从第二个串通过删除0个或多个字符得到. 析:那就一个字符一个字符的匹配,如果匹配上了就往后走,判断最后是不是等于长度即可. 代码如下: #include < ...