HBase LSM树存储引擎详解
1.前提
讲LSM树之前,需要提下三种基本的存储引擎,这样才能清楚LSM树的由来:
- 哈希存储引擎。
- B树存储引擎。
- LSM树(Log-Structured Merge Tree)存储引擎。
2. 哈希存储引擎
哈希存储引擎哈希表的持久化实现,支持增、删、改以及随机读取操作,但不支持顺序扫描,对应的存储系统为key-value存储系统。对于key-value的插入以及查询,哈希表的复杂度都是O(1),明显比树的操作O(n)快,如果不需要有序的遍历数据,哈希表就非常适合。代表性的数据库有:Redis,Memcache,以及存储系统Bitcask。
举例Bitcask的哈希表数据结构为:
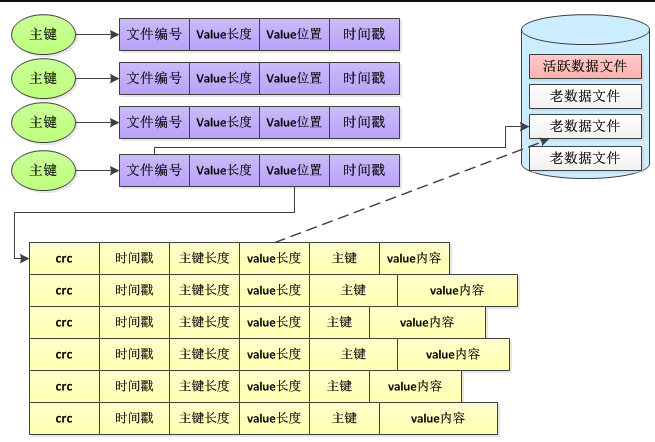
Bitcask数据文件中的数据是一条一条写入操作,记录包含key、value、主键长度、value长度、时间戳以及crc校验值。
数据库所在服务器在内存中采用基于哈希表的索引数据结构,哈希表的作用是通过主键快速地定位到value的位置。哈希表结构中的每一项包含了三个用于定位数据的信息,分别是文件编号(file id),value在文件中的位置(value_pos),value长度(value_sz),通过读取file_id对应文件的value_pos开始的value_sz个字节,这就得到了最终的value值。写入时首先将key-value记录追加到活跃数据文件的末尾,接着更新内存哈希表,因此,每个写操作总共需要进行一次顺序的磁盘写入和一次内存操作。
Bitcask在内存中存储了主键和value的索引信息,磁盘文件中存储了主键和value的实际内容。
3. B树存储引擎
相比哈希存储引擎,B树存储引擎不仅支持随机读取,还支持范围扫描。关系型数据库中通过索引访问数据,在Mysql InnoDB中,有一个称为聚集索引的特殊索引,行的数据存于其中,组织成B+树(B树的一种)数据结构。
B+树的数据结构:
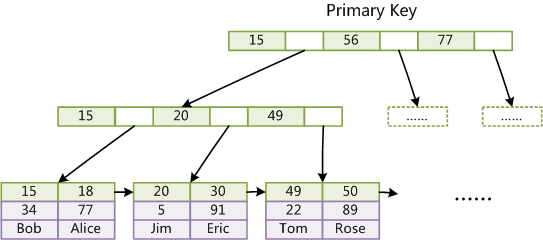
如图所示,MySQL InnoDB按照页面(Page)来组织数据,每个页面对应B+树的一个节点。其中,叶子节点保存每行的完整数据,非叶子节点保存索引信息。数据在每个节点中有序存储,数据库查询时需要从根节点开始二分查找直到叶子节点,每次读取一个节点,如果对应的页面不在内存中,需要从磁盘中读取并缓存起来。B+树的根节点是常驻内存的,因此,B+树一次检索最多需要h-1次磁盘IO,复杂度为O(h)=O(logdN)(N为元素个数,d为每个节点的出度,h为B+树高度)。修改操作首先需要记录提交日志,接着修改内存中的B+树。如果内存中的被修改过的页面超过一定的比率,后台线程会将这些页面刷到磁盘中持久化。
4. LSM树存储引擎
4.1 LSM主题思想
LSM-Tree主题思想为划分不同等级的数。可以想象一份索引由两棵树组成:一个存在于内存(可以使用其他树结构),一个存在于磁盘(如下图)。

LSM树的设计思想非常朴素:将对数据的修改增量保持在内存中,达到指定的大小限制后将这些修改操作批量写入磁盘,不过读取的时候稍微麻烦,需要合并磁盘中历史数据和内存中最近修改操作,所以写入性能大大提升,读取时可能需要先看是否命中内存,否则需要访问较多的磁盘文件。极端的来说,基于LSM树实现的HBase的写性能比Mysql高了一个数量级,读性能低了一个数量级。
数据首先会插入到内存中的树,为了防止数据丢失,写内存的同时需要暂时持久化到磁盘,即输入数据时数据会以完全有序的形式先存储在日志文件中(对应HBase的MemStore和HLog)。当日志文件被修改时,对应的更新会被先保存在内存中来加速查询。
当内存中树的数据达到阀值时,会进行合并操作。合并操作会从左至右遍历内存中的叶子节点与磁盘中树的叶子节点进行合并,当合并的数据量达到磁盘的存储页的大小时,会将合并的数据持久化到磁盘。同时更新父亲节点对叶子节点的指针(如下图)。
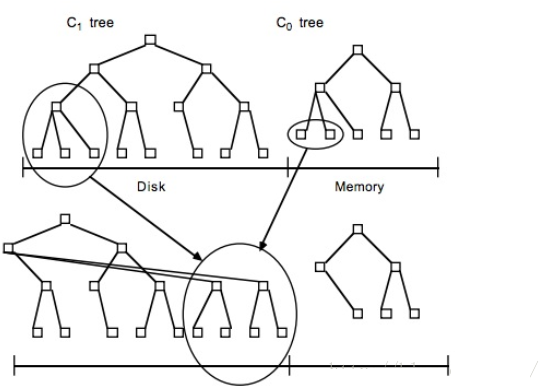
查找通过合并的方式完成,首先搜索内存存储结构,接下来是磁盘存储结构。
LSM树所有节点都是满的并按页存储,经过多次的flush会创建很多数据存储文件,后台线程会将小文件聚合成大文件,因此磁盘的寻道操作就会被限制在一定数目的数据存储文件中,以优化读性能。磁盘上的树结构也可以分割成多个存储文件,因为所有的存储数据都是按照Key有序排列的,因此在现有节点中插入新的关键字不需要重新排序。
LSM-Tree属于传输型,在磁盘传输速率上进行文件的排序和合并以及日志操作,可以更好的拓展到更大的数据规模上,因为它会使用日志文件和一个内存存储结构把随机写操作转化为顺序写,读写独立,不会产生两种操作的竞争。
4.2 LSM树在HBase中的应用
LSM树可以看成n层合并树。在HBase中,它把随机写转换成对MemStore和HFile的连续写。下图展示了LSM树数据写的过程。
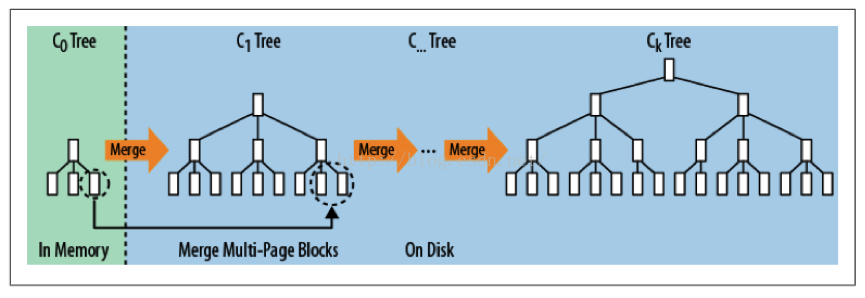
数据写(插入,更新):数据首先顺序写如HLog(WAL),然后写到MemStore,在MemStore中,数据是一个2层B+树(上图中的C0树)。MemStore满了之后,数据会被刷到StoreFile(HFile),在StoreFile中,数据是3层B+树(图2中的C1树),并针对顺序磁盘操作进行优化。
数据读:首先搜索MemStore,如果不再MemStore中,则到StoreFile中寻找。
数据删除:不会去删除磁盘上的数据,而是为数据添加一个删除标记。在随后的major compaction中,被删除的数据和删除标记才会真的被删除。
LSM数据更新只在内存中操作,没有磁盘访问,因此比B+树要快。对于数据读来说,如果读取的是最近访问过的数据,LSM树能减少磁盘访问,提高性能。
总结
参考资料:
https://blog.csdn.net/lifuxiangcaohui/article/details/39962921
https://blog.csdn.net/a_zhenzhen/article/details/78831866
https://blog.csdn.net/liuxiao723846/article/details/52971511
https://blog.csdn.net/u014432433/article/details/51557834
HBase LSM树存储引擎详解的更多相关文章
- MySQL数据库的各种存储引擎详解
原文来自:MySQL数据库的各种存储引擎详解 MySQL有多种存储引擎,每种存储引擎有各自的优缺点,大家可以择优选择使用: MyISAM.InnoDB.MERGE.MEMORY(HEAP).BDB ...
- Linux MySQL 存储引擎详解
MySQL常用的存储引擎为MyISAM.InnoDB.MEMORY.MERGE,其中InnoDB提供事务安全表,其他存储引擎都是非事务安全表. MyISAM是MySQL的默认存储引擎.MyISAM不支 ...
- 主流存储引擎详解:Innodb,Tokudb、Memory、MYISAM、Federated
主流存储引擎: Innodb:推荐使用,主力引擎,使用99%以上的场景 Tokudb:高速写入使用,日用量大量写入eg:500G可压缩为50G.适用于访问日志的写入,相对MYISAM有事务性,相对于I ...
- Mysql—存储引擎详解
存储引擎基本操作 查看数据库支持的所有的存储引擎 mysql> show engines; 查看数据库目前使用的引擎 mysql> show varlables like "%s ...
- MySQL基础篇(05):逻辑架构图解和InnoDB存储引擎详解
本文源码:GitHub·点这里 || GitEE·点这里 一.MySQL逻辑架构 1.逻辑架构图 基于下面的逻辑架构图,可以大致熟悉MySQL各个架构组件之间的协同工作关系. 很经典的C/S架构风格, ...
- MyIASM和Innodb引擎详解
MyIASM 和 Innodb引擎详解 Innodb引擎 Innodb引擎提供了对数据库ACID事务的支持,并且实现了SQL标准的四种隔离级别,关于数据库事务与其隔离级别的内容请见数据库事务与其隔离级 ...
- 如何查看mysql数据库的引擎/MySQL数据库引擎详解
一般情况下,mysql会默认提供多种存储引擎,你可以通过下面的查看: 看你的mysql现在已提供什么存储引擎:mysql> show engines; 看你的mysql当前默认的存储引擎:mys ...
- Kubernetes K8S之存储Volume详解
K8S之存储Volume概述与说明,并详解常用Volume示例 主机配置规划 服务器名称(hostname) 系统版本 配置 内网IP 外网IP(模拟) k8s-master CentOS7.7 2C ...
- AVL树平衡旋转详解
AVL树平衡旋转详解 概述 AVL树又叫做平衡二叉树.前言部分我也有说到,AVL树的前提是二叉排序树(BST或叫做二叉查找树).由于在生成BST树的过程中可能会出现线型树结构,比如插入的顺序是:1, ...
随机推荐
- python3.6+selenium3.13 自动化测试项目实战一
自己亲自写的第一个小项目,学了几天写出来的一个小模块,可能还不是很完美,但是还算可以了,初学者看看还是很有用的,代码注释不是很多,有问题可以加我QQ 281754043 一.项目介绍 目的: 测试某官 ...
- RocketMQ从3.5.8升级到4.3.2版本实战记录
背景 我们在很早之前大约在2015年8月份左右我们开始使用Rocketmq作为公司消息中间件,那个时候RocketMQ还没有捐赠给Acaphe. RocketMQ版本还是3.2.6,中间升级了一次版本 ...
- iis问题
1.8.5版本的iis配置完成,不能打开网页显示503.原因是应用程序池,加载用户配置文件失败,然后应用程序池关闭了.关闭它就可以正常打开了. server2008,打不开网页,打开url显示目录的原 ...
- Ant Design Pro+Electron+electron-builder实现React应用脱离浏览器,桌面安装运行
ant-design-pro ----> version :2.3.1 由于网上Ant Design Pro+Electron的资料太少,我就贡献一点经验 最近需要讲AntD Pro项目(以 ...
- 移动端左右滑动问题-html与css解决
<!DOCTYPE html> <html> <head> <title>纯css实现左右滑动</title> <style type ...
- 接口list
List接口介绍 java.util.List 接口继承自 Collection 接口,是单列集合的一个重要分支,习惯性地会将实现了 List 接口的对象称为List集合. List接口特点: 它是一 ...
- API简介
概述 API(Application Programming Interface),应用程序编程接口.Java API是一本程序员的 字典 ,是JDK中提供给我们使用的类的说明文档.这些类将底层的代码 ...
- 浅析RPC远程过程调用基本原理
在校期间大家都写过不少程序,比如写个hello world服务类,然后本地调用下,如下所示.这些程序的特点是服务消费方和服务提供方是本地调用关系. 而一旦踏入公司尤其是大型互联网公司就会发现,公司的系 ...
- java8 :: 用法 (JDK8 双冒号用法)
https://www.cnblogs.com/tietazhan/p/7486937.html
- nginx简单的命令
nginx -s reload|reopen|stop|quit #重新加载配置|重启|停止|退出 nginx nginx -t #测试配置是否有语法错误 nginx [-?hvVtq] [-s si ...