Scrapy中选择器的用法

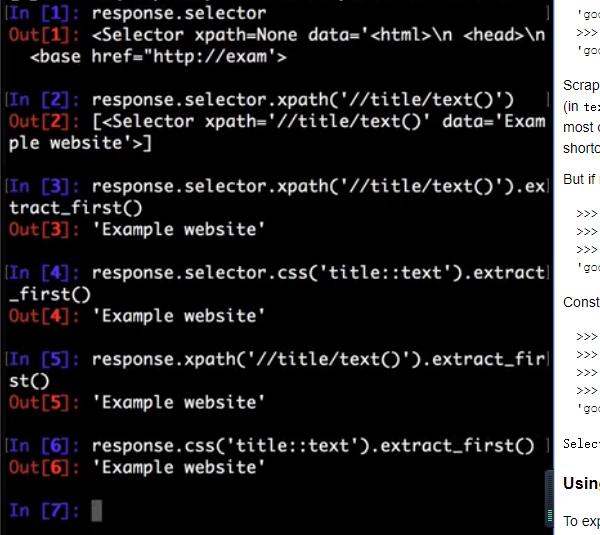




官方文档:https://doc.scrapy.org/en/latest/topics/selectors.html
Using selectors
Constructing selectors
Response objects expose a Selector instance on .selector attribute:
>>> response.selector.xpath('//span/text()').get()
'good'
Querying responses using XPath and CSS is so common that responses include two more shortcuts: response.xpath() and response.css():
>>> response.xpath('//span/text()').get()
'good'
>>> response.css('span::text').get()
'good'
Scrapy selectors are instances of Selector class constructed by passing either TextResponse object or markup as an unicode string (in text argument). Usually there is no need to construct Scrapy selectors manually: response object is available in Spider callbacks, so in most cases it is more convenient to use response.css() and response.xpath() shortcuts. By using response.selector or one of these shortcuts you can also ensure the response body is parsed only once.
But if required, it is possible to use Selector directly. Constructing from text:
>>> from scrapy.selector import Selector
>>> body = '<html><body><span>good</span></body></html>'
>>> Selector(text=body).xpath('//span/text()').get()
'good'
Constructing from response - HtmlResponse is one ofTextResponse subclasses:
>>> from scrapy.selector import Selector
>>> from scrapy.http import HtmlResponse
>>> response = HtmlResponse(url='http://example.com', body=body)
>>> Selector(response=response).xpath('//span/text()').get()
'good'
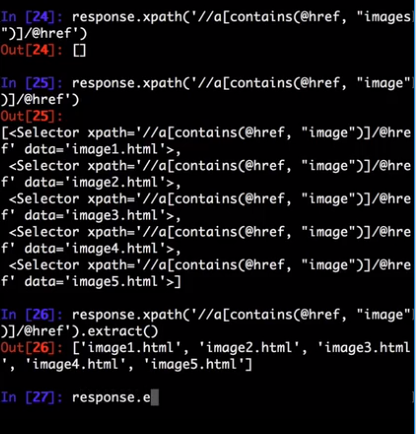
Selector automatically chooses the best parsing rules (XML vs HTML) based on input type.
Using selectors
To explain how to use the selectors we’ll use the Scrapy shell (which provides interactive testing) and an example page located in the Scrapy documentation server:
For the sake of completeness, here’s its full HTML code:
<html>
<head>
<base href='http://example.com/' />
<title>Example website</title>
</head>
<body>
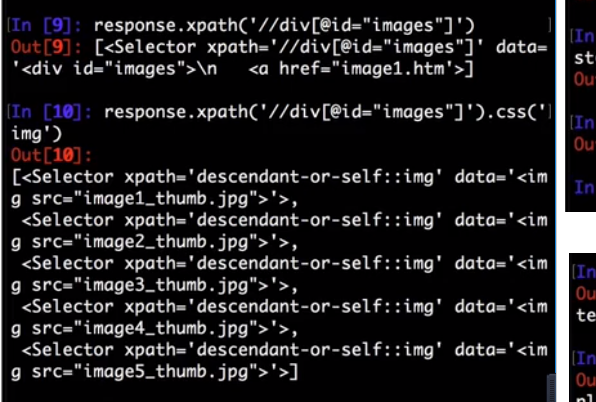
<div id='images'>
<a href='image1.html'>Name: My image 1 <br /><img src='image1_thumb.jpg' /></a>
<a href='image2.html'>Name: My image 2 <br /><img src='image2_thumb.jpg' /></a>
<a href='image3.html'>Name: My image 3 <br /><img src='image3_thumb.jpg' /></a>
<a href='image4.html'>Name: My image 4 <br /><img src='image4_thumb.jpg' /></a>
<a href='image5.html'>Name: My image 5 <br /><img src='image5_thumb.jpg' /></a>
</div>
</body>
</html>
First, let’s open the shell:
scrapy shell https://docs.scrapy.org/en/latest/_static/selectors-sample1.html
Then, after the shell loads, you’ll have the response available as response shell variable, and its attached selector in response.selector attribute.
Since we’re dealing with HTML, the selector will automatically use an HTML parser.
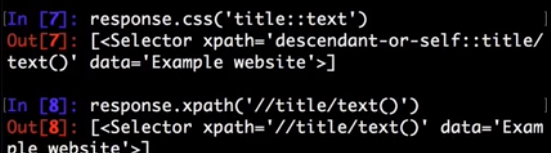
So, by looking at the HTML code of that page, let’s construct an XPath for selecting the text inside the title tag:
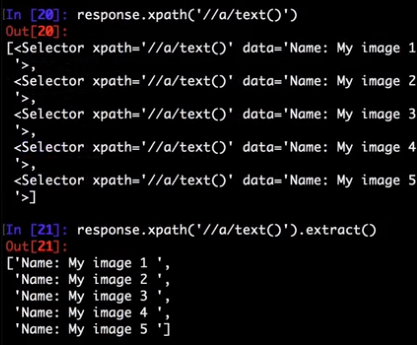
>>> response.xpath('//title/text()')
[<Selector xpath='//title/text()' data='Example website'>]
To actually extract the textual data, you must call the selector .get() or .getall() methods, as follows:
>>> response.xpath('//title/text()').getall()
['Example website']
>>> response.xpath('//title/text()').get()
'Example website'
.get() always returns a single result; if there are several matches, content of a first match is returned; if there are no matches, None is returned. .getall()returns a list with all results.
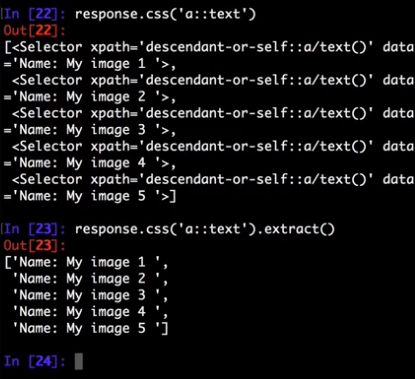
Notice that CSS selectors can select text or attribute nodes using CSS3 pseudo-elements:
>>> response.css('title::text').get()
'Example website'
As you can see, .xpath() and .css() methods return a SelectorList instance, which is a list of new selectors. This API can be used for quickly selecting nested data:
>>> response.css('img').xpath('@src').getall()
['image1_thumb.jpg',
'image2_thumb.jpg',
'image3_thumb.jpg',
'image4_thumb.jpg',
'image5_thumb.jpg']
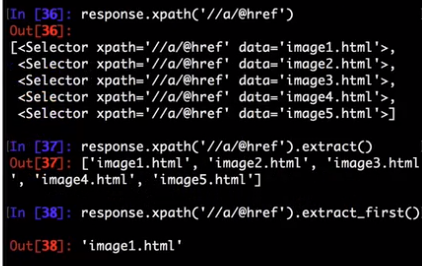
If you want to extract only the first matched element, you can call the selector .get() (or its alias .extract_first() commonly used in previous Scrapy versions):
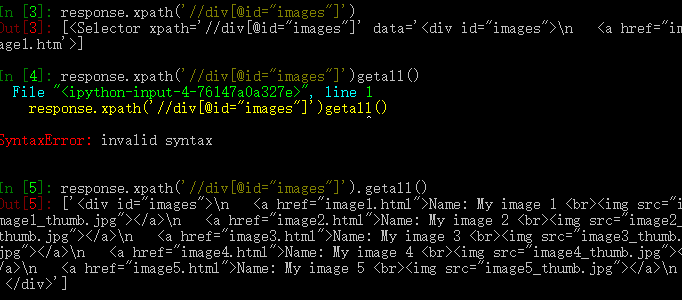
>>> response.xpath('//div[@id="images"]/a/text()').get()
'Name: My image 1 '
It returns None if no element was found:
>>> response.xpath('//div[@id="not-exists"]/text()').get() is None
True
A default return value can be provided as an argument, to be used instead of None:
>>> response.xpath('//div[@id="not-exists"]/text()').get(default='not-found')
'not-found'
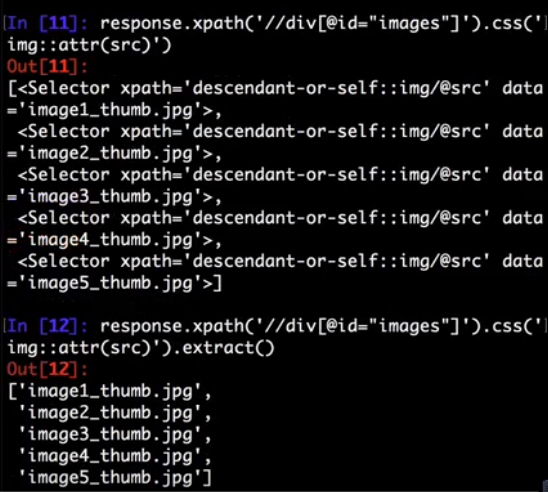
Instead of using e.g. '@src' XPath it is possible to query for attributes using .attrib property of a Selector:
>>> [img.attrib['src'] for img in response.css('img')]
['image1_thumb.jpg',
'image2_thumb.jpg',
'image3_thumb.jpg',
'image4_thumb.jpg',
'image5_thumb.jpg']
As a shortcut, .attrib is also available on SelectorList directly; it returns attributes for the first matching element:
>>> response.css('img').attrib['src']
'image1_thumb.jpg'
This is most useful when only a single result is expected, e.g. when selecting by id, or selecting unique elements on a web page:
>>> response.css('base').attrib['href']
'http://example.com/'
Now we’re going to get the base URL and some image links:
>>> response.xpath('//base/@href').get()
'http://example.com/'
>>> response.css('base::attr(href)').get()
'http://example.com/'
>>> response.css('base').attrib['href']
'http://example.com/'
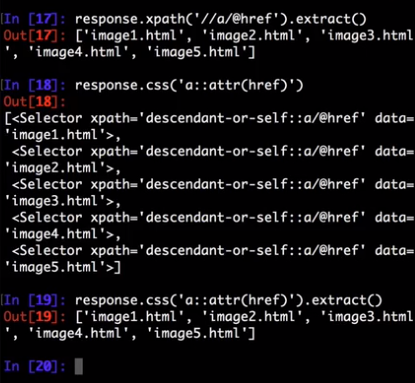
>>> response.xpath('//a[contains(@href, "image")]/@href').getall()
['image1.html',
'image2.html',
'image3.html',
'image4.html',
'image5.html']
>>> response.css('a[href*=image]::attr(href)').getall()
['image1.html',
'image2.html',
'image3.html',
'image4.html',
'image5.html']
>>> response.xpath('//a[contains(@href, "image")]/img/@src').getall()
['image1_thumb.jpg',
'image2_thumb.jpg',
'image3_thumb.jpg',
'image4_thumb.jpg',
'image5_thumb.jpg']
>>> response.css('a[href*=image] img::attr(src)').getall()
['image1_thumb.jpg',
'image2_thumb.jpg',
'image3_thumb.jpg',
'image4_thumb.jpg',
'image5_thumb.jpg']
Extensions to CSS Selectors
Per W3C standards, CSS selectors do not support selecting text nodes or attribute values. But selecting these is so essential in a web scraping context that Scrapy (parsel) implements a couple of non-standard pseudo-elements:
- to select text nodes, use
::text - to select attribute values, use
::attr(name)where name is the name of the attribute that you want the value of
Warning
These pseudo-elements are Scrapy-/Parsel-specific. They will most probably not work with other libraries like lxml or PyQuery.
Examples:
title::textselects children text nodes of a descendant<title>element:>>> response.css('title::text').get()
'Example website'*::textselects all descendant text nodes of the current selector context:>>> response.css('#images *::text').getall()
['\n ',
'Name: My image 1 ',
'\n ',
'Name: My image 2 ',
'\n ',
'Name: My image 3 ',
'\n ',
'Name: My image 4 ',
'\n ',
'Name: My image 5 ',
'\n ']foo::textreturns no results iffooelement exists, but contains no text (i.e. text is empty):>>> response.css('img::text').getall()
[]This means
.css('foo::text').get()could return None even if an element exists. Usedefault=''if you always want a string:>>> response.css('img::text').get()
>>> response.css('img::text').get(default='')
''a::attr(href)selects the href attribute value of descendant links:>>> response.css('a::attr(href)').getall()
['image1.html',
'image2.html',
'image3.html',
'image4.html',
'image5.html']
Note
See also: Selecting element attributes.
Note
You cannot chain these pseudo-elements. But in practice it would not make much sense: text nodes do not have attributes, and attribute values are string values already and do not have children nodes.
Nesting selectors
The selection methods (.xpath() or .css()) return a list of selectors of the same type, so you can call the selection methods for those selectors too. Here’s an example:
>>> links = response.xpath('//a[contains(@href, "image")]')
>>> links.getall()
['<a href="image1.html">Name: My image 1 <br><img src="data:image1_thumb.jpg"></a>',
'<a href="image2.html">Name: My image 2 <br><img src="data:image2_thumb.jpg"></a>',
'<a href="image3.html">Name: My image 3 <br><img src="data:image3_thumb.jpg"></a>',
'<a href="image4.html">Name: My image 4 <br><img src="data:image4_thumb.jpg"></a>',
'<a href="image5.html">Name: My image 5 <br><img src="data:image5_thumb.jpg"></a>']
>>> for index, link in enumerate(links):
... args = (index, link.xpath('@href').get(), link.xpath('img/@src').get())
... print('Link number %d points to url %r and image %r' % args)
Link number 0 points to url 'image1.html' and image 'image1_thumb.jpg'
Link number 1 points to url 'image2.html' and image 'image2_thumb.jpg'
Link number 2 points to url 'image3.html' and image 'image3_thumb.jpg'
Link number 3 points to url 'image4.html' and image 'image4_thumb.jpg'
Link number 4 points to url 'image5.html' and image 'image5_thumb.jpg'
Selecting element attributes
There are several ways to get a value of an attribute. First, one can use XPath syntax:
>>> response.xpath("//a/@href").getall()
['image1.html', 'image2.html', 'image3.html', 'image4.html', 'image5.html']
XPath syntax has a few advantages: it is a standard XPath feature, and @attributes can be used in other parts of an XPath expression - e.g. it is possible to filter by attribute value.
Scrapy also provides an extension to CSS selectors (::attr(...)) which allows to get attribute values:
>>> response.css('a::attr(href)').getall()
['image1.html', 'image2.html', 'image3.html', 'image4.html', 'image5.html']
In addition to that, there is a .attrib property of Selector. You can use it if you prefer to lookup attributes in Python code, without using XPaths or CSS extensions:
>>> [a.attrib['href'] for a in response.css('a')]
['image1.html', 'image2.html', 'image3.html', 'image4.html', 'image5.html']
This property is also available on SelectorList; it returns a dictionary with attributes of a first matching element. It is convenient to use when a selector is expected to give a single result (e.g. when selecting by element ID, or when selecting an unique element on a page):
>>> response.css('base').attrib
{'href': 'http://example.com/'}
>>> response.css('base').attrib['href']
'http://example.com/'
.attrib property of an empty SelectorList is empty:
>>> response.css('foo').attrib
{}
Using selectors with regular expressions
Selector also has a .re() method for extracting data using regular expressions. However, unlike using .xpath() or .css() methods, .re() returns a list of unicode strings. So you can’t construct nested .re()calls.
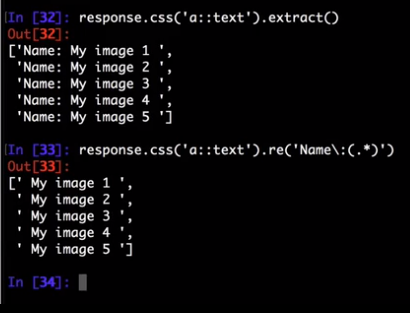
Here’s an example used to extract image names from the HTML code above:
>>> response.xpath('//a[contains(@href, "image")]/text()').re(r'Name:\s*(.*)')
['My image 1',
'My image 2',
'My image 3',
'My image 4',
'My image 5']
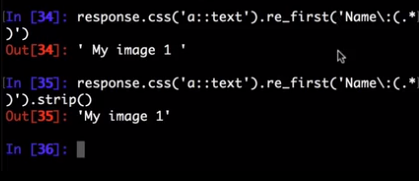
There’s an additional helper reciprocating .get()(and its alias .extract_first()) for .re(), named .re_first(). Use it to extract just the first matching string:
>>> response.xpath('//a[contains(@href, "image")]/text()').re_first(r'Name:\s*(.*)')
'My image 1'
extract() and extract_first()
If you’re a long-time Scrapy user, you’re probably familiar with .extract() and .extract_first()selector methods. Many blog posts and tutorials are using them as well. These methods are still supported by Scrapy, there are no plans to deprecate them.
However, Scrapy usage docs are now written using .get() and .getall() methods. We feel that these new methods result in a more concise and readable code.
The following examples show how these methods map to each other.
SelectorList.get()is the same asSelectorList.extract_first():>>> response.css('a::attr(href)').get()
'image1.html'
>>> response.css('a::attr(href)').extract_first()
'image1.html'SelectorList.getall()is the same asSelectorList.extract():>>> response.css('a::attr(href)').getall()
['image1.html', 'image2.html', 'image3.html', 'image4.html', 'image5.html']
>>> response.css('a::attr(href)').extract()
['image1.html', 'image2.html', 'image3.html', 'image4.html', 'image5.html']
Selector.get()is the same asSelector.extract():>>> response.css('a::attr(href)')[0].get()
'image1.html'
>>> response.css('a::attr(href)')[0].extract()
'image1.html'
For consistency, there is also
Selector.getall(), which returns a list:>>> response.css('a::attr(href)')[0].getall()
['image1.html']
So, the main difference is that output of .get() and .getall() methods is more predictable: .get()always returns a single result, .getall() always returns a list of all extracted results. With .extract()method it was not always obvious if a result is a list or not; to get a single result either .extract() or .extract_first() should be called.
Working with XPaths
Here are some tips which may help you to use XPath with Scrapy selectors effectively. If you are not much familiar with XPath yet, you may want to take a look first at this XPath tutorial.
Note
Some of the tips are based on this post from ScrapingHub’s blog.
Working with relative XPaths
Keep in mind that if you are nesting selectors and use an XPath that starts with /, that XPath will be absolute to the document and not relative to theSelector you’re calling it from.
For example, suppose you want to extract all <p>elements inside <div> elements. First, you would get all <div> elements:
>>> divs = response.xpath('//div')
At first, you may be tempted to use the following approach, which is wrong, as it actually extracts all <p> elements from the document, not only those inside <div> elements:
>>> for p in divs.xpath('//p'): # this is wrong - gets all <p> from the whole document
... print(p.get())
This is the proper way to do it (note the dot prefixing the .//p XPath):
>>> for p in divs.xpath('.//p'): # extracts all <p> inside
... print(p.get())
Another common case would be to extract all direct <p> children:
>>> for p in divs.xpath('p'):
... print(p.get())
For more details about relative XPaths see the Location Paths section in the XPath specification.
When querying by class, consider using CSS
Because an element can contain multiple CSS classes, the XPath way to select elements by class is the rather verbose:
*[contains(concat(' ', normalize-space(@class), ' '), ' someclass ')]
If you use @class='someclass' you may end up missing elements that have other classes, and if you just use contains(@class, 'someclass') to make up for that you may end up with more elements that you want, if they have a different class name that shares the string someclass.
As it turns out, Scrapy selectors allow you to chain selectors, so most of the time you can just select by class using CSS and then switch to XPath when needed:
>>> from scrapy import Selector
>>> sel = Selector(text='<div class="hero shout"><time datetime="2014-07-23 19:00">Special date</time></div>')
>>> sel.css('.shout').xpath('./time/@datetime').getall()
['2014-07-23 19:00']
This is cleaner than using the verbose XPath trick shown above. Just remember to use the . in the XPath expressions that will follow.
Beware of the difference between //node[1] and (//node)[1]
//node[1] selects all the nodes occurring first under their respective parents.
(//node)[1] selects all the nodes in the document, and then gets only the first of them.
Example:
>>> from scrapy import Selector
>>> sel = Selector(text="""
....: <ul class="list">
....: <li>1</li>
....: <li>2</li>
....: <li>3</li>
....: </ul>
....: <ul class="list">
....: <li>4</li>
....: <li>5</li>
....: <li>6</li>
....: </ul>""")
>>> xp = lambda x: sel.xpath(x).getall()
This gets all first <li> elements under whatever it is its parent:
>>> xp("//li[1]")
['<li>1</li>', '<li>4</li>']
And this gets the first <li> element in the whole document:
>>> xp("(//li)[1]")
['<li>1</li>']
This gets all first <li> elements under an <ul>parent:
>>> xp("//ul/li[1]")
['<li>1</li>', '<li>4</li>']
And this gets the first <li> element under an <ul>parent in the whole document:
>>> xp("(//ul/li)[1]")
['<li>1</li>']
Using text nodes in a condition
When you need to use the text content as argument to an XPath string function, avoid using .//text()and use just . instead.
This is because the expression .//text() yields a collection of text elements – a node-set. And when a node-set is converted to a string, which happens when it is passed as argument to a string function like contains() or starts-with(), it results in the text for the first element only.
Example:
>>> from scrapy import Selector
>>> sel = Selector(text='<a href="#">Click here to go to the <strong>Next Page</strong></a>')
Converting a node-set to string:
>>> sel.xpath('//a//text()').getall() # take a peek at the node-set
['Click here to go to the ', 'Next Page']
>>> sel.xpath("string(//a[1]//text())").getall() # convert it to string
['Click here to go to the ']
A node converted to a string, however, puts together the text of itself plus of all its descendants:
>>> sel.xpath("//a[1]").getall() # select the first node
['<a href="#">Click here to go to the <strong>Next Page</strong></a>']
>>> sel.xpath("string(//a[1])").getall() # convert it to string
['Click here to go to the Next Page']
So, using the .//text() node-set won’t select anything in this case:
>>> sel.xpath("//a[contains(.//text(), 'Next Page')]").getall()
[]
But using the . to mean the node, works:
>>> sel.xpath("//a[contains(., 'Next Page')]").getall()
['<a href="#">Click here to go to the <strong>Next Page</strong></a>']
Variables in XPath expressions
XPath allows you to reference variables in your XPath expressions, using the $somevariable syntax. This is somewhat similar to parameterized queries or prepared statements in the SQL world where you replace some arguments in your queries with placeholders like ?, which are then substituted with values passed with the query.
Here’s an example to match an element based on its “id” attribute value, without hard-coding it (that was shown previously):
>>> # `$val` used in the expression, a `val` argument needs to be passed
>>> response.xpath('//div[@id=$val]/a/text()', val='images').get()
'Name: My image 1 '
Here’s another example, to find the “id” attribute of a <div> tag containing five <a> children (here we pass the value 5 as an integer):
>>> response.xpath('//div[count(a)=$cnt]/@id', cnt=5).get()
'images'
All variable references must have a binding value when calling .xpath() (otherwise you’ll get a ValueError: XPath error: exception). This is done by passing as many named arguments as necessary.
parsel, the library powering Scrapy selectors, has more details and examples on XPath variables.
Removing namespaces
When dealing with scraping projects, it is often quite convenient to get rid of namespaces altogether and just work with element names, to write more simple/convenient XPaths. You can use theSelector.remove_namespaces() method for that.
Let’s show an example that illustrates this with the Python Insider blog atom feed.
First, we open the shell with the url we want to scrape:
$ scrapy shell https://feeds.feedburner.com/PythonInsider
This is how the file starts:
<?xml version="1.0" encoding="UTF-8"?>
<?xml-stylesheet ...
<feed xmlns="http://www.w3.org/2005/Atom"
xmlns:openSearch="http://a9.com/-/spec/opensearchrss/1.0/"
xmlns:blogger="http://schemas.google.com/blogger/2008"
xmlns:georss="http://www.georss.org/georss"
xmlns:gd="http://schemas.google.com/g/2005"
xmlns:thr="http://purl.org/syndication/thread/1.0"
xmlns:feedburner="http://rssnamespace.org/feedburner/ext/1.0">
...
You can see several namespace declarations including a default “http://www.w3.org/2005/Atom” and another one using the “gd:” prefix for “http://schemas.google.com/g/2005”.
Once in the shell we can try selecting all <link>objects and see that it doesn’t work (because the Atom XML namespace is obfuscating those nodes):
>>> response.xpath("//link")
[]
But once we call the Selector.remove_namespaces()method, all nodes can be accessed directly by their names:
>>> response.selector.remove_namespaces()
>>> response.xpath("//link")
[<Selector xpath='//link' data='<link rel="alternate" type="text/html" h'>,
<Selector xpath='//link' data='<link rel="next" type="application/atom+'>,
...
If you wonder why the namespace removal procedure isn’t always called by default instead of having to call it manually, this is because of two reasons, which, in order of relevance, are:
- Removing namespaces requires to iterate and modify all nodes in the document, which is a reasonably expensive operation to perform by default for all documents crawled by Scrapy
- There could be some cases where using namespaces is actually required, in case some element names clash between namespaces. These cases are very rare though.
Using EXSLT extensions
Being built atop lxml, Scrapy selectors support some EXSLT extensions and come with these pre-registered namespaces to use in XPath expressions:
| prefix | namespace | usage |
|---|---|---|
| re | http://exslt.org/regular-expressions | regular expressions |
| set | http://exslt.org/sets | set manipulation |
Regular expressions
The test() function, for example, can prove quite useful when XPath’s starts-with() or contains() are not sufficient.
Example selecting links in list item with a “class” attribute ending with a digit:
>>> from scrapy import Selector
>>> doc = u"""
... <div>
... <ul>
... <li class="item-0"><a href="link1.html">first item</a></li>
... <li class="item-1"><a href="link2.html">second item</a></li>
... <li class="item-inactive"><a href="link3.html">third item</a></li>
... <li class="item-1"><a href="link4.html">fourth item</a></li>
... <li class="item-0"><a href="link5.html">fifth item</a></li>
... </ul>
... </div>
... """
>>> sel = Selector(text=doc, type="html")
>>> sel.xpath('//li//@href').getall()
['link1.html', 'link2.html', 'link3.html', 'link4.html', 'link5.html']
>>> sel.xpath('//li[re:test(@class, "item-\d$")]//@href').getall()
['link1.html', 'link2.html', 'link4.html', 'link5.html']
>>>
Warning
C library libxslt doesn’t natively support EXSLT regular expressions so lxml’s implementation uses hooks to Python’s re module. Thus, using regexp functions in your XPath expressions may add a small performance penalty.
Set operations
These can be handy for excluding parts of a document tree before extracting text elements for example.
Example extracting microdata (sample content taken from http://schema.org/Product) with groups of itemscopes and corresponding itemprops:
>>> doc = u"""
... <div itemscope itemtype="http://schema.org/Product">
... <span itemprop="name">Kenmore White 17" Microwave</span>
... <img src="kenmore-microwave-17in.jpg" alt='Kenmore 17" Microwave' />
... <div itemprop="aggregateRating"
... itemscope itemtype="http://schema.org/AggregateRating">
... Rated <span itemprop="ratingValue">3.5</span>/5
... based on <span itemprop="reviewCount">11</span> customer reviews
... </div>
...
... <div itemprop="offers" itemscope itemtype="http://schema.org/Offer">
... <span itemprop="price">$55.00</span>
... <link itemprop="availability" href="http://schema.org/InStock" />In stock
... </div>
...
... Product description:
... <span itemprop="description">0.7 cubic feet countertop microwave.
... Has six preset cooking categories and convenience features like
... Add-A-Minute and Child Lock.</span>
...
... Customer reviews:
...
... <div itemprop="review" itemscope itemtype="http://schema.org/Review">
... <span itemprop="name">Not a happy camper</span> -
... by <span itemprop="author">Ellie</span>,
... <meta itemprop="datePublished" content="2011-04-01">April 1, 2011
... <div itemprop="reviewRating" itemscope itemtype="http://schema.org/Rating">
... <meta itemprop="worstRating" content = "1">
... <span itemprop="ratingValue">1</span>/
... <span itemprop="bestRating">5</span>stars
... </div>
... <span itemprop="description">The lamp burned out and now I have to replace
... it. </span>
... </div>
...
... <div itemprop="review" itemscope itemtype="http://schema.org/Review">
... <span itemprop="name">Value purchase</span> -
... by <span itemprop="author">Lucas</span>,
... <meta itemprop="datePublished" content="2011-03-25">March 25, 2011
... <div itemprop="reviewRating" itemscope itemtype="http://schema.org/Rating">
... <meta itemprop="worstRating" content = "1"/>
... <span itemprop="ratingValue">4</span>/
... <span itemprop="bestRating">5</span>stars
... </div>
... <span itemprop="description">Great microwave for the price. It is small and
... fits in my apartment.</span>
... </div>
... ...
... </div>
... """
>>> sel = Selector(text=doc, type="html")
>>> for scope in sel.xpath('//div[@itemscope]'):
... print("current scope:", scope.xpath('@itemtype').getall())
... props = scope.xpath('''
... set:difference(./descendant::*/@itemprop,
... .//*[@itemscope]/*/@itemprop)''')
... print(" properties: %s" % (props.getall()))
... print("") current scope: ['http://schema.org/Product']
properties: ['name', 'aggregateRating', 'offers', 'description', 'review', 'review'] current scope: ['http://schema.org/AggregateRating']
properties: ['ratingValue', 'reviewCount'] current scope: ['http://schema.org/Offer']
properties: ['price', 'availability'] current scope: ['http://schema.org/Review']
properties: ['name', 'author', 'datePublished', 'reviewRating', 'description'] current scope: ['http://schema.org/Rating']
properties: ['worstRating', 'ratingValue', 'bestRating'] current scope: ['http://schema.org/Review']
properties: ['name', 'author', 'datePublished', 'reviewRating', 'description'] current scope: ['http://schema.org/Rating']
properties: ['worstRating', 'ratingValue', 'bestRating'] >>>
Here we first iterate over itemscope elements, and for each one, we look for all itemprops elements and exclude those that are themselves inside another itemscope.
Other XPath extensions
Scrapy selectors also provide a sorely missed XPath extension function has-class that returns True for nodes that have all of the specified HTML classes.
For the following HTML:
<p class="foo bar-baz">First</p>
<p class="foo">Second</p>
<p class="bar">Third</p>
<p>Fourth</p>
You can use it like this:
>>> response.xpath('//p[has-class("foo")]')
[<Selector xpath='//p[has-class("foo")]' data='<p class="foo bar-baz">First</p>'>,
<Selector xpath='//p[has-class("foo")]' data='<p class="foo">Second</p>'>]
>>> response.xpath('//p[has-class("foo", "bar-baz")]')
[<Selector xpath='//p[has-class("foo", "bar-baz")]' data='<p class="foo bar-baz">First</p>'>]
>>> response.xpath('//p[has-class("foo", "bar")]')
[]
So XPath //p[has-class("foo", "bar-baz")] is roughly equivalent to CSS p.foo.bar-baz. Please note, that it is slower in most of the cases, because it’s a pure-Python function that’s invoked for every node in question whereas the CSS lookup is translated into XPath and thus runs more efficiently, so performance-wise its uses are limited to situations that are not easily described with CSS selectors.
Parsel also simplifies adding your own XPath extensions.
parsel.xpathfuncs.set_xpathfunc(fname, func)-
Register a custom extension function to use in XPath expressions.
The function
funcregistered underfnameidentifier will be called for every matching node, being passed acontextparameter as well as any parameters passed from the corresponding XPath expression.If
funcisNone, the extension function will be removed.See more in lxml documentation.
Built-in Selectors reference
Selector objects
- class
scrapy.selector.Selector(response=None, text=None, type=None, root=None, _root=None, **kwargs) -
An instance of
Selectoris a wrapper over response to select certain parts of its content.responseis anHtmlResponseor anXmlResponseobject that will be used for selecting and extracting data.textis a unicode string or utf-8 encoded text for cases when aresponseisn’t available. Usingtextandresponsetogether is undefined behavior.typedefines the selector type, it can be"html","xml"orNone(default).If
typeisNone, the selector automatically chooses the best type based onresponsetype (see below), or defaults to"html"in case it is used together withtext.If
typeisNoneand aresponseis passed, the selector type is inferred from the response type as follows:"html"forHtmlResponsetype"xml"forXmlResponsetype"html"for anything else
Otherwise, if
typeis set, the selector type will be forced and no detection will occur.xpath(query, namespaces=None, **kwargs)-
Find nodes matching the xpath
queryand return the result as aSelectorListinstance with all elements flattened. List elements implementSelectorinterface too.queryis a string containing the XPATH query to apply.namespacesis an optionalprefix: namespace-urimapping (dict) for additional prefixes to those registered withregister_namespace(prefix, uri). Contrary toregister_namespace(), these prefixes are not saved for future calls.Any additional named arguments can be used to pass values for XPath variables in the XPath expression, e.g.:
selector.xpath('//a[href=$url]', url="http://www.example.com")Note
For convenience, this method can be called as
response.xpath()
css(query)-
Apply the given CSS selector and return a
SelectorListinstance.queryis a string containing the CSS selector to apply.In the background, CSS queries are translated into XPath queries using cssselect library and run
.xpath()method.Note
For convenience, this method can be called as
response.css()
get()-
Serialize and return the matched nodes in a single unicode string. Percent encoded content is unquoted.
See also: extract() and extract_first()
attrib-
Return the attributes dictionary for underlying element.
See also: Selecting element attributes.
re(regex, replace_entities=True)-
Apply the given regex and return a list of unicode strings with the matches.
regexcan be either a compiled regular expression or a string which will be compiled to a regular expression usingre.compile(regex).By default, character entity references are replaced by their corresponding character (except for
&and<). Passingreplace_entitiesasFalseswitches off these replacements.
re_first(regex, default=None, replace_entities=True)-
Apply the given regex and return the first unicode string which matches. If there is no match, return the default value (
Noneif the argument is not provided).By default, character entity references are replaced by their corresponding character (except for
&and<). Passingreplace_entitiesasFalseswitches off these replacements.
register_namespace(prefix, uri)-
Register the given namespace to be used in this
Selector. Without registering namespaces you can’t select or extract data from non-standard namespaces. See Selector examples on XML response.
remove_namespaces()-
Remove all namespaces, allowing to traverse the document using namespace-less xpaths. See Removing namespaces.
__bool__()-
Return
Trueif there is any real content selected orFalseotherwise. In other words, the boolean value of aSelectoris given by the contents it selects.
getall()-
Serialize and return the matched node in a 1-element list of unicode strings.
This method is added to Selector for consistency; it is more useful with SelectorList. See also: extract() and extract_first()
SelectorList objects
- class
scrapy.selector.SelectorList -
The
SelectorListclass is a subclass of the builtinlistclass, which provides a few additional methods.xpath(xpath, namespaces=None, **kwargs)-
Call the
.xpath()method for each element in this list and return their results flattened as anotherSelectorList.queryis the same argument as the one inSelector.xpath()namespacesis an optionalprefix: namespace-urimapping (dict) for additional prefixes to those registered withregister_namespace(prefix, uri). Contrary toregister_namespace(), these prefixes are not saved for future calls.Any additional named arguments can be used to pass values for XPath variables in the XPath expression, e.g.:
selector.xpath('//a[href=$url]', url="http://www.example.com")
css(query)-
Call the
.css()method for each element in this list and return their results flattened as anotherSelectorList.queryis the same argument as the one inSelector.css()
getall()-
Call the
.get()method for each element is this list and return their results flattened, as a list of unicode strings.See also: extract() and extract_first()
get(default=None)-
Return the result of
.get()for the first element in this list. If the list is empty, return the default value.See also: extract() and extract_first()
re(regex, replace_entities=True)-
Call the
.re()method for each element in this list and return their results flattened, as a list of unicode strings.By default, character entity references are replaced by their corresponding character (except for
&and<. Passingreplace_entitiesasFalseswitches off these replacements.
re_first(regex, default=None, replace_entities=True)-
Call the
.re()method for the first element in this list and return the result in an unicode string. If the list is empty or the regex doesn’t match anything, return the default value (Noneif the argument is not provided).By default, character entity references are replaced by their corresponding character (except for
&and<. Passingreplace_entitiesasFalseswitches off these replacements.
attrib-
Return the attributes dictionary for the first element. If the list is empty, return an empty dict.
See also: Selecting element attributes.
Examples
Selector examples on HTML response
Here are some Selector examples to illustrate several concepts. In all cases, we assume there is already a Selector instantiated with a HtmlResponseobject like this:
sel = Selector(html_response)
Select all
<h1>elements from an HTML response body, returning a list ofSelectorobjects (ie. aSelectorListobject):sel.xpath("//h1")Extract the text of all
<h1>elements from an HTML response body, returning a list of unicode strings:sel.xpath("//h1").getall() # this includes the h1 tag
sel.xpath("//h1/text()").getall() # this excludes the h1 tagIterate over all
<p>tags and print their class attribute:for node in sel.xpath("//p"):
print(node.attrib['class'])
Selector examples on XML response
Here are some examples to illustrate concepts for Selector objects instantiated with an XmlResponseobject:
sel = Selector(xml_response)
Select all
<product>elements from an XML response body, returning a list ofSelectorobjects (ie. aSelectorListobject):sel.xpath("//product")Extract all prices from a Google Base XML feedwhich requires registering a namespace:
sel.register_namespace("g", "http://base.google.com/ns/1.0")
sel.xpath("//g:price").getall()
Scrapy中选择器的用法的更多相关文章
- Scrapy框架中选择器的用法【转】
Python爬虫从入门到放弃(十四)之 Scrapy框架中选择器的用法 请给作者点赞 --> 原文链接 Scrapy提取数据有自己的一套机制,被称作选择器(selectors),通过特定的Xpa ...
- scrapy框架中选择器的用法
scrapy框架中选择器的用法 Scrapy提取数据有自己的一套机制,被称作选择器(selectors),通过特定的Xpath或者CSS表达式来选择HTML文件的某个部分Xpath是专门在XML文件中 ...
- scrapy中选择器用法
一.Selector选择器介绍 python从网页中提取数据常用以下两种方法: lxml:基于ElementTree的XML解析库(也可以解析HTML),不是python的标准库 BeautifulS ...
- Python爬虫从入门到放弃(十四)之 Scrapy框架中选择器的用法
Scrapy提取数据有自己的一套机制,被称作选择器(selectors),通过特定的Xpath或者CSS表达式来选择HTML文件的某个部分Xpath是专门在XML文件中选择节点的语言,也可以用在HTM ...
- Python之爬虫(十六) Scrapy框架中选择器的用法
Scrapy提取数据有自己的一套机制,被称作选择器(selectors),通过特定的Xpath或者CSS表达式来选择HTML文件的某个部分Xpath是专门在XML文件中选择节点的语言,也可以用在HTM ...
- 三、Scrapy中选择器用法
官方示例源码<html> <head> <base href='http://example.com/' /> <title>Example web ...
- 4-----Scrapy框架中选择器的用法
Scrapy提取数据有自己的一套机制,被称作选择器(selectors),通过特定的Xpath或者CSS表达式来选择HTML文件的某个部分Xpath是专门在XML文件中选择节点的语言,也可以用在HTM ...
- 爬虫(十三):scrapy中pipeline的用法
当Item 在Spider中被收集之后,就会被传递到Item Pipeline中进行处理 每个item pipeline组件是实现了简单的方法的python类,负责接收到item并通过它执行一些行为, ...
- 爬虫(十二):scrapy中spiders的用法
Spider类定义了如何爬去某个网站,包括爬取的动作以及如何从网页内容中提取结构化的数据,总的来说spider就是定义爬取的动作以及分析某个网页 工作流程分析 以初始的URL初始化Request,并设 ...
随机推荐
- vue webpack打包背景图片
vue的背景图 和 img标签图大于10KB都不会转成base64处理,可以设置limit(不推荐),所以要设置一个公共路径,解决办法如下
- Flask的请求处理机制
在Flask的官方文档中是这样介绍Flask的: 对于Web应用,与客户端发送给服务器的数据交互至关重要.在Flask中由全局的request对象来提供这些信息 属性介绍 request.method ...
- MySQL 笔记整理(8.b) --事务到底是隔离还是不隔离的?
笔记记录自林晓斌(丁奇)老师的<MySQL实战45讲> (本篇内图片均来自丁奇老师的讲解,如有侵权,请联系我删除) 8.a) --事务到底是隔离还是不隔离的? 本周工作较忙,加上懒惰,拖更 ...
- python-IO编程,文件读写
一.文件读写 1.打开文件 函数:open(name[. mode[. buffering]]) 参数: name:必须:文件的文件名(全路径或执行文件的相对路径.)) mode:可选:对文件的读写模 ...
- Android破解学习之路(十一)—— 关于去更新
根据对话框的文字找到对应的对话框,设置visability 为gone 修改版本号,aptool 搜索http://,找到更新的地址,修改为127.0.0.0 搜索update,upgrade,ver ...
- 1.docker常用命令
1.启动交互式容器 $ docker run -i -t IMAGE /bin/bash -i --interactive=true|false 默认是false -t --tty=true|fals ...
- 【CentOS7】服务环境搭建
用了两天时间,完成了服务环境的搭建.记录下了搭建的过程,搭建细节并没有记录. 1.OpenSSH. (1)yum search ssh (2)yum install openssh-server (3 ...
- es6 Symbol类型
es6 新增了一个原始类型Symbol,代表独一无二的数据 javascript 原来有6中基本类型, Boolean ,String ,Object,Number, null , undefined ...
- 《Odoo开发指南》精选分享—第1章-开始使用Odoo开发(1)
引言 在进入Odoo开发之前,我们需要建立我们的开发环境,并学习它的基本管理任务. 在本章中,我们将学习如何设置工作环境,在这里我们将构建我们的Odoo应用程序.我们将学习如何设置Debian或Ubu ...
- 珍藏版Chrome插件送给你们,不仅是程序员必备
大家好,消失了几天我又满血复活归来了,最近这几天太忙了一直在加班工作,这不昨天又干到凌晨一点,今天早上七点就起来了,到现在还都没有休息,现在只剩半血了,不对应该说现在只能爬着走了,但是一想到几天没有更 ...