爬虫(十三):scrapy中pipeline的用法
当Item 在Spider中被收集之后,就会被传递到Item Pipeline中进行处理
每个item pipeline组件是实现了简单的方法的python类,负责接收到item并通过它执行一些行为,同时也决定此Item是否继续通过pipeline,或者被丢弃而不再进行处理
item pipeline的主要作用:
- 清理html数据
- 验证爬取的数据
- 去重并丢弃
- 讲爬取的结果保存到数据库中或文件中
编写自己的item pipeline
process_item(self,item,spider)
每个item piple组件是一个独立的pyhton类,必须实现以process_item(self,item,spider)方法
每个item pipeline组件都需要调用该方法,这个方法必须返回一个具有数据的dict,或者item对象,或者抛出DropItem异常,被丢弃的item将不会被之后的pipeline组件所处理
下面的方法也可以选择实现
open_spider(self,spider)
表示当spider被开启的时候调用这个方法
close_spider(self,spider)
当spider挂去年比时候这个方法被调用
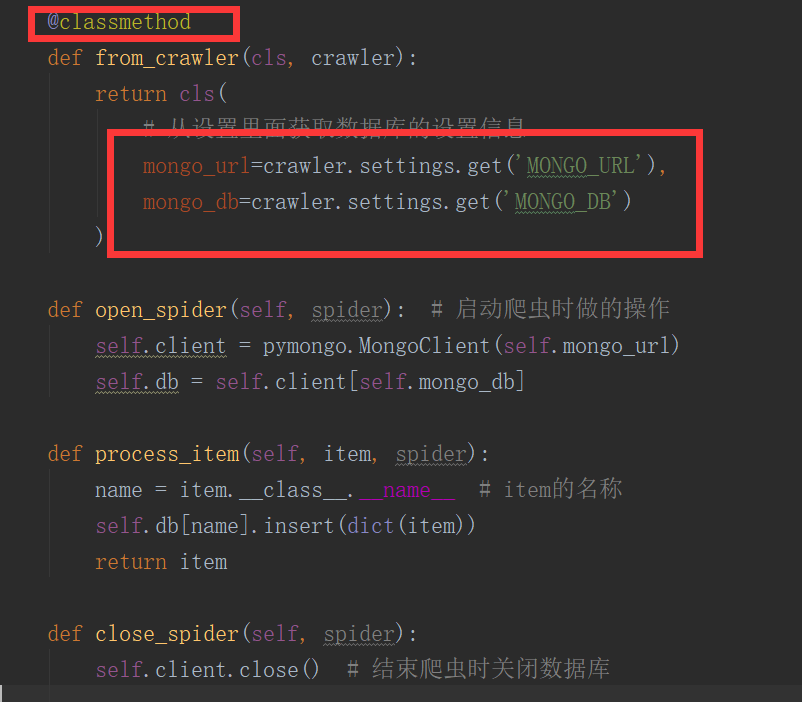
from_crawler(cls,crawler)
这个和我们在前面说spider的时候的用法是一样的,可以用于获取settings配置文件中的信息,需要注意的这个是一个类方法,用法例子如下:
一些item pipeline的使用例子(官网说明)
例子1
这个例子实现的是判断item中是否包含price以及price_excludes_vat,如果存在则调整了price属性,都让item['price'] = item['price'] * self.vat_factor,如果不存在则返回DropItem
from scrapy.exceptions import DropItem
class PricePipeline(object):
vat_factor = 1.15
def process_item(self, item, spider):
if item['price']:
if item['price_excludes_vat']:
item['price'] = item['price'] * self.vat_factor
return item
else:
raise DropItem("Missing price in %s" % item)
例子2
这个例子是将item写入到json文件中
import json
class JsonWriterPipeline(object):
def __init__(self):
self.file = open('items.jl', 'wb')
def process_item(self, item, spider):
line = json.dumps(dict(item)) + "\n"
self.file.write(line)
return item
例子3
将item写入到MongoDB,同时这里演示了from_crawler的用法
import pymongo
class MongoPipeline(object):
collection_name = 'scrapy_items'
def __init__(self, mongo_uri, mongo_db):
self.mongo_uri = mongo_uri
self.mongo_db = mongo_db
@classmethod
def from_crawler(cls, crawler):
return cls(
mongo_uri=crawler.settings.get('MONGO_URI'),
mongo_db=crawler.settings.get('MONGO_DATABASE', 'items')
)
def open_spider(self, spider):
self.client = pymongo.MongoClient(self.mongo_uri)
self.db = self.client[self.mongo_db]
def close_spider(self, spider):
self.client.close()
def process_item(self, item, spider):
self.db[self.collection_name].insert(dict(item))
return item
例子4:去重
一个用于去重的过滤器,丢弃那些已经被处理过的item,假设item有一个唯一的id,但是我们spider返回的多个item中包含了相同的id,去重方法如下:这里初始化了一个集合,每次判断id是否在集合中已经存在,从而做到去重的功能
from scrapy.exceptions import DropItem
class DuplicatesPipeline(object):
def __init__(self):
self.ids_seen = set()
def process_item(self, item, spider):
if item['id'] in self.ids_seen:
raise DropItem("Duplicate item found: %s" % item)
else:
self.ids_seen.add(item['id'])
return item
启用一个item Pipeline组件
在settings配置文件中y9ou一个ITEM_PIPELINES的配置参数,例子如下:
ITEM_PIPELINES = {
'myproject.pipelines.PricePipeline': 300,
'myproject.pipelines.JsonWriterPipeline': 800,
}
每个pipeline后面有一个数值,这个数组的范围是0-1000,这个数值确定了他们的运行顺序,数字越小越优先
爬虫(十三):scrapy中pipeline的用法的更多相关文章
- python爬虫之scrapy的pipeline的使用
scrapy的pipeline是一个非常重要的模块,主要作用是将return的items写入到数据库.文件等持久化模块,下面我们就简单的了解一下pipelines的用法. 案例一: items池 cl ...
- 爬虫(十二):scrapy中spiders的用法
Spider类定义了如何爬去某个网站,包括爬取的动作以及如何从网页内容中提取结构化的数据,总的来说spider就是定义爬取的动作以及分析某个网页 工作流程分析 以初始的URL初始化Request,并设 ...
- scrapy中pipeline的一点综合知识
初次学习scrapy ,觉得spider代码才是最重要的,越往后学,发现pipeline中的代码也很有趣, 今天顺便把pipeline中三种储存方法写下来,算是对自己学习的一点鼓励吧,也可以为后来者的 ...
- 爬虫(scrapy中的ImagesPipeline)
在使用ImagesPipeline对妹子图网站图片进行下载时,遇到302错误,页面被强制跳转. 解决办法如下: # -*- coding: utf-8 -*- # Define your item p ...
- 爬虫(scrapy中调试文件)
在项目setting同级目录下创建py文件,代码如下: from scrapy.cmdline import execute import sys import os sys.path.append( ...
- Scrapy中选择器的用法
官方文档:https://doc.scrapy.org/en/latest/topics/selectors.html Using selectors Constructing selectors R ...
- 18.scrapy中selector的用法
Selector是一个独立的模块. Selector主要是与scrapy结合使用的. 开启Scrapy shell: 1.打开命令行cmd 2.scrapy shell http://doc.scra ...
- scrapy中对于item的把控
其实很简单,就是想要存储的位置发生改变.直接看例子,然后触类旁通. 以大众点评 评论的内容为例 ,位置:http://www.dianping.com/shop/77489519/review_mor ...
- Python爬虫从入门到放弃(十七)之 Scrapy框架中Download Middleware用法
这篇文章中写了常用的下载中间件的用法和例子.Downloader Middleware处理的过程主要在调度器发送requests请求的时候以及网页将response结果返回给spiders的时候,所以 ...
随机推荐
- stm32f103的HSI设置
HSI基本知识 HSI是8MRC震荡电路,精度1%. PLL的设置必须在其被激活前完成,输出必须被设置温48M或者72M LSE:通过在备份域控制寄存器(RCC_BDCR)里的LSEON位启动和关闭. ...
- Spring中bean的管理
Spring 中常见的容器 我们知道spring容器就是spring中bean的驻留场所.spring容器并不是只有一个.spring自带了多个容器实现,可以归为两种不同的类型:bean工厂和应用上下 ...
- iOS - Scenekit3D引擎初探之 - 给材质贴图
今天简单说一下 SceneKit 给材质贴图. 1,最简单的一种方法,直接打开dae 或者 scn 文件直接设置 如上图,这个dae 文件中只有一个几何体,几何体中只有一个材质球,然后设置材质球的d ...
- day01-02
- js数组实现上移下移
up(index) { if(index === 0) { return } //在上一项插入该项 this.list.splice(index - 1, 0, (this.list[index])) ...
- iOS开发 CGAffineTransform 让图片旋转, 旋转后获得图片旋转的角度
1.让图片旋转 UIImageView *imageView = [[UIImageView alloc]init]; imageView.frame = CGRectMake(50, 50, 200 ...
- volatile和锁
让编译器不要将变量缓存到寄存器,而是每次去访问主板上的内存 可见性 对一个volatile变量的读,总是能看到(任意线程)对这个volatile变量最后的写入 原子性 对任意单个volatile变量的 ...
- iOS滤镜功能
一.iOS自带滤镜 1.CoreImage 使用苹果自带的CoreImage框架对图片进行处理,用CoreImage框架里的CIFilter对图片进行滤镜处理, 首先我们应该了解下CoreImage框 ...
- centos iptables 数据转发
iptables -t nat -I PREROUTING -p tcp --dport 3389 -j DNAT --to 38.X25.X.X02 iptables -t nat -I POSTR ...
- 版本控制系统(VCS)简介
简介 版本控制系统(VCS)是一种记录一个或若干文件内容变化,以便将来查阅特定版本修订情况的系统.使用版本控制系统通常还意味着,就算你乱来一气把整个项目中的文件改的改删的删,你也照样可以轻松恢复到原先 ...