【Spark篇】---SparkSQL中自定义UDF和UDAF,开窗函数的应用
一、前述
SparkSQL中的UDF相当于是1进1出,UDAF相当于是多进一出,类似于聚合函数。
开窗函数一般分组取topn时常用。
二、UDF和UDAF函数
1、UDF函数
java代码:
SparkConf conf = new SparkConf();
conf.setMaster("local");
conf.setAppName("udf");
JavaSparkContext sc = new JavaSparkContext(conf);
SQLContext sqlContext = new SQLContext(sc);
JavaRDD<String> parallelize = sc.parallelize(Arrays.asList("zhansan","lisi","wangwu"));
JavaRDD<Row> rowRDD = parallelize.map(new Function<String, Row>() { /**
*
*/
private static final long serialVersionUID = 1L; @Override
public Row call(String s) throws Exception {
return RowFactory.create(s);
}
}); List<StructField> fields = new ArrayList<StructField>();
fields.add(DataTypes.createStructField("name", DataTypes.StringType,true)); StructType schema = DataTypes.createStructType(fields);
DataFrame df = sqlContext.createDataFrame(rowRDD,schema);
df.registerTempTable("user"); /**
* 根据UDF函数参数的个数来决定是实现哪一个UDF UDF1,UDF2。。。。UDF1xxx
*/
sqlContext.udf().register("StrLen", new UDF1<String,Integer>() { /**
*
*/
private static final long serialVersionUID = 1L; @Override
public Integer call(String t1) throws Exception {
return t1.length();
}
}, DataTypes.IntegerType);
sqlContext.sql("select name ,StrLen(name) as length from user").show(); //sqlContext.udf().register("StrLen",new UDF2<String, Integer, Integer>() {
//
// /**
// *
// */
// private static final long serialVersionUID = 1L;
//
// @Override
// public Integer call(String t1, Integer t2) throws Exception {
//return t1.length()+t2;
// }
//} ,DataTypes.IntegerType );
//sqlContext.sql("select name ,StrLen(name,10) as length from user").show(); sc.stop();
这些参数需要对应,UDF2就是表示传两个参数,UDF3就是传三个参数。
scala代码:
val conf = new SparkConf()
conf.setMaster("local").setAppName("udf")
val sc = new SparkContext(conf)
val sqlContext = new SQLContext(sc);
val rdd = sc.makeRDD(Array("zhansan","lisi","wangwu"))
val rowRDD = rdd.map { x => {
RowFactory.create(x)
} }
val schema = DataTypes.createStructType(Array(StructField("name",StringType,true)))
val df = sqlContext.createDataFrame(rowRDD, schema)
df.registerTempTable("user")
//sqlContext.udf.register("StrLen",(s : String)=>{s.length()})
//sqlContext.sql("select name ,StrLen(name) as length from user").show
sqlContext.udf.register("StrLen",(s : String,i:Int)=>{s.length()+i})
sqlContext.sql("select name ,StrLen(name,10) as length from user").show
sc.stop()
2、UDAF:用户自定义聚合函数。
- 实现UDAF函数如果要自定义类要继承UserDefinedAggregateFunction类
package com.spark.sparksql.udf_udaf; import java.util.ArrayList;
import java.util.Arrays;
import java.util.List; import org.apache.spark.SparkConf;
import org.apache.spark.api.java.JavaRDD;
import org.apache.spark.api.java.JavaSparkContext;
import org.apache.spark.api.java.function.Function;
import org.apache.spark.sql.DataFrame;
import org.apache.spark.sql.Row;
import org.apache.spark.sql.RowFactory;
import org.apache.spark.sql.SQLContext;
import org.apache.spark.sql.expressions.MutableAggregationBuffer;
import org.apache.spark.sql.expressions.UserDefinedAggregateFunction;
import org.apache.spark.sql.types.DataType;
import org.apache.spark.sql.types.DataTypes;
import org.apache.spark.sql.types.StructField;
import org.apache.spark.sql.types.StructType;
/**
* UDAF 用户自定义聚合函数
* @author root
*
*/
public class UDAF {
public static void main(String[] args) {
SparkConf conf = new SparkConf();
conf.setMaster("local").setAppName("udaf");
JavaSparkContext sc = new JavaSparkContext(conf);
SQLContext sqlContext = new SQLContext(sc);
JavaRDD<String> parallelize = sc.parallelize(
Arrays.asList("zhangsan","lisi","wangwu","zhangsan","zhangsan","lisi"));
JavaRDD<Row> rowRDD = parallelize.map(new Function<String, Row>() { /**
*
*/
private static final long serialVersionUID = 1L; @Override
public Row call(String s) throws Exception {
return RowFactory.create(s);
}
}); List<StructField> fields = new ArrayList<StructField>();
fields.add(DataTypes.createStructField("name", DataTypes.StringType, true));
StructType schema = DataTypes.createStructType(fields);
DataFrame df = sqlContext.createDataFrame(rowRDD, schema);
df.registerTempTable("user");
/**
* 注册一个UDAF函数,实现统计相同值得个数
* 注意:这里可以自定义一个类继承UserDefinedAggregateFunction类也是可以的
*/
sqlContext.udf().register("StringCount",new UserDefinedAggregateFunction() { /**
*
*/
private static final long serialVersionUID = 1L; /**
* 初始化一个内部的自己定义的值,在Aggregate之前每组数据的初始化结果
*/
@Override
public void initialize(MutableAggregationBuffer buffer) {
buffer.update(0, 0);
} /**
* 更新 可以认为一个一个地将组内的字段值传递进来 实现拼接的逻辑
* buffer.getInt(0)获取的是上一次聚合后的值
* 相当于map端的combiner,combiner就是对每一个map task的处理结果进行一次小聚合
* 大聚和发生在reduce端.
* 这里即是:在进行聚合的时候,每当有新的值进来,对分组后的聚合如何进行计算
*/
@Override
public void update(MutableAggregationBuffer buffer, Row arg1) {
buffer.update(0, buffer.getInt(0)+1); }
/**
* 合并 update操作,可能是针对一个分组内的部分数据,在某个节点上发生的 但是可能一个分组内的数据,会分布在多个节点上处理
* 此时就要用merge操作,将各个节点上分布式拼接好的串,合并起来
* buffer1.getInt(0) : 大聚合的时候 上一次聚合后的值
* buffer2.getInt(0) : 这次计算传入进来的update的结果
* 这里即是:最后在分布式节点完成后需要进行全局级别的Merge操作
* 也可以是一个节点里面的多个executor合并
*/
@Override
public void merge(MutableAggregationBuffer buffer1, Row buffer2) {
buffer1.update(0, buffer1.getInt(0) + buffer2.getInt(0));
}
/**
* 在进行聚合操作的时候所要处理的数据的结果的类型
*/
@Override
public StructType bufferSchema() {
return DataTypes.createStructType(Arrays.asList(DataTypes.createStructField("bffer111", DataTypes.IntegerType, true)));
}
/**
* 最后返回一个和DataType的类型要一致的类型,返回UDAF最后的计算结果
*/
@Override
public Object evaluate(Row row) {
return row.getInt(0);
}
/**
* 指定UDAF函数计算后返回的结果类型
*/
@Override
public DataType dataType() {
return DataTypes.IntegerType;
}
/**
* 指定输入字段的字段及类型
*/
@Override
public StructType inputSchema() {
return DataTypes.createStructType(Arrays.asList(DataTypes.createStructField("nameeee", DataTypes.StringType, true)));
}
/**
* 确保一致性 一般用true,用以标记针对给定的一组输入,UDAF是否总是生成相同的结果。
*/
@Override
public boolean deterministic() {
return true;
} }); sqlContext.sql("select name ,StringCount(name) as strCount from user group by name").show(); sc.stop();
}
}

三、开窗函数
row_number() 开窗函数是按照某个字段分组,然后取另一字段的前几个的值,相当于 分组取topN
如果SQL语句里面使用到了开窗函数,那么这个SQL语句必须使用HiveContext来执行,HiveContext默认情况下在本地无法创建。
开窗函数格式:
row_number() over (partitin by XXX order by XXX)
package com.spark.sparksql.windowfun; import org.apache.spark.SparkConf;
import org.apache.spark.api.java.JavaSparkContext;
import org.apache.spark.sql.DataFrame;
import org.apache.spark.sql.SaveMode;
import org.apache.spark.sql.hive.HiveContext; /**是hive的函数,必须在集群中运行。
* row_number()开窗函数:
* 主要是按照某个字段分组,然后取另一字段的前几个的值,相当于 分组取topN
* row_number() over (partition by xxx order by xxx desc) xxx
* 注意:
* 如果SQL语句里面使用到了开窗函数,那么这个SQL语句必须使用HiveContext来执行,HiveContext默认情况下在本地无法创建
* @author root
*
*/
public class RowNumberWindowFun {
public static void main(String[] args) {
SparkConf conf = new SparkConf();
conf.setAppName("windowfun");
JavaSparkContext sc = new JavaSparkContext(conf);
HiveContext hiveContext = new HiveContext(sc);
hiveContext.sql("use spark");
hiveContext.sql("drop table if exists sales");
hiveContext.sql("create table if not exists sales (riqi string,leibie string,jine Int) "
+ "row format delimited fields terminated by '\t'");
hiveContext.sql("load data local inpath '/root/test/sales' into table sales");
/**
* 开窗函数格式:
* 【 row_number() over (partition by XXX order by XXX) as rank】//起个别名
* 注意:rank 从1开始
*/
/**
* 以类别分组,按每种类别金额降序排序,显示 【日期,种类,金额】 结果,如:
*
* 1 A 100
* 2 B 200
* 3 A 300
* 4 B 400
* 5 A 500
* 6 B 600
* 排序后:
* 5 A 500 --rank 1
* 3 A 300 --rank 2
* 1 A 100 --rank 3
* 6 B 600 --rank 1
* 4 B 400 --rank 2
* 2 B 200 --rank 3
*
*/
DataFrame result = hiveContext.sql("select riqi,leibie,jine "
+ "from ("
+ "select riqi,leibie,jine,"
+ "row_number() over (partition by leibie order by jine desc) rank "
+ "from sales) t "
+ "where t.rank<=3");
result.show(100);
/**
* 将结果保存到hive表sales_result
*/
result.write().mode(SaveMode.Overwrite).saveAsTable("sales_result");
sc.stop();
}
}
scala代码:
val conf = new SparkConf()
conf.setAppName("windowfun")
val sc = new SparkContext(conf)
val hiveContext = new HiveContext(sc)
hiveContext.sql("use spark");
hiveContext.sql("drop table if exists sales");
hiveContext.sql("create table if not exists sales (riqi string,leibie string,jine Int) "
+ "row format delimited fields terminated by '\t'");
hiveContext.sql("load data local inpath '/root/test/sales' into table sales");
/**
* 开窗函数格式:
* 【 rou_number() over (partitin by XXX order by XXX) 】
*/
val result = hiveContext.sql("select riqi,leibie,jine "
+ "from ("
+ "select riqi,leibie,jine,"
+ "row_number() over (partition by leibie order by jine desc) rank "
+ "from sales) t "
+ "where t.rank<=3");
result.show();
sc.stop()
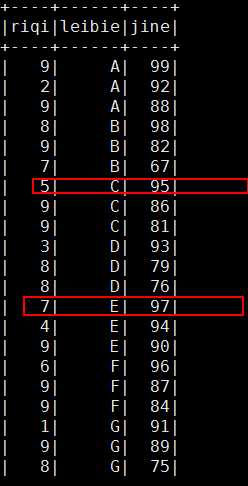
可以看到组内有序组间并不是有序的
【Spark篇】---SparkSQL中自定义UDF和UDAF,开窗函数的应用的更多相关文章
- 【Spark篇】---SparkSql之UDF函数和UDAF函数
一.前述 SparkSql中自定义函数包括UDF和UDAF UDF:一进一出 UDAF:多进一出 (联想Sum函数) 二.UDF函数 UDF:用户自定义函数,user defined functio ...
- Hive UDF IP解析(二):使用geoip2数据库自定义UDF
开发中经常会碰到将IP转为地域的问题,所以以下记录Hive中自定义UDF来解析IP. 使用到的地域库位maxmind公司的geoIP2数据库,分为免费版GeoLite2-City.mmdb和收费版Ge ...
- Spark(十三)【SparkSQL自定义UDF/UDAF函数】
目录 一.UDF(一进一出) 二.UDAF(多近一出) spark2.X 实现方式 案例 ①继承UserDefinedAggregateFunction,实现其中的方法 ②创建函数对象,注册函数,在s ...
- Spark(十三)SparkSQL的自定义函数UDF与开窗函数
一 自定义函数UDF 在Spark中,也支持Hive中的自定义函数.自定义函数大致可以分为三种: UDF(User-Defined-Function),即最基本的自定义函数,类似to_char,to_ ...
- SparkSQL中的自定义函数UDF
在Spark中,也支持Hive中的自定义函数.自定义函数大致可以分为三种: UDF(User-Defined-Function),即最基本的自定义函数,类似to_char,to_date等 UDAF( ...
- Spark SQL中UDF和UDAF
转载自:https://blog.csdn.net/u012297062/article/details/52227909 UDF: User Defined Function,用户自定义的函数,函数 ...
- Spark SQL 用户自定义函数UDF、用户自定义聚合函数UDAF 教程(Java踩坑教学版)
在Spark中,也支持Hive中的自定义函数.自定义函数大致可以分为三种: UDF(User-Defined-Function),即最基本的自定义函数,类似to_char,to_date等 UDAF( ...
- Spark(Hive) SQL中UDF的使用(Python)
相对于使用MapReduce或者Spark Application的方式进行数据分析,使用Hive SQL或Spark SQL能为我们省去不少的代码工作量,而Hive SQL或Spark SQL本身内 ...
- Kafka:ZK+Kafka+Spark Streaming集群环境搭建(十五)Spark编写UDF、UDAF、Agg函数
Spark Sql提供了丰富的内置函数让开发者来使用,但实际开发业务场景可能很复杂,内置函数不能够满足业务需求,因此spark sql提供了可扩展的内置函数. UDF:是普通函数,输入一个或多个参数, ...
随机推荐
- bower 基础认识
bower 跟 npm 很像 都是管理包的工具 只是 bower 偏向前端 npm 前后都能管理 npm init 后是 生产 package.json 下载的包在node_modules文件下 ...
- 第二次作业-熟悉git
GIT地址 https://github.com/gentlemanzq/yunsuanhomework GIT用户名 gentlemanzq 学号后五位 62320 博客地址 https://w ...
- quartz之CronExpression表达式
一个cron表达式有至少6个(也可能7个)有空格分隔的时间元素.按顺序依次为1.秒(~).分钟(~).小时(~).天(月)(~,但是你需要考虑你月的天数).月(~).天(星期)(~ =SUN 或 SU ...
- ios 上下滑动粘滞问题
ios 移动端,当你触及到可以左右滑动部分,进行上下滑动操作时,会导致上下滑动粘滞卡顿的问题 mdn:https://developer.mozilla.org/zh-CN/docs/Web/CSS/ ...
- mongodb4.0支持事务
事务特性: 原子性:所有的改变都完成一致性:最终执行结果一致就行隔离性:一个事务的执行不能其它事务干扰.持久性:指一个事务一旦提交,数据不会改变,存在数据库中 exports.getSession = ...
- SpringBoot加Poi仿照EasyPoi实现Excel导出
POI提供API给Java程序对Microsoft Office格式档案读和写的功能,详细功能可以直接查阅API,因为使用EasyPoi过程中总是缺少依赖,没有搞明白到底是什么坑,索性自己写一个简单工 ...
- BZOJ5316 : [Jsoi2018]绝地反击
若$R=0$,那么显然答案为离原点最远的点到原点的距离. 否则若所有点都在原点,那么显然答案为$R$. 否则考虑二分答案$mid$,检查$mid$是否可行. 那么每个点根据对应圆交,可以覆盖圆上的一部 ...
- C\C++ 内存对齐现象
前几天一个在自学C语言的小伙伴问了我个问题,C语言结构体储存所占空间为啥和自己预测的不一样.看一下下面这一段代码: struct node{ int num; char ch; }a; printf( ...
- Vue.set() this.$set()引发的视图更新思考
引文 vue文档列表渲染中有条注意事项: 这里提到的两种情况实际改变了数据但是没有触发视图更新. 由此引出Vue.set(),先上文档API: this.$set()和Vue.set()本质方法一样, ...
- RequireJS简单实用说明
OM前端框架说明 om前端框架采用RequireJS,RequireJS 是一个JavaScript模块加载器.它非常适合在浏览器中使用, 它非常适合在浏览器中使用,但它也可以用在其他脚本环境, 就 ...