对于Linux内核执行过程的理解(基于fork、execve、schedule等函数)
382 + 原创作品转载请注明出处 + https://github.com/mengning/linuxkernel/
一、实验环境
win10 -> VMware -> Ubuntu16.04 + GDB -> QEMU -> linux-3.9.4 + MenuOS
二、实验目的
1、理解Linux内核中创建一个进程的过程;
2、理解Linux内核加载可执行程序的过程;
3、理解Linux内核中的进程调度时机以及进程切换过程。
三、实验过程及结果
1、对于Linux内核中进程创建过程的理解
对于每个进程来说,都有其对应的进程控制块(PCB),在内核文件中,对于PCB结构体【task_struct】的定义比较复杂,包含的参数众多,这里就不详细进行解读【具体的定义存放于:/linux-3.9.4/inlude/sched.h】,一般情况下进程控制块中的信息都会包含进程状态、进程堆栈栈顶指针、进程唯一标识符、进程相关的链表指针等信息。
接下来是基于fork函数来理解内核的进程创建过程。进程的创建,大体上是将父进程的信息复制给子进程,子进程再对一些参数进行针对性的修改。如果想要创建一个进程的话,大致可以通过四种方式进行创建,分别是fork、vfork、clone三个系统调用和keinel_thread内核函数,但是这四种方式最终都是通过调用do_fork函数实现进程的实际创建,只是对应的传入的参数有所不同。
以下是do_fork函数的部分源码【/linux-3.9.4/kernel/fork.c】。
long do_fork(unsigned long clone_flags,
unsigned long stack_start,
unsigned long stack_size,
int __user *parent_tidptr,
int __user *child_tidptr)
{
struct task_struct *p; //创建进程描述符指针
int trace = ;
long nr; //子进程pid ...
//创建子进程的描述符和执行时所需的其他数据结构
p = copy_process(clone_flags, stack_start, stack_size,
child_tidptr, NULL, trace); if (!IS_ERR(p)) { //copy_process执行成功
struct completion vfork; //定义完成量(一个执行单元等待另一个执行单元完成) trace_sched_process_fork(current, p); nr = task_pid_vnr(p); //获取pid ...
//如果clone_flags包含CLONE_VFORK标识,将vfork完成量赋给进程描述符
if (clone_flags & CLONE_VFORK) {
p->vfork_done = &vfork;
init_completion(&vfork);
get_task_struct(p);
} wake_up_new_task(p); //将子进程添加到调度器的队列 ... //如果clone_flags包含CLONE_VFORK标识,将父进程插入等待队列,直到子进程调用exec函数或退出
if (clone_flags & CLONE_VFORK) {
if (!wait_for_vfork_done(p, &vfork))
ptrace_event(PTRACE_EVENT_VFORK_DONE, nr);
}
} else {
nr = PTR_ERR(p); //错误处理
}
return nr; //返回子进程pid(此处的pid为子进程的pid)
}
do_fork()主要完成了调用copy_process()复制父进程的相关信息,调用wake_up_new_task函数将子进程加入到调度器队列中。
以下是copy_process()函数的部分源码【/linux-3.9.4/kernel/fork.c】。
static struct task_struct *copy_process(unsigned long clone_flags,
unsigned long stack_start,
unsigned long stack_size,
int __user *child_tidptr,
struct pid *pid,
int trace)
{
int retval;
struct task_struct *p; ... retval = security_task_create(clone_flags); //安全性检查 ... p = dup_task_struct(current); //复制PCB,为子进程创建内核栈、进程描述符
if (!p)
goto fork_out; ftrace_graph_init_task(p); ... retval = -EAGAIN;
if (nr_threads >= max_threads) //用户进程数目是否超出限制
goto bad_fork_cleanup_count; if (!try_module_get(task_thread_info(p)->exec_domain->module))
goto bad_fork_cleanup_count; ... /* 复制进程信息 */
retval = copy_semundo(clone_flags, p);
...
retval = copy_files(clone_flags, p);
...
retval = copy_fs(clone_flags, p);
...
retval = copy_sighand(clone_flags, p);
...
retval = copy_signal(clone_flags, p);
...
retval = copy_mm(clone_flags, p);
...
retval = copy_namespaces(clone_flags, p);
...
retval = copy_io(clone_flags, p);
...
retval = copy_thread(clone_flags, stack_start, stack_size, p);
...
//如果传入的pid与init_struct_pid地址不同,为子进程分配新的pid
if (pid != &init_struct_pid) {
retval = -ENOMEM;
pid = alloc_pid(p->nsproxy->pid_ns);
if (!pid)
goto bad_fork_cleanup_io;
} p->pid = pid_nr(pid); //根据pid结构体获取pid
p->tgid = p->pid;
if (clone_flags & CLONE_THREAD) //子进程与父进程在同一线程组
p->tgid = current->tgid; //子进程继承父进程的tpid ... if (likely(p->pid)) {
ptrace_init_task(p, (clone_flags & CLONE_PTRACE) || trace); if (thread_group_leader(p)) {
...
//将子进程加入其所在组的散列表中
attach_pid(p, PIDTYPE_PGID, task_pgrp(current));
attach_pid(p, PIDTYPE_SID, task_session(current));
list_add_tail(&p->sibling, &p->real_parent->children);
list_add_tail_rcu(&p->tasks, &init_task.tasks);
__this_cpu_inc(process_counts);
}
attach_pid(p, PIDTYPE_PID, pid);
nr_threads++; //系统中进程数目++
} ... trace_task_newtask(p, clone_flags); return p; //返回子进程描述符p ...
}
copy_process()函数主要完成了调用dup_task_struct函数来复制父进程的进程描述符(tsak_struct)、信息检查、初始化、设置子进程的状态、利用写时复制技术进行进程资源的复制、调用copy_thread来初始化子进程内核堆栈、设置进程pid等。
接下来是实际的验证环节。此次验证过程中,根文件系统需要重做,具体的流程,可参见https://github.com/mengning/linuxkernel/。
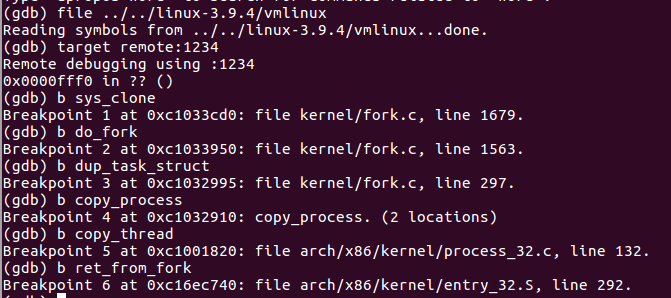 图 1 GDB设置的断点
图 1 GDB设置的断点
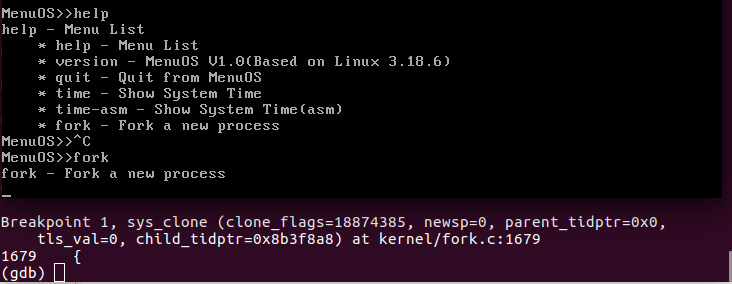
图 2 执行fork功能结果1
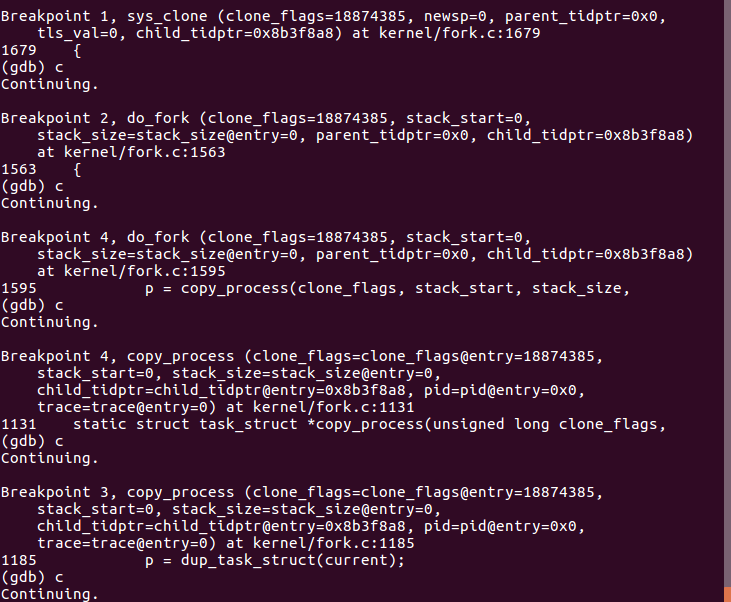
图 2 执行fork功能结果2(断点)
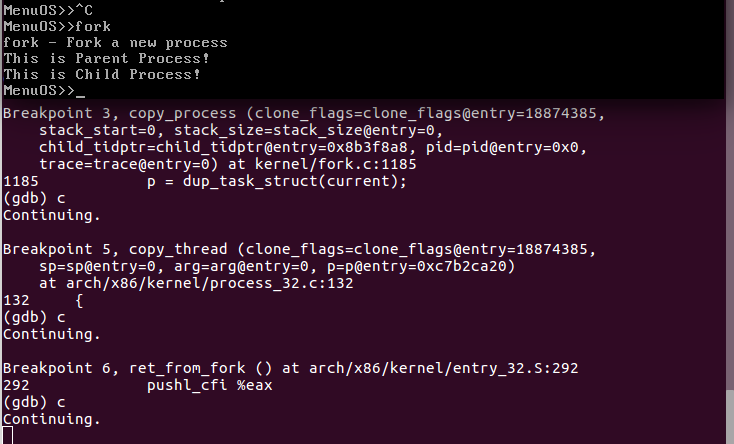
图3 执行fork功能结果3
2、对于Linux内核中可执行程序加载过程的理解
目标文件也叫ABI(Application Binary Interface,应用程序二进制接口)。最开始的目标文件格式是*.out,后来发展成了COFF格式,现如今,常用的目标文件格式主要有两种,一种是Windows平台下的PE,一种是Linux平台下的ELF。
ELF(Executable and Linkable Format),可执行和可连接的格式。ELF格式的文件主要用于存储Linux程序。具体来说,ELF格式文件有三种不同类型的目标文件:可重定位文件、可执行文件、共享目标文件。ELF文件参与程序的链接和执行。
一个源码,需要成为可执行文件之前,需要经历预处理、编译、汇编、链接等几个步骤【以hello.c为例】。
预处理:gcc -E hello.c -o hello.i 。
预处理时,编译器主要的工作有:删除所有注释“//”、“/**/”;删除所有的“#define”,展开所有的宏定义;处理所有的条件预编译指令;处理“#include”预编译指令,将被包含的文件插入该预编译指令的位置;添加行号和标识。处理完之后,hello.i属于文本文件。
编译:gcc -S hello.i -o hello.s -m32 。【-S:只编译,不进行汇编;-m32:生成32位平台格式文件,与64位平台使用不同的寄存器名和指令集】
编译过程中,gcc首先检查代码的正确性和规范性,以进一步确定代码实际要完成的工作。在检查无误之后,gcc把代码翻译成汇编语言。hello,s任然是文本文件。
汇编:gcc -c hello.s -o hello.o.m32 -m32
汇编结束后生成的.o文件为ELF格式的文件。目标文件至少含有三个3个节区(Section),分别是.text、.data和.bss。.bss段(bss segment)(BlockStarted by Symbol),主要是用来存放程序中未初始化的全局变量的一块内存区域,属于静态内存分配,当程序开始运行时,系统将用0来初始化这片内存区域;.data段(data segment,数据段),通常是指用来存放程序中已经初始化的全局变量的一块内存区域,属于静态分配;.text段(code segment/text segment),通常指用来存放程序执行代码的一块内存区域,内存区域大小在程序运行前就已经确定,通常属于只读。除了上述的3个主要的节区之外,还有一些其他常见的节:用于存放C中的字符串和#define定义的常量,包含着只读数据的.rodata段;包含版本控制信息的.comment段;包含动态链接信息的.dymanic段;包含动态链接符号表的.dynsym段;包含用于初始化进程的可执行代码.init段,也就是执行main函数之前需要执行的部分程序。
链接:gcc hello.0.m32 -o hello.m32.static -m32 -static
链接是将各种代码和数据部分收集起来并组合成一个单一文件的过程,这个文件可以为加载到内存中运行。在链接的过程当中,有静态链接和动态链接两种方式。静态链接,直接将需要的执行代码复制到最终的可执行文件中,优点是代码的装载速度快,执行速度也较快,对外部环境依赖度低,缺点是程序占用的内存比较大;动态链接,不直接复治需要的代码,而是通过一系列的符号和参数,在程序运行或加载时将这些信息传递给OS,OS负责将需要的动态库加载到内存中,然后程序在运行指定的代码时,去共享执行内存中已经加载的动态库去执行代码,最终达到运行时链接的目的,动态链接的有点事多个程序可以共享一个代码段,占用内存少,缺点是运行时加载,影响执行性能,对库的依赖度比较高,容易出现版本不兼容的问题。另外,对于动态链接,还可以细分为可执行程序装载时动态链接和运行时动态链接。
对于可执行程序的执行环境,一般是shell程序来启动一个可执行程序,shell环境会执行相应的函数来执行可执行文件。
在Linux中,对于一个可执行文件的执行,可以通过的方式主要有:execl、execlp、execle、execv、exexvp、execve等6个函数,其使用差异主要体现在命令行参数和环境变量参数的不同,这些函数最终都需要调用系统调用函数sys_execve()来实现执行可执行文件的目的。
sys_execve()函数代码如下。
SYSCALL_DEFINE3(execve,
const char __user *, filename,
const char __user *const __user *, argv,
const char __user *const __user *, envp)
{
struct filename *path = getname(filename);
int error = PTR_ERR(path);
if (!IS_ERR(path)) {
error = do_execve(path->name, argv, envp);
putname(path);
}
return error;
}
do_execve()函数代码如下。
int do_execve(const char *filename,
const char __user *const __user *__argv,
const char __user *const __user *__envp)
{
struct user_arg_ptr argv = { .ptr.native = __argv };
struct user_arg_ptr envp = { .ptr.native = __envp };
return do_execve_common(filename, argv, envp);
}
do_execve_common()函数关键代码如下。
/*
* sys_execve() executes a new program.
*/
static int do_execve_common(const char *filename,
struct user_arg_ptr argv,
struct user_arg_ptr envp)
{
struct linux_binprm *bprm;
struct file *file;
struct files_struct *displaced;
bool clear_in_exec;
int retval;
const struct cred *cred = current_cred(); ... file = open_exec(filename); //打开要加载的可执行文件,加载文件头部,判断文件类型 ... //创建一个bprm结构体,把环境变量和命令行参数都复制到结构体中
bprm->file = file;
bprm->filename = filename;
bprm->interp = filename; ... //把传入的shell上下文复制到bprm中
retval = copy_strings(bprm->envc, envp, bprm);
if (retval < )
goto out;
//把传入的命令行参数复制到bprm中
retval = copy_strings(bprm->argc, argv, bprm);
if (retval < )
goto out;
//根据读入的文件头部,寻找可执行文件的处理函数
retval = search_binary_handler(bprm); ... }
int search_binary_handler(struct linux_binprm *bprm)
{
unsigned int depth = bprm->recursion_depth;
int try,retval;
struct linux_binfmt *fmt;
pid_t old_pid, old_vpid; ... retval = security_bprm_check(bprm);//安全检查
... //循环寻找可以解析当前可执行文件的代码
list_for_each_entry(fmt, &formats, lh) {
int (*fn)(struct linux_binprm *) = fmt->load_binary;
...
}
...
return retval;
}
在找到可以解析当前可执行文件的代码之后,会调用start_kernel()开启一个新的进程进行可执行文件的执行。
综合上述的理解,对于系统调用sys_execve的系统调用的主题流程为:sys_execve() -> do_execve() -> do_execve_common() -> search_binary_handler() ->start_thread()。
以下是具体的验证过程。
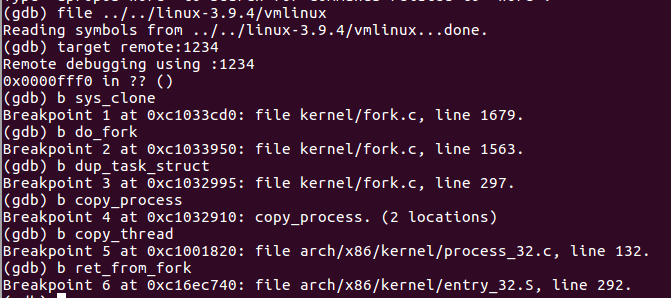
图 4 断点设置
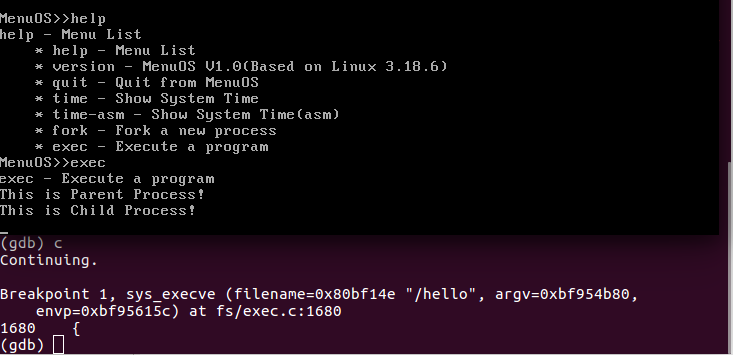
图 5 sys_execve() 跟踪结果1
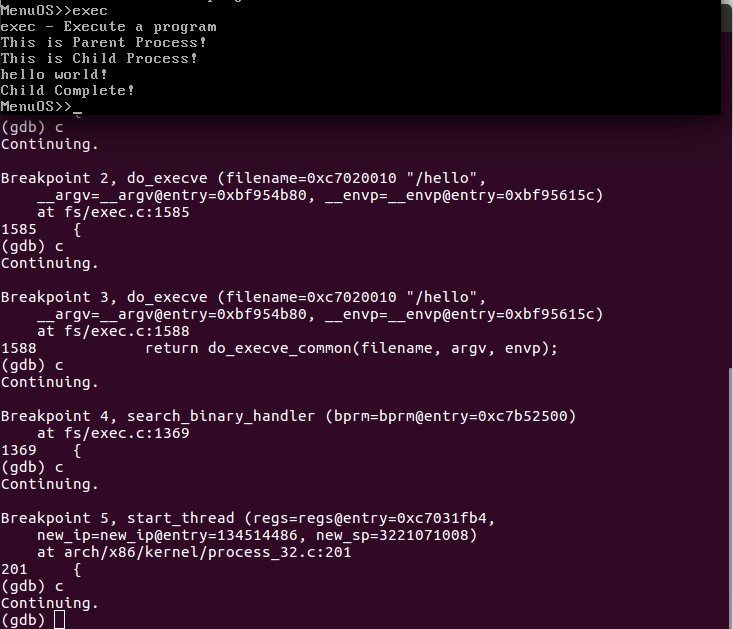
图 6 sys_execve() 跟踪结果2
3、Linux内核中进程调度的时机
进程调度与中断关系密切。在OS中,中断主要有两类,一类是硬中断,也可以认为是外部中断,中断信号由外部产生,经CPU引脚传入内部,比较常用的是时钟中断、键盘、硬盘中断等;一类是软中断或异常,由OS内部产生,主要的类型包括系统调用、调试断点等特殊情况,导致CPU跳转至异常处理程序。具体来说,OS内部异常有3种,分别是故障(Fault)、退出(Abort)、陷阱(Trap)。故障(Fault):有问题,但是可以恢复至当前指令,常见的有缺页中断、除0错误等;退出(Abort):不可恢复的严重故障,导致程序无法运行,只能退出,比较常见的是连续发生故障;陷阱(Trap):程序主动产生的异常,在执行当前指令时发生,比较常见的是系统调用。
Linux内核用过schedule函数实现进程的调度,换句话说,进程调度的实际,就是调用schedule函数的时机。调用schedule函数主要通过两种方式,一种是进程主动调用,比如进程需要等待某事件的发生,会主动调用schedule函数;一种是松散调用,内核代码可以随时调用schedule函数切换进程,比如中断处理程序或者某些内部线程。
总体上来说,进程调度的时机主要有:用户进程通过特定的系统调用主动让出CPU;中断处理程序在内核返回用户态时进行调度;内核线程主动调用schedule函数让出CPU;中断处理程序主动调用schedule函数让出CPU,这类情况涵盖了上述中的第一种、第二种情况。
schedule()函数源码如下【/linux-3.9.4/kernel/sched/core.c】。
asmlinkage void __sched schedule(void)
{
struct task_struct *tsk = current; sched_submit_work(tsk);
__schedule();
}
sched_submit_work()函数源码如下【/linux-3.9.4/kernel/sched/core.c】。
static inline void sched_submit_work(struct task_struct *tsk)
{
if (!tsk->state || tsk_is_pi_blocked(tsk))
return;
/*
* If we are going to sleep and we have plugged IO queued,
* make sure to submit it to avoid deadlocks.
*/
if (blk_needs_flush_plug(tsk))
blk_schedule_flush_plug(tsk);
}
__schedule()函数源码如下【/linux-3.9.4/kernel/sched/core.c】。
static void __sched __schedule(void)
{
struct task_struct *prev, *next;
unsigned long *switch_count;
struct rq *rq;
int cpu; need_resched:
preempt_disable();
cpu = smp_processor_id();
rq = cpu_rq(cpu);
rcu_note_context_switch(cpu);
prev = rq->curr; schedule_debug(prev); if (sched_feat(HRTICK))
hrtick_clear(rq); raw_spin_lock_irq(&rq->lock); switch_count = &prev->nivcsw;
if (prev->state && !(preempt_count() & PREEMPT_ACTIVE)) {
if (unlikely(signal_pending_state(prev->state, prev))) {
prev->state = TASK_RUNNING;
} else {
deactivate_task(rq, prev, DEQUEUE_SLEEP);
prev->on_rq = ; /*
* If a worker went to sleep, notify and ask workqueue
* whether it wants to wake up a task to maintain
* concurrency.
*/
if (prev->flags & PF_WQ_WORKER) {
struct task_struct *to_wakeup; to_wakeup = wq_worker_sleeping(prev, cpu);
if (to_wakeup)
try_to_wake_up_local(to_wakeup);
}
}
switch_count = &prev->nvcsw;
} pre_schedule(rq, prev); if (unlikely(!rq->nr_running))
idle_balance(cpu, rq); put_prev_task(rq, prev);
next = pick_next_task(rq);
clear_tsk_need_resched(prev);
rq->skip_clock_update = ; if (likely(prev != next)) {
rq->nr_switches++;
rq->curr = next;
++*switch_count; context_switch(rq, prev, next); /* unlocks the rq */
/*
* The context switch have flipped the stack from under us
* and restored the local variables which were saved when
* this task called schedule() in the past. prev == current
* is still correct, but it can be moved to another cpu/rq.
*/
cpu = smp_processor_id();
rq = cpu_rq(cpu);
} else
raw_spin_unlock_irq(&rq->lock); post_schedule(rq); sched_preempt_enable_no_resched();
if (need_resched())
goto need_resched;
}
在__schedule()函数中,会调用context_switch()函数进行上下文切换,在context_switch()函数中会调用switch_to()函数进行实质上的进程切换。
4、对于Linux内核中进程切换过程的理解
以下是switch_to()函数的源码部分【/linux-3.9.4/arch/x86/include/asm/switch_to.h】
#define switch_to(prev, next, last) \
do { \
/* \
* Context-switching clobbers all registers, so we clobber \
* them explicitly, via unused output variables. \
* (EAX and EBP is not listed because EBP is saved/restored \
* explicitly for wchan access and EAX is the return value of \
* __switch_to()) \
*/ \
unsigned long ebx, ecx, edx, esi, edi; \
\
asm volatile("pushfl\n\t" /* save flags */ \
"pushl %%ebp\n\t" /* save EBP */ \
"movl %%esp,%[prev_sp]\n\t" /* save ESP */ \
"movl %[next_sp],%%esp\n\t" /* restore ESP */ \
"movl $1f,%[prev_ip]\n\t" /* save EIP */ \
"pushl %[next_ip]\n\t" /* restore EIP */ \
__switch_canary \
"jmp __switch_to\n" /* regparm call */ \
"1:\t" \
"popl %%ebp\n\t" /* restore EBP */ \
"popfl\n" /* restore flags */ \
\
/* output parameters */ \
: [prev_sp] "=m" (prev->thread.sp), \
[prev_ip] "=m" (prev->thread.ip), \
"=a" (last), \
\
/* clobbered output registers: */ \
"=b" (ebx), "=c" (ecx), "=d" (edx), \
"=S" (esi), "=D" (edi) \
\
__switch_canary_oparam \
\
/* input parameters: */ \
: [next_sp] "m" (next->thread.sp), \
[next_ip] "m" (next->thread.ip), \
\
/* regparm parameters for __switch_to(): */ \
[prev] "a" (prev), \
[next] "d" (next) \
\
__switch_canary_iparam \
\
: /* reloaded segment registers */ \
"memory"); \
} while ()
通过对上述的源码我们知道,witch_to()函数才是本质上实现进程切换的函数。函数内保存了当前进程的ip、堆栈栈顶等信息,还将下一进程的相关信息取出并执行。
四、总结与结论
本次实验,总体上对于进程创建、可执行文件的装载和执行、进程调度时机、进程切换等方面有了一定程度的了解,但是,了解的还是不够深入,具体的细节还是存在着很多疑问,需要进一步的消化。
对于Linux内核执行过程的理解(基于fork、execve、schedule等函数)的更多相关文章
- Linux内核3.0移植并基于Initramfs根文件系统启动
Linux内核移植与启动 Target borad:FL2440 Bootloader:U-boot-2010.09 交叉编译器:buildroot-2012.08 1.linux内核基础知识 首先, ...
- Linux内核启动过程概述
版权声明:本文原创,转载需声明作者ID和原文链接地址. Hi!大家好,我是CrazyCatJack.今天给大家带来的是Linux内核启动过程概述.希望能够帮助大家更好的理解Linux内核的启动,并且创 ...
- Linux内核分析实验八------理解进程调度时机跟踪分析进程调度与
一.进程调度与进程调度的时机分析 1.不同类型的进程有不同的调度需求 Linux既支持普通的分时进程,也支持实时进程. Linux中的调度是多种调度策略和调度算法的混合. 2.调度策略:是一组规则,它 ...
- Linux脚本执行过程重定向
Linux脚本执行过程重定向 一.bash调试脚本,并将执行过程重定向到指定文件 bash –x shell.sh 2>&1 | tee shell.log
- linux内核--自旋锁的理解
http://blog.chinaunix.net/uid-20543672-id-3252604.html 自旋锁:如果内核配置为SMP系统,自旋锁就按SMP系统上的要求来实现真正的自旋等待,但是对 ...
- Linux内核启动过程start_kernel分析
虽然题目是start_kernel分析,但是由于我在ubuntu环境下配置实验环境遇到了一些问题,我觉得有必要把这些问题及其解决办法写下来. 首先我使用的是Ubuntu14.04 amx64,以下的步 ...
- c语言编译预处理和条件编译执行过程的理解
在C语言的程序中可包括各种以符号#开头的编译指令,这些指令称为预处理命令.预处理命令属于C语言编译器,而不是C语言的组成部分.通过预处理命令可扩展C语言程序设计的环境. 一.预处理的工作方式 1.1. ...
- 使用gdb跟踪Linux内核启动过程(从start_kernel到init进程启动)
本次实验过程如下: 1. 运行MenuOS系统 在实验楼的虚拟机环境里,打击打开shell,使用下面的命令 cd LinuxKernel/ qemu -kernel linux-/arch/x86/b ...
- linux内核移植过程问题总结
移植内核:2.6.30.4内核根目录下的.config为当前配置内核的且已经配置好的内核配置.make zImage以此为依据配置内核的过程:cd linux-2.6.30.4(进入Linux根目录) ...
随机推荐
- 活代码LINQ——02
一.复习基础——属性与实例变量 'Fig. 4.8:GradeBookTest.vb 'Create and manipulate a GradeBook object. Module GradeBo ...
- tinyproxy代理配置
tinyproxy代理配置 应用场景: 生产机处于内网,无法直接访问外网,程序安装和漏洞修复等操作需要进行联网操作:通过在办公网(可访问外网)上设置代理服务器,生产机通过代理由办公网访问外网 代理服务 ...
- 分享我编写的powershell脚本:ssh-copy-id.ps1
问:通过[字符串界面].如何从win,通过ssh,连接到sshd?答:在任意版本win中,通过cmd.exe,powershell.exe中调用ssh.exe,连接sshd. 问:通过[pow ...
- 12月4日学习爬虫007.使用Urllib模块进行简单网页爬取
笔记如下: 1.https是http加强版协议(安全协议)http(普通网络通信协议) 爬数据 如果爬https发现和理想中的数据不同,可以改为http 直接去掉s即可 2.使用Urllib爬取简单网 ...
- Centos7搭建docker仓库
一:安装启动registry 1.1:环境准备 yum install -y python-devel libevent-devel python-pip gcc xz-devel pip insta ...
- 关于Appium android input manager for Unicode 提示信息
Appium调完输入法后,会弹出 Appium android input manager for Unicode 提示信息相关的提示信息,每次运行如此,如下图 网络上查找一遍,基本解决了,只要在设 ...
- Android 问题列表
25. Touch 事件传递机制 26. 点击事件设置监听的几种方式 27. Hander 的原理 28. Thread 和HandThread 的区别 29. AsyncTask 简介 30. As ...
- java this关键字的使用
this关键字 this关键字只能在方法内部使用,表示对"调用方法的那个对象"的引用. this的三个用法: 1.调用本类中的其他方法 如果在方法 ...
- 利用svn的补丁文件打包生成增量文件
下面的代码是maven版本 1. 创建patch.txt增量文件 保存到 文件目录下 比如 E:\aa\patch.txt 2. 编写java代码 package utils; import java ...
- Mysql和Hadoop+Hive有什么关系?
1.Hive不存储数据,Hive需要分析计算的数据,以及计算结果后的数据实际存储在分布式系统上,如HDFS上. 2.Hive某种程度来说也不进行数据计算,只是个解释器,只是将用户需要对数据处理的逻辑, ...