mysql 深度分页
mysql 分页查询使我们常见的需求 ,但是随着页数的增加查询性能会逐渐下降,尤其是到深度分页的情况。我们可以把分页分为两个步骤,1.定位偏移量,2.获取分页条数的 数据。
所以当数据较大页数较深时就涉及一次需要耗费较长时间的操作。所以mysql深度分页的 问题该如何解决呢 ?
首先我们来看一个简单的查询:
SELECT * FROM events WHERE date > '2010-01-01T00:00:00-00:00' AND event = 'editstart' ORDER BY date LIMIT 50000 50;
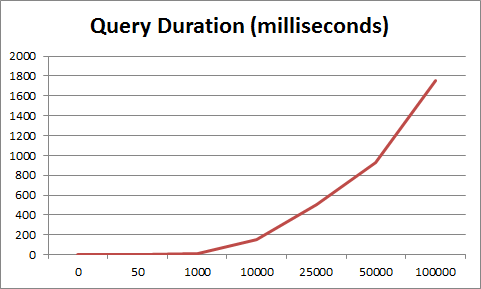
可以发现在一定页数后时间延时非常明显。结合相关文章我们的解决方式可以大致分为以下几种.
思路:
既然分页查询时,定位偏移量较慢,我们可不可以减少这个偏移量的定位,使其始终曲线的前半部分,即在较少偏移量的场景。
方法一:以结果作为条件,已查询条件的变化换取分页的不变。
分页查询我们一般都是逐渐往后翻页的,那么我们可以很清晰的知道,在当前查询页的最后一条数据的时间点,那么,以此时间点再查询20条,那么 我们当前的页数就同样还是0,以时间点的推移换取页数的不变,减少其偏移量的计算。
我们可以创建索引 index(date,id), id就是我们上一次的返回结果。
具体示例如下:
SELECT *FROM events WHERE (date,id) > ('2010-07-12T10:29:47-07:00',111866) AND event = 'editstart' ORDER BY date, id LIMIT 50000 50
以上方法的局限性:
1.id最好是主键,是否有这样自增长的字段,或者说带顺序变化特性的列。
2.无法适应下一次分页页数与上一次相差较大,如由第一页突然跳转到50万页。
优点:可以适合复杂查询条件查询的场景。不需要改变sql语句结构
方法二:
采用子查询模式,其原理依赖于覆盖索引,当查询的列,均是索引字段时,性能较快,因为其只用遍历索引本身。我们自己创建的非主键索引,都是非聚集索引,其不包含非索引字段,所以数据结构较小,系统能快速遍历。我们知道索引时b+树结构,系统能很容易的知道866613,位于索引树的位置。
##查询语句
select id from product limit 866613, 20
##优化方式一
SELECT * FROM product WHERE ID > =(select id from product limit 866613, 1) limit 20
##优化方式二
SELECT * FROM product a JOIN (select id from product limit 866613, 20) b ON a.ID = b.id
局限性:
依赖于主键的自增长特性。
不适合复杂查询条件的分页逻辑,复杂查询条件很难做到,索引包含全部查询字段,容易漏掉部分数据。
方法三:
复合索引:其原理同样是索引覆盖的思想,只不过是其以查询条件的一份作为索引,最终的索引字段是主键id。这种场景严格依赖于索引的顺序。查询的结果也不能包含非索引字段,需再走一次子查询。
可以参考博客:https://blog.csdn.net/yalishadaa/article/details/72861309
关于深度分页:
针对复杂的查询逻辑,一般从数据的 偏移量着手,减少偏移量的定位时间。
简单的查询逻辑,可以从索引覆盖的思想着手,先确定查询数据的主键id,再由id找相关的数据,索引能解决的 就不要加给业务逻辑了。
mysql 深度分页的更多相关文章
- 上亿数据怎么玩深度分页?兼容MySQL + ES + MongoDB
面试题 & 真实经历 面试题:在数据量很大的情况下,怎么实现深度分页? 大家在面试时,或者准备面试中可能会遇到上述的问题,大多的回答基本上是分库分表建索引,这是一种很标准的正确回答,但现实总是 ...
- MySQL的分页优化
今天下午,帮同事重写了一个MySQL SQL语句,该SQL语句涉及两张表,其中一张表是字典表(需返回一个字段),另一张表是业务表(本身就有150个字段,需全部返回),当然,字段的个数是否合理在这里不予 ...
- oracle sqlserver mysql数据库分页
1.Mysql的limit用法 在我们使用查询语句的时候,经常要返回前几条或者中间某几行数据,这个时候怎么办呢?不用担心,mysql已经为我们提供了这样一个功能. SELECT * FROM tabl ...
- MySQL的分页
有朋友问: MySQL的分页似乎一直是个问题,有什么优化方法吗?网上看到网上推荐了一些分页方法,但似乎不太可行,你能点评一下吗? 方法1: 直接使用数据库提供的SQL语句 ---语句样式: MySQL ...
- MySql通用分页存储过程
MySql通用分页存储过程 1MySql通用分页存储过程 2 3过程参数 4p_cloumns varchar(500),p_tables varchar(100),p_where varchar(4 ...
- Statement和PreparedStatement的特点 MySQL数据库分页 存取大对象 批处理 获取数据库主键值
1 Statement和PreparedStatement的特点 a)对于创建和删除表或数据库,我们可以使用executeUpdate(),该方法返回0,表示未影向表中任何记录 b)对于创建和 ...
- mysql 查询优化~ 分页优化讲解
一 简介:今天咱们来聊聊mysql的分页查询二 语法 LIMIT [offset,] rows offset是第多少条 rows代表多少条之后的行数 性能消耗 se ...
- solr使用cursorMark做深度分页
深度分页 深度分页是指给搜索结果指定一个很大的起始位移. 普通分页在给定一个大的起始位移时效率十分低下,例如start=1000000,rows=10的查询,搜索引擎需要找到前1000010条记录然后 ...
- Solr中使用游标进行深度分页查询以提高效率(适用的场景下)
通常,我们的应用系统,如果要做一次全量数据的读取,大多数时候,采用的方式会是使用分页读取的方式,然而 分页读取的方式,在大数据量的情况下,在solr里面表现并不是特别好,因为它随时可能会发生OOM的异 ...
随机推荐
- 吴裕雄--天生自然PYTHON爬虫:爬虫攻防战
我们在开发者模式下不仅可以找到URL.Form Data,还可以在Request headers 中构造浏览器的请求头,封装自己.服务器识别浏览器访问的方法就是判断keywor是否为Request h ...
- Python作业篇 day03
###一.有变量name = 'aleX leNb',完成如下的操作 name = 'aleX leNb' name1 = ' aleX leNb ' #1.移除name1 变量对应的值两边的空格 , ...
- stringstream常见用法介绍
1 概述 <sstream> 定义了三个类:istringstream.ostringstream 和 stringstream,分别用来进行流的输入.输出和输入输出操作.本文以 stri ...
- 在线配置raid
Exit Code: 0x00 rpm -ivh MegaCli-8.07.14-1.noarch.rpm ls /opt/MegaRAID/MegaCli//opt/MegaRAID/MegaCli ...
- BugFix系列---开篇介绍
这个系列的文章,主要目的在于积累总结实际开发中遇到的错误,记录下来自己的解决思路,用来提升自己. 不出意外,应该会持续不断的记录更新,在整个开发openstack的过程中,抓住机会吸取开源界大牛的 ...
- 使用自己定义的DIV的滚动条
基本思路: 让DIV浮动起来,利用postion:fixed/absolute,设定height:100% var $card=$("#cardDetail"); $ca ...
- NULL判斷符
Null 传导运算符 编程实务中,如果读取对象内部的某个属性,往往需要判断一下该对象是否存在.比如,要读取message.body.user.firstName,安全的写法是写成下面这样. const ...
- Oracle性能优化小结
Oracle性能优化小结 原则一.注意where子句中的连接顺序 Oracle采用自下而上的顺序解析where子句,根据这个原理,表之间的连接必须卸载其他where条件之前,哪些可以滤掉最大数量记录的 ...
- 设备树DTS 学习:1-有关概念
背景 设备树在Linux驱动开发中是一种比较常用的架构. 参考:<设备树DTS使用总结> .<linux内核设备树及编译> Linux设备树 介绍 在Linux 2.6中,ar ...
- Linux:Shell-Bash基本功能
1.历史命令 history [选项] [历史命令保存文件] 选项:-c 清空历史命令 -w 把缓存中的历史命令写入历史命令保存文件 ~/.bash_history 历史命令默认保存1000条,可以 ...