吴裕雄--天生自然PYTHON爬虫:爬虫攻防战

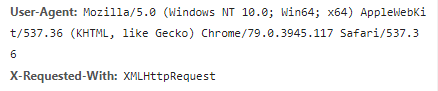

我们在开发者模式下不仅可以找到URL、Form Data,还可以在Request headers 中构造浏览器的请求头,封装自己。服务器识别浏览器访问的方法就是判断keywor是否为Request headers下的User-Agent,因此我们只需要构造这个请求头的参数。创建请求头部信息即可。
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/79.0.3945.117 Safari/537.36'
}
response = requests.get(url,headers=headers)
写到这里,或许许多人认为修改User-Agent很简单,也确实是简单,但是正常人1秒看一张图片,而如果是代码爬虫的话1秒就可以抓取好多张图,比如1秒就抓取了一百张图片,那么服务器的压力必然会增大。也就是说如果在一个IP下批量访问下载图片,这个行为不符合正常人类的行为,这个访问IP肯定要被封的。其原理也很简单,就是统计每个IP的访问率,该频率超过了阈值,就会返回一个验证码,如果真的是用户访问的话,用户就会填写,然后继续访问,如果是代码访问的话,就会封IP。
这个问题的解决方案有两个,第一个就是常用的增设延时,每三秒抓取一次,代码如下:
import time
time.sleep(3)
不管如何访问,服务器的目的就是要查出哪些访问是代码访问,然后封IP,解决避免被封IP,在数据采集时经常会使用代理。当然,requests也有相应的proxies属性。首先,构建自己的代理IP池,将其以字典的形式赋值给proxies,然后传输给requests,代码如下:
proxies = {
'http':'http://10.10.1.10:3128',
'https':'http://10.10.1.10:1080'
}
response = requests.get(url,proxies=proxies)
吴裕雄--天生自然PYTHON爬虫:爬虫攻防战的更多相关文章
- 吴裕雄--天生自然PYTHON爬虫:使用Selenium爬取大型电商网站数据
用python爬取动态网页时,普通的requests,urllib2无法实现.例如有些网站点击下一页时,会加载新的内容,但是网页的URL却没有改变(没有传入页码相关的参数),requests.urll ...
- 吴裕雄--天生自然PYTHON爬虫:爬取某一大型电商网站的商品数据(效率优化以及代码容错处理)
这篇博文主要是对我的这篇https://www.cnblogs.com/tszr/p/12198054.html爬虫效率的优化,目的是为了提高爬虫效率. 可以根据出发地同时调用多个CPU,每个CPU运 ...
- 吴裕雄--天生自然PYTHON爬虫:使用Scrapy抓取股票行情
Scrapy框架它能够帮助提升爬虫的效率,从而更好地实现爬虫.Scrapy是一个为了抓取网页数据.提取结构性数据而编写的应用框架,该框架是封装的,包含request异步调度和处理.下载器(多线程的Do ...
- 吴裕雄--天生自然python学习笔记:编写网络爬虫代码获取指定网站的图片
我们经常会在网上搜索井下载图片,然而一张一张地下载就太麻烦了,本案例 就是通过网络爬虫技术, 一次性下载该网站所有的图片并保存 . 网站图片下载并保存 将指定网站的 .jpg 和 .png 格式的图片 ...
- 吴裕雄--天生自然python学习笔记:python爬虫PM2.5 实时监测显示器
PM2.5 对人体的健康影响很大,所以空气中的 PM2.5 实时信息受到越来越多的关注. Python 的 Pandas 套件不但可以自动读取网页中的表格 数据 , 还可对数据进行修改.排序等处理,也 ...
- 吴裕雄--天生自然python学习笔记:python爬虫与网页分析
我们所抓取的网页源代码一般都是 HTML 格式的文件,只要研究明白 HTML 中 的标签( Tag )结构,就很容易进行解析并取得所需数据 . HTML 网页结构 HTML 网 页是由许多标签( Ta ...
- 吴裕雄--天生自然PYTHON爬虫:安装配置MongoDBy和爬取天气数据并清洗保存到MongoDB中
1.下载MongoDB 官网下载:https://www.mongodb.com/download-center#community 上面这张图选择第二个按钮 上面这张图直接Next 把bin路径添加 ...
- 吴裕雄--天生自然PYTHON爬虫:用API爬出天气预报信息
天气预报网址:https://id.heweather.com/,这个网站是需要注册获取一个个人认证后台密钥key的,并且每个人都有访问次数的限制,这个key就是访问API的钥匙. 这个key现在是要 ...
- 吴裕雄--天生自然PYTHON爬虫:使用BeautifulSoup解析中国旅游网页数据
import requests from bs4 import BeautifulSoup url = "http://www.cntour.cn/" strhtml = requ ...
随机推荐
- 【C语言】创建一个函数,判断某一正整数是否为素数,并调用这个函数找出1000以内所有素数
#include <stdio.h> int fun(int x) { int n; ;n<=x-;n++) ) break; if(n>=x) ; else ; } main ...
- 使用ssh 初始化git一个空java工程
1:进入git 目录 cd /home/git/repo/ 2:创建一个java工程名 mkdir qft-payment 3:进入工程 cd qft-payment/ 4:初始化空工程 git - ...
- socket实现简单的FTP
一.开发环境 server端:centos 7 python-3.6.2 客户端:Windows 7 python-3.6.2 pycharm-2018 程序目的:1.学习使用socketserve ...
- 计算机基础 - 动态规划、分治法、memo
动态规划 ≈ 分治法 + memo def memo(func): cache = {} def wrap(*args): if args not in cache: cache[args] = fu ...
- Linux - 查看文件、文件夹、磁盘大小命令
1. ls -lsh 2. du -sh du == disk usage (磁盘使用量,占用的磁盘空间) 一个文件占用的磁盘空间和一个文件的大小是两码事情.占用空间取决于文件系统的块(block)的 ...
- 记录我对'我们有成熟的时间复杂度为O(n)的算法得到数组中任意第k大的数'的误解
这篇博客记录我对剑指offer第2版"面试题39:数组中出现次数超过一半的数字"题解1的一句话的一个小误解,以及汇总一下涉及partition算法的相关题目. 在剑指offer第2 ...
- 拓扑排序板子 hihocoder-1174
思路 不断删入度为1的点及其出边. 图解 #include <bits/stdc++.h> using namespace std; const int maxn=1e5+10; vect ...
- 【代码审计】VAuditDemo SQL注入漏洞
这里我们定位 sqlwaf函数 在sys/lib.php中,过滤了很多关键字,但是42 43 44行可以替换为空 比如我们可以 uni||on来绕过过滤
- Golang核心编程
源码地址: https://github.com/mikeygithub/GoCode 第1章 1Golang 的学习方向 Go 语言,我们可以简单的写成 Golang 1.2Golang 的应用领域 ...
- 23 JavaScript规范与最佳实践&性能&箭头函数
大多数web服务器(Apache等)对大小写敏感,因此命名注意大小写 不要声明字符串.数字和布尔值,始终把他们看做原始值而非对象,如果把这些声明为对象,会拖慢执行速度 对象是无法比较的,原始值可以 不 ...