mysql 深度分页
mysql 分页查询使我们常见的需求 ,但是随着页数的增加查询性能会逐渐下降,尤其是到深度分页的情况。我们可以把分页分为两个步骤,1.定位偏移量,2.获取分页条数的 数据。
所以当数据较大页数较深时就涉及一次需要耗费较长时间的操作。所以mysql深度分页的 问题该如何解决呢 ?
首先我们来看一个简单的查询:
SELECT * FROM events WHERE date > '2010-01-01T00:00:00-00:00' AND event = 'editstart' ORDER BY date LIMIT 50000 50;
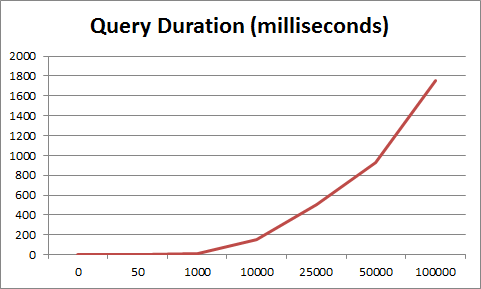
可以发现在一定页数后时间延时非常明显。结合相关文章我们的解决方式可以大致分为以下几种.
思路:
既然分页查询时,定位偏移量较慢,我们可不可以减少这个偏移量的定位,使其始终曲线的前半部分,即在较少偏移量的场景。
方法一:以结果作为条件,已查询条件的变化换取分页的不变。
分页查询我们一般都是逐渐往后翻页的,那么我们可以很清晰的知道,在当前查询页的最后一条数据的时间点,那么,以此时间点再查询20条,那么 我们当前的页数就同样还是0,以时间点的推移换取页数的不变,减少其偏移量的计算。
我们可以创建索引 index(date,id), id就是我们上一次的返回结果。
具体示例如下:
SELECT *FROM events WHERE (date,id) > ('2010-07-12T10:29:47-07:00',111866) AND event = 'editstart' ORDER BY date, id LIMIT 50000 50
以上方法的局限性:
1.id最好是主键,是否有这样自增长的字段,或者说带顺序变化特性的列。
2.无法适应下一次分页页数与上一次相差较大,如由第一页突然跳转到50万页。
优点:可以适合复杂查询条件查询的场景。不需要改变sql语句结构
方法二:
采用子查询模式,其原理依赖于覆盖索引,当查询的列,均是索引字段时,性能较快,因为其只用遍历索引本身。我们自己创建的非主键索引,都是非聚集索引,其不包含非索引字段,所以数据结构较小,系统能快速遍历。我们知道索引时b+树结构,系统能很容易的知道866613,位于索引树的位置。
##查询语句
select id from product limit 866613, 20
##优化方式一
SELECT * FROM product WHERE ID > =(select id from product limit 866613, 1) limit 20
##优化方式二
SELECT * FROM product a JOIN (select id from product limit 866613, 20) b ON a.ID = b.id
局限性:
依赖于主键的自增长特性。
不适合复杂查询条件的分页逻辑,复杂查询条件很难做到,索引包含全部查询字段,容易漏掉部分数据。
方法三:
复合索引:其原理同样是索引覆盖的思想,只不过是其以查询条件的一份作为索引,最终的索引字段是主键id。这种场景严格依赖于索引的顺序。查询的结果也不能包含非索引字段,需再走一次子查询。
可以参考博客:https://blog.csdn.net/yalishadaa/article/details/72861309
关于深度分页:
针对复杂的查询逻辑,一般从数据的 偏移量着手,减少偏移量的定位时间。
简单的查询逻辑,可以从索引覆盖的思想着手,先确定查询数据的主键id,再由id找相关的数据,索引能解决的 就不要加给业务逻辑了。
mysql 深度分页的更多相关文章
- 上亿数据怎么玩深度分页?兼容MySQL + ES + MongoDB
面试题 & 真实经历 面试题:在数据量很大的情况下,怎么实现深度分页? 大家在面试时,或者准备面试中可能会遇到上述的问题,大多的回答基本上是分库分表建索引,这是一种很标准的正确回答,但现实总是 ...
- MySQL的分页优化
今天下午,帮同事重写了一个MySQL SQL语句,该SQL语句涉及两张表,其中一张表是字典表(需返回一个字段),另一张表是业务表(本身就有150个字段,需全部返回),当然,字段的个数是否合理在这里不予 ...
- oracle sqlserver mysql数据库分页
1.Mysql的limit用法 在我们使用查询语句的时候,经常要返回前几条或者中间某几行数据,这个时候怎么办呢?不用担心,mysql已经为我们提供了这样一个功能. SELECT * FROM tabl ...
- MySQL的分页
有朋友问: MySQL的分页似乎一直是个问题,有什么优化方法吗?网上看到网上推荐了一些分页方法,但似乎不太可行,你能点评一下吗? 方法1: 直接使用数据库提供的SQL语句 ---语句样式: MySQL ...
- MySql通用分页存储过程
MySql通用分页存储过程 1MySql通用分页存储过程 2 3过程参数 4p_cloumns varchar(500),p_tables varchar(100),p_where varchar(4 ...
- Statement和PreparedStatement的特点 MySQL数据库分页 存取大对象 批处理 获取数据库主键值
1 Statement和PreparedStatement的特点 a)对于创建和删除表或数据库,我们可以使用executeUpdate(),该方法返回0,表示未影向表中任何记录 b)对于创建和 ...
- mysql 查询优化~ 分页优化讲解
一 简介:今天咱们来聊聊mysql的分页查询二 语法 LIMIT [offset,] rows offset是第多少条 rows代表多少条之后的行数 性能消耗 se ...
- solr使用cursorMark做深度分页
深度分页 深度分页是指给搜索结果指定一个很大的起始位移. 普通分页在给定一个大的起始位移时效率十分低下,例如start=1000000,rows=10的查询,搜索引擎需要找到前1000010条记录然后 ...
- Solr中使用游标进行深度分页查询以提高效率(适用的场景下)
通常,我们的应用系统,如果要做一次全量数据的读取,大多数时候,采用的方式会是使用分页读取的方式,然而 分页读取的方式,在大数据量的情况下,在solr里面表现并不是特别好,因为它随时可能会发生OOM的异 ...
随机推荐
- C 随机数产生
// ConsoleApplication5.cpp : Defines the entry point for the console application. // #include " ...
- JS动态获取 Url 参数
此操作主要用于动态 ajax 请求 1.首先封装一个函数 GetRequest(),能动态获取到 url 问号"?"后的所有参数 , function GetRequest() { ...
- 「Luogu P2845 [USACO15DEC]Switching on the Lights 开关灯」
USACO的又一道搜索题 前置芝士 BFS(DFS)遍历:用来搜索.(因为BFS好写,本文以BFS为准还不是因为作者懒) 链式前向星,本题的数据比较水,所以邻接表也可以写,但是链式前向星它不香吗. 具 ...
- COGS 2294. [HZOI 2015] 释迦
额,其实就是裸的三模数NTT,上一篇已经说过了 哦,还有一个就是对乘起来炸long long的数取模,用long double之类的搞一下就好,精度什么的,,(看出题人心情??) #include&l ...
- vue 移动端屏幕适配
https://github.com/evrone/postcss-px-to-viewport/blob/master/README_CN.md基本配置 // eslint-disable-next ...
- 总结了一下 Vue.nextTick() 的原理和用途
对于 Vue.nextTick 方法,自己有些疑惑.在查询了各种资料后,总结了一下其原理和用途,如有错误,请不吝赐教. 概览 官方文档说明: 用法: 在下次 DOM 更新循环结束之后执行延迟回调.在修 ...
- vue+element 递归上传图片
直接上代码. <template> <div> <el-upload action="http://localhost:3000/pic ...
- R 误差自相关与DW检验
R语言进行DW检验: library(lmtest) dw = dwtest(fm1) > dw Durbin-Watson test data: fm1 DW = 2.4994, p-valu ...
- 通过流量管理器和 Azure Functions(作为代理)为全球用户提供最靠近的认知服务(或自定义API)
本实战是一个中等复杂度的综合性实战,涉及到的内容有TrafficManager,AzureFunctions,域名/域名解析等几个内容. 本案例基础介绍: https://www.bilibili.c ...
- Intellij IDEA中配置TFS
TFS是微软推出的一款研发过程管理利器,C#阵营的VS里做了默认集成,但是对于Java阵营的Intellij IDEA,需要安装插件并进行相应配置才能使用: 1.打开配置 2.搜索并安装插件 3.配置 ...