G1 垃圾回收器简单调优
G1: Garbage First 低延迟、服务侧分代垃圾回收器。
详细介绍参见:JVM之G1收集器,这里不再赘述。
关于调优目标:延迟、吞吐量
一、延迟,单次的延迟
单次的延迟关系到服务的响应时延,比如,在要求接口响应不超过100ms的服务里,单次的延迟目标必然不能超过100ms。
服务的响应时间目标,不应该是指100%时间的服务响应。服务不可能是100%可用的,通常,我们对于服务的响应延迟目标也不是100%可用时间内的。
实际应用中,我们可能会以99.9%时间内,延迟不超过100ms为目标。
对于G1,会有一些默认设置,以使应用者在不做任何调整的情况下,依然能高效的运行。
-XX:MaxGCPauseMillis=200:目标最大gc暂停时间,默认为200ms,这只是期望的目标延迟。我们知道G1有相应的收集算法,会根据收集的信息及检测的垃圾量动态的调整年轻代与老年代的大小以尽力达到这个目标。
使用此配置需要注意的一点是,不要和 Xmn 年轻代同时设置,我们上面提到过,G1会为了最大gc暂停时间目标而动态的调整年轻代大小,因此,如果设定了 Xmn,那么固定了年轻代的大小就会影响G1的智能调整适应。
二、吞吐量,有多少总的延迟
总的延迟关系到服务的可用时间率、吞吐量,比如,100分钟内总的gc延迟1分钟,那么服务的可用率就是99%。如果既定的目标是99.9%,那么总的延迟就不能超过6秒钟。
总的延迟=单次延迟*gc次数。
单次延迟我们在一.1中已经论述,那么现在就需要通过降低gc次数来达到降低总延迟的目标,
gc触发于应用内存占用达到一定比例阈值,因此想要降低gc频次,那么就需要适当调大应用可使用堆大小:Xmx。
应用到底需要使用多大的应用内存,这个需要根据实际的需求确定,可以通过压测,不断的微调来找到最适合的Xmx设置,过大或者过小都会影响服务的服务能力。
三、gc日志
配置输出gc日志:-verbose:gc -XX:+PrintGCDetails -XX:+PrintGCTimeStamps -XX:+PrintGCDateStamps。
下面是一段实际应用中的yong GC日志:
[GC pause (G1 Evacuation Pause) (young), 0.1006389 secs]
[Parallel Time: 45.6 ms, GC Workers: 38]
[GC Worker Start (ms): Min: 4053175.2, Avg: 4053184.8, Max: 4053215.7, Diff: 40.5]
[Ext Root Scanning (ms): Min: 0.0, Avg: 1.2, Max: 8.6, Diff: 8.6, Sum: 47.1]
[Update RS (ms): Min: 0.0, Avg: 8.4, Max: 41.3, Diff: 41.3, Sum: 317.3]
[Processed Buffers: Min: 0, Avg: 13.3, Max: 39, Diff: 39, Sum: 505]
[Scan RS (ms): Min: 0.0, Avg: 0.2, Max: 0.4, Diff: 0.4, Sum: 7.7]
[Code Root Scanning (ms): Min: 0.0, Avg: 0.0, Max: 0.0, Diff: 0.0, Sum: 0.3]
[Object Copy (ms): Min: 0.0, Avg: 20.6, Max: 32.6, Diff: 32.5, Sum: 783.9]
[Termination (ms): Min: 0.0, Avg: 4.5, Max: 5.2, Diff: 5.2, Sum: 171.5]
[GC Worker Other (ms): Min: 0.0, Avg: 0.2, Max: 0.6, Diff: 0.6, Sum: 5.9]
[GC Worker Total (ms): Min: 4.1, Avg: 35.1, Max: 44.6, Diff: 40.5, Sum: 1333.8]
[GC Worker End (ms): Min: 4053219.7, Avg: 4053219.9, Max: 4053220.4, Diff: 0.8]
[Code Root Fixup: 0.3 ms]
[Code Root Purge: 0.0 ms]
[Clear CT: 1.5 ms]
[Other: 53.2 ms]
[Choose CSet: 0.0 ms]
[Ref Proc: 39.2 ms]
[Ref Enq: 8.6 ms]
[Redirty Cards: 1.3 ms]
[Humongous Reclaim: 0.0 ms]
[Free CSet: 2.0 ms]
[Eden: 4708.0M(4708.0M)->0.0B(4724.0M) Survivors: 204.0M->188.0M Heap: 5528.0M(8192.0M)->804.9M(8192.0M)]
[Times: user=1.37 sys=0.02, real=0.10 secs]
第一行:指明GC类型,一次GC的总耗时 0.1006389 secs,即100ms。
第二行:并行阶段STW时间汇,GC工作线程数(配置:-XX:ParallelGCThreads。CPU数量小于8时,值取CPU个数,最大为8,CPU数量大于8时,值取(CPU个数*5/8))。
第三行:GC线程开始工作时间,Min最小值、Avg平均值、Max最大值、Diff偏移平均的值(Max-Min)
第四行:外部根区扫描,包括堆外区、JNI引用、JVM系统目录、Classloaders等。Sum总耗时。
第五行:RSets(Remembered Sets )时间信息更新,G1依据-XX:MaxGCPauseMillis参数来设定目标暂停时间,RSet更新的时间耗时应小于目标暂停时间的10%。可以通过修改配置 XX:G1RSetUpdatingPauseTimePercent 设预期定耗时占用比。
第六行:已处理缓冲区:即在优化线程中处理dirty card分区扫描时记录的日志缓冲区。
第七行:RSets扫描。
第八行:代码Root扫描,经过JIT编译后的代码里引用了heap中的对象,引用关系保存在RSet中。
第九行:拷贝存活对象到新的Region耗时。
第十行:GC线程完成任务之后尝试结束到真正结束的耗时。GC线程结束前会检查其它线程是否有未完成的任务,如果有则会协助完成之后再结束。
第十一行:线程花费在其他工作上的时间,
第十二行:并行阶段的GC时间总和,包含GC以及GC Worker Other时间(47.1+317.3+7.7+0.3+783.9+171.5+5.9)。
第十三行:GC线程结束时间,Min最小值、Avg平均值、Max最大值、Diff偏移平均的值(Max-Min)
第十四行:修复GC期间code root指针改变的耗时。
第十五行:清除code root耗时,root中已经失效,不再指向Region中对象的引用。
第十六行:清除card tables 中的dirty card的耗时。
第十七行:其它GC活动耗时。
第十八行:选择要进行回收的分区放入CSet(G1选择的标准是垃圾最多的分区优先,也就是存活对象率最低的分区优先)
第十九行:处理各种引用——soft、weak、final、phantom、JNI等。
第二十行:遍历所有的引用,将不能回收的放入pending列表。
第二十一行:在回收过程中被修改的card将会被重置为dirty。
第二十二行:JDK8特性,巨型对象可以在新生代收集的时候被回收,可以通过G1ReclaimDeadHumongousObjectsAtYoungGC进行配置,默认为true。
第二十三行:释放CSet,将要释放的分区还回到free列表。
第二十四行:年轻代回收状态,Eden区满,执行回收,回收后占用为0,且Eden区大小重新调整(G1根据预测算法动态调整);Survivors变小说明有提升;Heap收集前内存占用及最大值,GC收集后内存占用及最大值。最大值由Xmx配置,保持不变。
第二十五行:user:垃圾收集线程在新生代垃圾收集过程中消耗的CPU时间,这个时间跟垃圾收集线程的个数有关,可能会比real time大很多;sys:内核态线程消耗的CPU时间;real:本次垃圾收集真正消耗的时间。
四、分析工具
1、个人推荐gcviewer,图形化展示各个收集指标,另附Summary、Memory及Pause等明细统计,可以查看gc次数,总的GC耗时,最大、最小耗时、吞吐量等等:
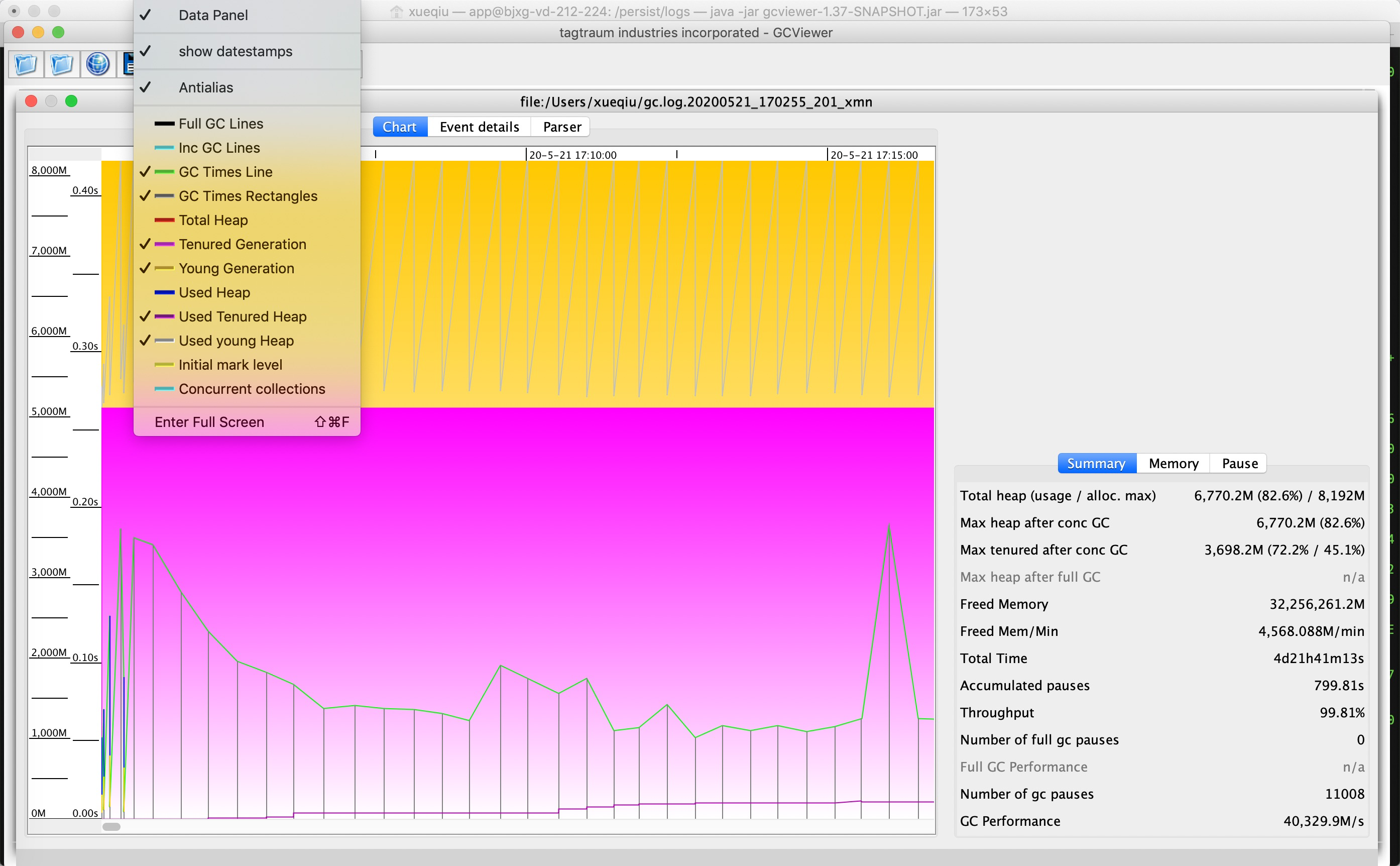
2、在线工具:https://gceasy.io/,可以上传GC日志生成GC报告,下图为报告中的关于GC耗时分布统计:

G1 垃圾回收器简单调优的更多相关文章
- G1垃圾回收器在并发场景调优
一.序言 目前企业级主流使用的Java版本是8,垃圾回收器支持手动修改为G1,G1垃圾回收器是Java 11的默认设置,因此G1垃圾回收器可以用很长时间,现阶段垃圾回收器优化意味着针对G1垃圾回收器优 ...
- G1垃圾回收器
垃圾回收器的发展历程 背景 01.G1解决的问题 G1垃圾回收器是04年正式提出,12开始正式支持,在17年作为JDK9默认的垃圾处理器. 在04年的时候,java程序堆的内存越来越大,从而导致程序中 ...
- 深入浅出具有划时代意义的G1垃圾回收器
G1诞生的背景 Garbage First(简称G1)收集器是垃圾收集器技术发展历史上的里程碑式的成果,它开创了收集器面向局部收集的设计思路和基于Region的内存布局形式.HotSpot开发团队最初 ...
- JVM学习——G1垃圾回收器(学习过程)
JVM学习--G1垃圾回收器 把这个跨时代的垃圾回收器的笔记独立出来. 新生代:适用复制算法 老年代:适用标记清除.标记整理算法 二娃本来看G1的时候觉得比较枯燥,但是后来总结完之后告诉我说,一定要慢 ...
- 探索G1垃圾回收器
前言 最近王子因为个人原因有些忙碌,导致文章更新比较慢,希望大家理解,之后也会持续和小伙伴们一起共同分享技术干货. 上篇JVM的文章中我们对ParNew和CMS垃圾回收器已经有了一个比较透彻的认识,感 ...
- JAVA之G1垃圾回收器
概述 G1 GC,全称Garbage-First Garbage Collector,通过-XX:+UseG1GC参数来启用,作为体验版随着JDK 6u14版本面世,在JDK 7u4版本发行时被正式推 ...
- jvm默认的并行垃圾回收器和G1垃圾回收器性能对比
http://www.importnew.com/13827.html 参数如下: JAVA_OPTS="-server -Xms1024m -Xmx1024m -Xss256k -XX:M ...
- tomcat如何简单调优
我们在javaEE开发的过程中,经常会进行tomcat调优操作,下面我们来简单讲解一下tomcat调优. 1) 去掉web.xml的监视,提前将jsp编译成servlet. 2)在物理内存允许的范围内 ...
- 026.Zabbix简单调优
一 调优相关对应项 Zabbix busy trapper processes, in % StartTrappers=5 Zabbix busy poller processes, in % Sta ...
随机推荐
- #Week8 Advice for applying ML & ML System Design
一.Evaluating a Learning Algorithm 训练后测试时如果发现模型表现很差,可以有很多种方法去更改: 用更多的训练样本: 减少/增加特征数目: 尝试多项式特征: 增大/减小正 ...
- pyhton中绘制多个图像
1,在python的图像学习中,有时我们需要在同一个窗口中,显示多个图像,方便我们查看输出图像的区别. 2,在pycharm中,导入matplotlibmokuai,据说此模块来自matlab,因为没 ...
- Centos 搭建wordpress个人博客
1.装apache.mariadb yum install httpd mariadb-server php php-mysql -ysystemctl start httpdsystemctl en ...
- 王颖奇 201771010129《面向对象程序设计(java)》第六周学习总结
实验六 继承定义与使用 实验时间 2018-9-28 1.目的与要求 理论部分: 继承(inheritance): 继承的特点:具有结构层次:子类继承了父类的域和方法. 主要内容: (1)类.子类.超 ...
- Vulnhb 靶场系列:Jarbas1.0
靶场镜像 官网 信息收集 攻击机kali IP地址 通过nmap 进行主机发现,发现目标机IP地址 nmap -sP 192.168.227.1/24 参数说明: -sP (Ping扫描) 该选项告诉 ...
- uCOS2014.1.9
卢友亮P69 ptcb->OSTCBStat |= OS_STAT_SUSPEND; /*标志任务被挂起*/ 这句是标志人物被挂起成阻塞态的关键. OSTCBStat //任务的当前状态标志 ...
- python实现边缘提取
1. 题目描述 安装opencv环境,实现边缘提取 2. 实现过程 1. 安装opencv+python环境 2. 打开图片 3. 将图片二值化 4. 提取边缘 5. 显示图片 3. 运行结果 ...
- at命令用法详解
在linux系统中你可能已经发现了为什么系统常常会自动的进行一些任务?这些任务到底是谁在支配他们工作的? 在linux系统如果你想要让自己设计的备份程序可以自动在某个时间点开始在系统底下运行,而不需要 ...
- 我的linux学习日记day2
RPM 软件包管理器 目的:降低软件安装难度原理 :将软件源代码加上一套安装规则打包到一起,用户只需要运行RPM systemctl start 服务名称 开启服务systemctl stop 服务 ...
- 垃圾收集器与内存分配策略——深入理解Java虚拟机 笔记二
在本篇中,作者大量篇幅介绍了当时较为流行的垃圾回收器,但现在Java 14都发布了,垃圾收集器也是有了很大的进步和发展,因此在此就不再对垃圾收集器进行详细的研究.但其基本的算法思想还是值得我们参考学习 ...