一篇文章教会你用Python抓取抖音app热点数据
今天给大家分享一篇简单的安卓app数据分析及抓取方法。以抖音为例,我们想要抓取抖音的热点榜数据。
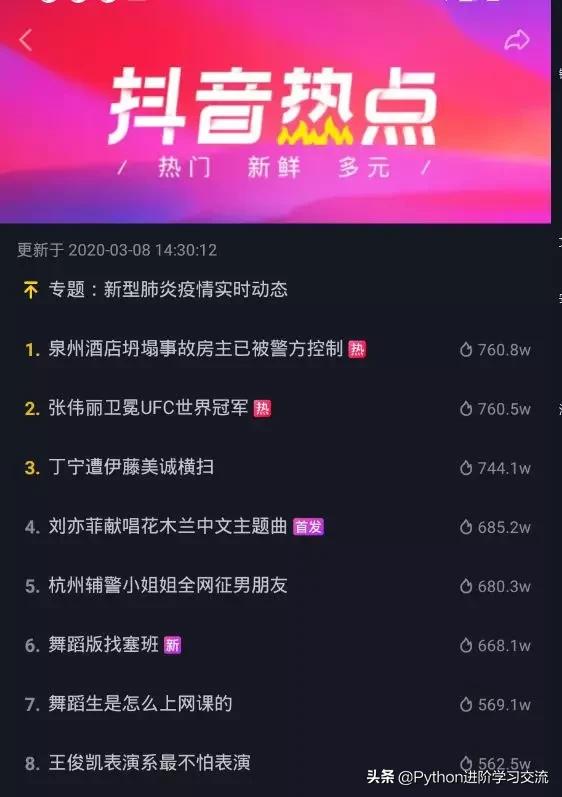
要知道,这个数据是没有网页版的,只能从手机端下手。
首先我们要安装charles抓包APP数据,它是一款收费的抓包修改工具,易上手,数据请求容易控制,修改简单,抓取数据的开始暂停方便等优势,网上也有汉化版,下载地址为
http://www.zdfans.com/html/42074.html,一路默认安装就ok了。
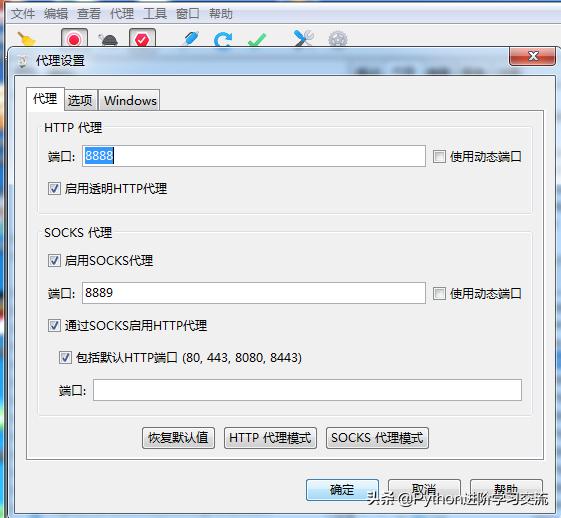
安装完成后要设置代理,依次点击代理——代理设置。
然后在手机端设置代理,如下图所示:
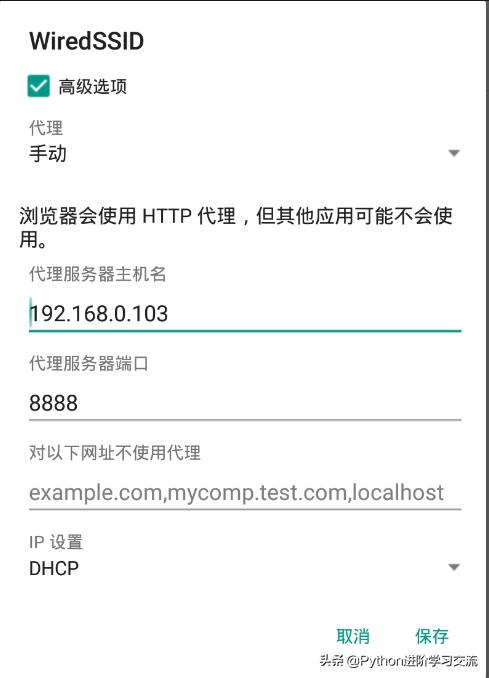
在保证手机和电脑在同一局域网的情况下,代理服务器主机名设为电脑的ip地址,端口设为8888。
最后在电脑端和手机端分别安装证书。
电脑端安装方法:依次点击帮助——ssl代理——安装charles root证书 ,按下图进行安装。

手机端安装方式:帮助——ssl代理——在移动设备或远程浏览器上安装charles root证书。
再在模拟器浏览器中输入chls.pro/ssl,会自动下载手机端证书
最后再手机端依次点击设置——安全——从SD卡安装。
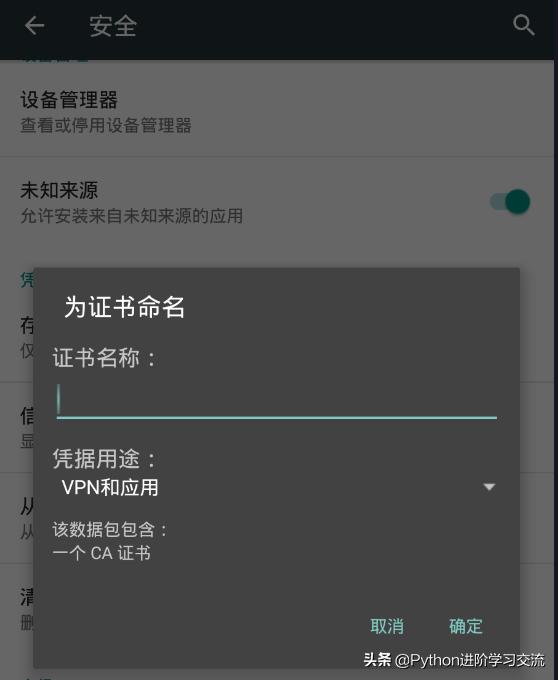
为证书命名,点击确认就安装成功了。
打开charles,然后打开抖音app的热点榜界面,在charles很容易就找到了数据接口,一次就返回了50条数据,如下图所示。
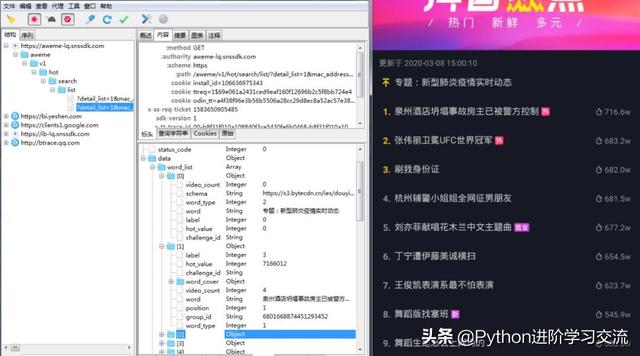
它的url信息如下图所示。
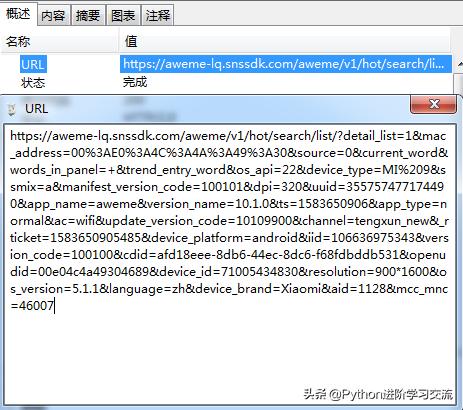
此接口只能返回这一时刻的热点数据,要想返回新的数据,就要变换参数信息,但是App端的数据接口参数都比较复杂,这里我们不再深入分析。
为了解决这一问题,我们可以用appium定时模拟操控手机,然后用mitmproxy把数据拦截下来(关于appium、mitmproxy的简介与安装网上有很多教程,这里不再赘述)
Appium脚本如下图所示:
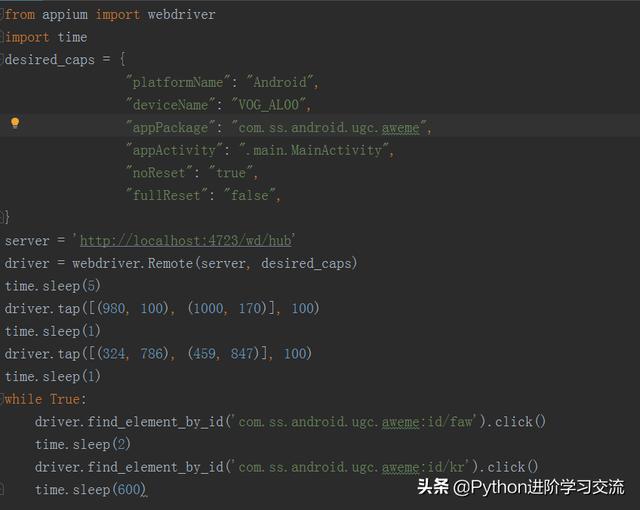
这个自动化测试脚本比较简单,主要是重复获取热点最新信息。
Mitmproxy脚本如图:
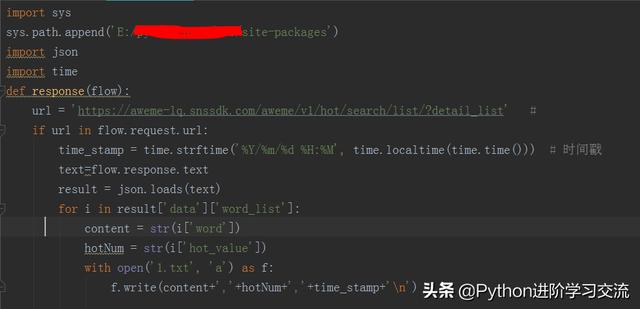
有4点需要注意的地方:
1.用mitmproxy抓包前,先把手机代理ip端口设置为8080,设置方法同上;
2.要想在此脚本运行外置函数,必须加上前两行,要不然会出错;
3.脚本中if url in flow.request.url为数据流判断条件,如果url在该数据流的url请求数据中,则判断该数据为抖音app热点数据;
4.最后在脚本所在路径运行以下程序:

最后再运行appium自动化测试脚本,就大功告成了。
如果需要本文的代码,请在后台回复“抖音”二字,觉得不错,记得给个star噢~
看完本文有收获?请转发分享给更多的人
IT共享之家

入群请在微信后台回复【入群】
想学习更多Python网络爬虫与数据挖掘知识,可前往专业网站:http://pdcfighting.com/
一篇文章教会你用Python抓取抖音app热点数据的更多相关文章
- python爬取抖音APP视频教程
本文讲述爬取抖音APP视频数据(本文未完,后面还有很多地方优化总结) 公众号回复:抖音 即可获取源码 1.APP抓包教程,需要用到fiddler fiddler配置和使用查看>>王者荣耀盒 ...
- 教你用python爬取抖音app视频
记录一下如何用python爬取app数据,本文以爬取抖音视频app为例. 编程工具:pycharm app抓包工具:mitmproxy app自动化工具:appium 运行环境:windows10 思 ...
- 一篇文章教会你用Python爬取淘宝评论数据(写在记事本)
[一.项目简介] 本文主要目标是采集淘宝的评价,找出客户所需要的功能.统计客户评价上面夸哪个功能多,比如防水,容量大,好看等等. 很多人学习python,不知道从何学起.很多人学习python,掌握了 ...
- 一篇文章教会你利用Python网络爬虫获取电影天堂视频下载链接
[一.项目背景] 相信大家都有一种头疼的体验,要下载电影特别费劲,对吧?要一部一部的下载,而且不能直观的知道最近电影更新的状态. 今天小编以电影天堂为例,带大家更直观的去看自己喜欢的电影,并且下载下来 ...
- from appium import webdriver 使用python爬虫,批量爬取抖音app视频(requests+Fiddler+appium)
使用python爬虫,批量爬取抖音app视频(requests+Fiddler+appium) - 北平吴彦祖 - 博客园 https://www.cnblogs.com/stevenshushu/p ...
- python+fiddler 抓取抖音数据包并下载抖音视频
这个我们要下载视频,那么肯定首先去找抖音视频的url地址,那么这个地址肯定在json格式的数据包中,所以我们就去专门查看json格式数据包 这个怎么找我就不用了,直接看结果吧 你找json包,可以选大 ...
- 使用python爬虫,批量爬取抖音app视频(requests+Fiddler+appium)
抖音很火,楼主使用python随机爬取抖音视频,并且无水印下载,人家都说天下没有爬不到的数据,so,楼主决定试试水,纯属技术爱好,分享给大家.. 1.楼主首先使用Fiddler4来抓取手机抖音app这 ...
- 一篇文章教会你使用Python定时抓取微博评论
[Part1--理论篇] 试想一个问题,如果我们要抓取某个微博大V微博的评论数据,应该怎么实现呢?最简单的做法就是找到微博评论数据接口,然后通过改变参数来获取最新数据并保存.首先从微博api寻找抓取评 ...
- 手把手教你用Python抓取AWS的日志(CloudTrail)数据
数据时代,利用数据做决策是大数据的核心价值. 本文手把手,教你使用python进行AWS的CloudTrail配置,进行日志抓取.进行数据分析,发现数据价值! 如今是云的时代,许多公司都把自己的IT架 ...
随机推荐
- phantomJS安装出错解决办法
解决办法:https://github.com/xhlwill/blog/issues/11
- 04 返回静态文件的函数web框架
04 返回静态文件的函数web框架 服务器server端python程序(函数版): import socket server = socket.socket() server.bind((" ...
- 点击劫持ClickJacking
原文:https://beenle-xiaojie.github.io/2019/01/07/ClickJacking/ 引言 当我们的页面嵌入到一个iframe中时,安全测试提出一个于我而言很新鲜的 ...
- ShoneSharp语言(S#)的设计和使用介绍系列(5)— 数值Double
ShoneSharp语言(S#)的设计和使用介绍 系列(5)— 数值Double 作者:Shone 声明:原创文章欢迎转载,但请注明出处,https://www.cnblogs.com/ShoneSh ...
- Flutter “孔雀开屏”的动画效果
老孟导读:今天分享一个类似"孔雀开屏"的动画效果,打开新的页面时,新的页面从屏幕右上角以圆形逐渐打开到全屏. 先来看下具体的效果 不知道这种效果大家叫什么名字?如果有更合适的名字可 ...
- overflow:hidden的清除浮动效果
我们都知道"overflow:hidden"可以溢出隐藏,即当内容元素的高度大于其包含块的高度时,设置该属性即可把内容区域超出来的部分隐藏,使内容区域完全包含在该包含块中. 然而& ...
- Verilog代码和FPGA硬件的映射关系(四)
其实在FPGA的开发中理想情况下FPGA之间的数据要通过寄存器输入.输出,这样才能使得延时最小,从而更容易满足建立时间要求.我们在FPGA内部硬件结构中得知,IOB内是有寄存器的,且IOB内的寄存器比 ...
- JSP+SSM+Mysql实现的图书馆预约占座管理系统
项目简介 项目来源于:https://gitee.com/gepanjiang/LibrarySeats 因原gitee仓库无数据库文件且存在水印,经过本人修改,现将该仓库重新上传至个人gitee仓库 ...
- react中路由不起作用的奇怪现象
同样的两段Router代码,为什么一段正常,一段不起作用(也没有任何错误log提示) 瞪着眼观察也看不出为什么... 通过选中高亮显示内容相同, 为何就是有一段路由不管用呢? 折腾半天发现... 大小 ...
- SpringBoot 安全管理(一)
SpringBoot 安全管理(一) 一.springSecurity入门 添加依赖 <dependency> <groupId>org.springframework.boo ...