【Spark】RDD的依赖关系和缓存相关知识点
RDD的依赖关系
RDD和它依赖的父RDD的关系有两种不同的类型,即窄依赖(narrow dependency) 和宽依赖(wide dependency)。
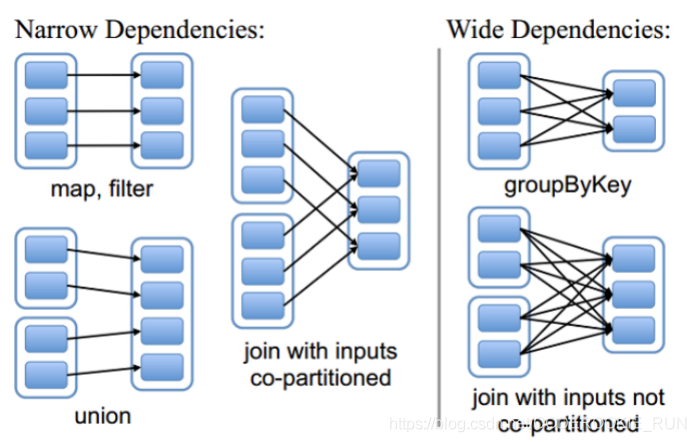
宽依赖
宽依赖指的是子RDD中的数据来源于父RDD中的多个分区,其实就是产生了shuffle
窄依赖
窄依赖指的是子RDD中的数据来源于父RDD当中的一个分区,也即没有产生shuffle
血统
Lineage —— 根据rdd之间的依赖关系,将依赖关系给记录下来叫做血统。
比如:
rdd1 ==> rdd2 ==> rdd3 ==> rdd4
记录下来每一个rdd的父rdd是谁,也记录下来每一个rdd的子rdd是谁,可以帮助我们做容灾
RDD缓存
概述
Spark速度非常快的原因之一,就是在不同操作中可以在内存中持久化或者缓存数据集。当持久化某个RDD后,每一个节点都将把计算分区结果保存在内存中,对此RDD或衍生出的RDD进行的其他动作中重用。这使得后续的动作变得更加迅速。RDD相关的持久化和缓存,是Spark最重要的特征之一。可以说,缓存是Spark构建迭代式算法和快速交互式查询的关键。
缓存方式
通过查看StorageLevel的源码可以拿到
object StorageLevel {
//不缓存
val NONE = new StorageLevel(false, false, false, false)
//只在硬盘缓存
val DISK_ONLY = new StorageLevel(true, false, false, false)
//在硬盘缓存两份
val DISK_ONLY_2 = new StorageLevel(true, false, false, false, 2)
//只在内存缓存
val MEMORY_ONLY = new StorageLevel(false, true, false, true)
//在内存缓存两份
val MEMORY_ONLY_2 = new StorageLevel(false, true, false, true, 2)
//在内存序列化缓存
val MEMORY_ONLY_SER = new StorageLevel(false, true, false, false)
//在内存序列化缓存两份
val MEMORY_ONLY_SER_2 = new StorageLevel(false, true, false, false, 2)
//同时在内存和硬盘缓存
val MEMORY_AND_DISK = new StorageLevel(true, true, false, true)
//同时在内存和硬盘缓存两份(推荐)
val MEMORY_AND_DISK_2 = new StorageLevel(true, true, false, true, 2)
//同时在内存和硬盘序列化缓存
val MEMORY_AND_DISK_SER = new StorageLevel(true, true, false, false)
//同时在内存和硬盘序列化缓存两份
val MEMORY_AND_DISK_SER_2 = new StorageLevel(true, true, false, false, 2)
//对外内存
val OFF_HEAP = new StorageLevel(false, false, true, false)
......
}
两种方法:
1.cache(),其实底层就是调用了persist,将数据仅仅的放到内存里面去,放一份
2.persist()
(1)无参,也是将只在内存中缓存一份数据
(2)带StorageLevel参数,一般选择MEMORY_AND_DISK_2
【Spark】RDD的依赖关系和缓存相关知识点的更多相关文章
- 大数据学习day23-----spark06--------1. Spark执行流程(知识补充:RDD的依赖关系)2. Repartition和coalesce算子的区别 3.触发多次actions时,速度不一样 4. RDD的深入理解(错误例子,RDD数据是如何获取的)5 购物的相关计算
1. Spark执行流程 知识补充:RDD的依赖关系 RDD的依赖关系分为两类:窄依赖(Narrow Dependency)和宽依赖(Shuffle Dependency) (1)窄依赖 窄依赖指的是 ...
- sparkRDD:第4节 RDD的依赖关系;第5节 RDD的缓存机制;第6节 DAG的生成
4. RDD的依赖关系 6.1 RDD的依赖 RDD和它依赖的父RDD的关系有两种不同的类型,即窄依赖(narrow dependency)和宽依赖(wide dependency ...
- Spark RDD概念学习系列之RDD的依赖关系(宽依赖和窄依赖)(三)
RDD的依赖关系? RDD和它依赖的parent RDD(s)的关系有两种不同的类型,即窄依赖(narrow dependency)和宽依赖(wide dependency). 1)窄依赖指的是每 ...
- RDD的依赖关系
RDD的依赖关系 Rdd之间的依赖关系通过rdd中的getDependencies来进行表示, 在提交job后,会通过在DAGShuduler.submitStage-->getMissingP ...
- 021 RDD的依赖关系,以及造成的stage的划分
一:RDD的依赖关系 1.在代码中观察 val data = Array(1, 2, 3, 4, 5) val distData = sc.parallelize(data) val resultRD ...
- Spark RDD 窄依赖研究
1.. 简介 spark从RDD依赖上来说分为窄依赖和宽依赖. 其中可以这样区分是哪种依赖:当父RDD的一个partition被子RDD的多个partitions引用到的时候则说明是宽依赖,否则为窄依 ...
- Spark RDD概念学习系列之rdd的依赖关系彻底解密(十九)
本期内容: 1.RDD依赖关系的本质内幕 2.依赖关系下的数据流视图 3.经典的RDD依赖关系解析 4.RDD依赖关系源码内幕 1.RDD依赖关系的本质内幕 由于RDD是粗粒度的操作数据集,每个Tra ...
- Spark RDD的依赖解读
在Spark中, RDD是有依赖关系的,这种依赖关系有两种类型 窄依赖(Narrow Dependency) 宽依赖(Wide Dependency) 以下图说明RDD的窄依赖和宽依赖 窄依赖 窄依赖 ...
- spark rdd 宽窄依赖理解
== 转载 == http://blog.csdn.net/houmou/article/details/52531205 Spark中RDD的高效与DAG图有着莫大的关系,在DAG调度中需要对计算过 ...
随机推荐
- Vue + d3.js实现在地图上选点
需求:用户在地图上单击选点,页面获取到具体坐标并返回. 首先比较重要的是Vue中的$nextTick,因为vue是异步更新的,如果是想打开Dialog或者是其他操作dom后才加载地图,使用nextTi ...
- Xor Path 牛客,HPU--C--LCA
题解: 题目要求求出u和v两点在最短路径上的异或和.怎么确定最短路径呢?,就是U到LCA(u,v)的路径加上V到LCA(u,v).根据异或的性质,如k^a^a=k,即异或一个值两边等于原数值. 所以维 ...
- 如何用Github钩子做自动部署
最近机缘巧合的购置了域名和服务器,不用实在是浪费,再加上一直没有属于自己的个人网站,所以打算用hexo在服务器上玩一下,这样也就不用再纠结用Github pages还是Gitee pages了.当然, ...
- 模拟HTTP请求调用controller
原文参考本人的简书:https://www.jianshu.com/p/0221edbe1598 MockMvc实现了对Http请求的模拟,能够直接使用网络的形式,转换到Controller调用,这样 ...
- SweetAlert - 演示6种不同的提示框效果
http://www.sucaihuo.com/js/190.html http://www.cnblogs.com/beiz/p/5238124.html
- golang/beego 微信模版消息
// GO的微信SDK我用的是这个:https://github.com/silenceper/wechat // 发送模版消息 // UserNickName,UserMobile是发起预约的人的昵 ...
- (第五篇)Linux操作系统基本结构介绍
Linux操作系统基本结构介绍 Linux系统一般有4个主要部分:内核.shell.文件系统和应用程序.内核.shell和文件系统一起形成了基本的操作系统结构,它们使得用户可以运行程序.管理文件并使用 ...
- [Linux] 检查是否已有进程在运行
出处:sblim-sfcb-1.4.9 / sfcBroker.c int process_is_running() { #define STRBUF_LEN 512 #define BUF_LEN ...
- Spring5参考指南:AspectJ高级编程之Configurable
文章目录 遇到的问题 @Configurable 原理 重要配置 遇到的问题 前面的文章我们讲到了在Spring中使用Aspect.但是Aspect的都是Spring管理的Bean. 现在有一个问题, ...
- 《Redis设计与实现》之第十二章:事件
Redis服务器是一个事件驱动程序,服务器需要处理两类事件: 文件事件: 文件事件就是服务器对套接字(socket)操作的抽象,服务器和客户端的通信会产生文件事件 时间事件: 时间事件就是服务器对定时 ...