Python读取和写入文件
1 从文件中读取数据
1.1 读取整个文件
创建名为test的txt文本文件,添加内容如下所示:
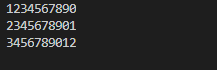
1234567890
2345678901
3456789012
实现代码:
with open('test.txt') as file_object:
contents = file_object.read()
print(contents)
运行结果:
工作原理:
#1 open()方法用于打开一个文件:输入参数---文件名称(默认在当前目录中查找);返回一个表示文件的对象。
#1 关键字with:打开文件后,Python会在合适的时候将打开的文件自动关闭,避免造成不必要的麻烦。
#2 read()方法:读取文件的全部内容,并将其作为一个长字符串存储在变量contents中。
#3 打印存储在变量contents中的内容。
打印结果与原始文件相比,末尾处出现一个空行。这是因为read()方法到达文件末尾时会返回一个空字符串,而将这个空字符串显示出来时就是一个空行。
要删除多余出来的空行,可使用rstrip()函数(删除字符串末尾空白):
with open('test.txt') as file_object:
contents = file_object.read()
print(contents.rstrip())
运行结果:

1.2 文件路径
默认情况下,read()方法只会在当前目录中进行查找文件,不会在其子文件夹中查找。
如果要打开一个不在当前目录中的文件,则需要提供该文件路径,以便Python在特定路径去查找该文件。
有两种提供文件路径的方法:相对文件路径和绝对文件路径。
例如,假设Python源文件位于名为work的文件夹中,txt文件位于work的子文件夹files中。

这种情况下,我们可以提供相对文件路径来打开该文件夹中的文件:
with open('files\test.txt') as file_object:
此外,你也可以提供绝对文件路径来打开该文件夹中的文件:
with open('...\work\files\test.txt') as file_object:
当绝对文件路径比较长时,可以先将其存储在一个变量中,如file_path:
file_path = '...\work\files\test.txt'
with open(file_path) as file_object:
1.3 逐行读取
实现代码:
filename = 'test.txt' with open(filename) as file_object:
for line in file_object:
print(line)
运行结果:

运行后发现每行文本之后都有空行,原因是:1. 文件中每行末尾都有一个看不见的换行符;2. print语句也会加上一个换行符。
因此每行文本后面都会跟随两个换行符:一个来自文件;一个来自print语句。
同样地,要消除这些空白行,可以在print语句中加入rstrip():
filename = 'test.txt' with open(filename) as file_object:
for line in file_object:
print(line.rstrip())
运行结果:

1.4 创建一个包含文件各行内容的列表
使用关键字with时,open()返回的文件对象只在with代码块内可用。
若要在with代码块之外访问文件内容,可在with代码块内将文件的各行内容存储在一个列表中,并在with代码块外使用该列表。
实现代码:
filename = 'test.txt' with open(filename) as file_object:
lines = file_object.readlines() for line in lines:
print(line.rstrip())
运行结果:
工作原理:
#4 readlines()从文件中读取每一行,并将其存储在一个列表中,再传递给变量lines。
当文件内容被读取到内存后,你就可以以任何方式使用这些数据了。
2 写入数据到文件中
2.1 写入空文件
要将文本写入文件,需要在调用open()时提供另一个实参,以告知Python你要写入打开的文件。
实现代码:
filename = 'test.txt' with open(filename, 'w') as file_object:
file_object.write("Hello World!")
工作原理:
#3 open()提供了两个参数:1. 打开文件名称;2. 'w'告知Python以写入模式打开文件。
#4 write()方法将一个字符串写入文件。
[注1]:'r'表示只读模式,'a'表示附加模式,'r+'表示读取和写入模式。若省略此实参,Python将以默认的只读模式打开文件。
[注2]:若要写入的文件不存在,open()函数将自动创建它。
[注3]:千万小心,若指定文件已存在,Python将在返回文件对象之前清空该文件。
2.2 写入多行
函数write()不会在你写入的文本末尾添加换行符,因此,如果你写入多行时没有指定换行符,文件看起来可能不会那么的井然有序。
要让每个字符串单独占据一行,可以在write()语句中包含换行符。
实现代码:
filename = 'test.txt' with open(filename, 'w') as file_object:
file_object.write("Hello World!\n")
file_object.write("my great friends.\n")
当然,你还可以使用空格、制表符和空行等来设置写入文本的格式。
2.3 附加到文件
如果你要给文件添加内容,而不是覆盖原有的内容,可以附加模式打开文件。
当你以附加模式打开文件时,Python不会在返回文件对象前清空文件,而你写入到文件的行都将添加到文件末尾。
如果指定的文件不存在,Python将为你创建一个空文件。
实现代码:
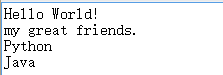
filename = 'test.txt' with open(filename, 'a') as file_object:
file_object.write("Python\n")
file_object.write("Java\n")
运行结果:
Python读取和写入文件的更多相关文章
- python读取与写入csv,txt格式文件
python读取与写入csv,txt格式文件 在数据分析中经常需要从csv格式的文件中存取数据以及将数据写书到csv文件中.将csv文件中的数据直接读取为dict类型和DataFrame是非常方便也很 ...
- 读取和写入 文件 (NSFIleManger 与 NSFileHandle)
读取和写入 文件 //传递文件路径方法 -(id)initPath:(NSString *)srcPath targetPath:(NSString *)targetPath { self = [su ...
- python读取Excel表格文件
python读取Excel表格文件,例如获取这个文件的数据 python读取Excel表格文件,需要如下步骤: 1.安装Excel读取数据的库-----xlrd 直接pip install xlrd安 ...
- python读取和写入csv文件
读取csv文件: def readCsv(): rows=[] with file(r'E:\py\py01\Data\system.csv','rb') as f: reads=csv.reader ...
- python读取并写入mat文件
用matlab生成一个示例mat文件: clear;clc matrix1 = magic(5); matrix2 = magic(6); save matData.mat 用python3读取并写入 ...
- python将对象写入文件,以及从文件中读取对象
原文地址: http://www.voidcn.com/article/p-fqtqpwxp-wo.html 写入文件代码: >>> import sys, shelve >& ...
- python读取/创建XML文件
Python中定义了很多处理XML的函数,如xml.dom,它会在处理文件之前,将根据xml文件构建的树状数据存在内存.还有xml.sax,它实现了SAX API,这个模块牺牲了便捷性,换取了速度和减 ...
- python读取、写入txt文本内容
转载:https://blog.csdn.net/qq_37828488/article/details/100024924 python常用的读取文件函数有三种read().readline().r ...
- 【转】MFC中用CFile读取和写入文件2
原文网址:http://blog.sina.com.cn/s/blog_623a7fa40100hh1u.html CFile提供了一些常用的操作函数,如表1-2所示. 表1-2 CFile操作函数 ...
随机推荐
- Python - 使用 PostgreSQL 数据库
基本用法 # -*- coding: utf-8 -*- # !/usr/bin/python # 需要安装下面的驱动包 import psycopg2 # 连接到一个现有的数据库,如果数据库不存在, ...
- G - 旅行的意义(概率DP) (DAG图的概率与期望)
为什么有人永远渴望旅行,或许就因为,巧合和温暖会在下一秒蜂拥而至吧. 一直想去旅游的天天决定在即将到来的五一假期中安排一场环游世界的旅行.为此,他已经提前查阅了很多资料,并准备画一张旅游路线图.天天先 ...
- POJ3276 Face The Right Way 开关问题
①每个K从最左边进行考虑 ②f[i]=[i,i+k-1]是否进行反转:1代表是,0代表否 ③∑ (i)(i=i+1-K+1) f[j]=∑ (i-1)(i=i-K+1) f[j]+f[i]-f[i-K ...
- Outlook邮件的右键菜单中添加自定义按钮
customUI代码如下: <customUI xmlns="http://schemas.microsoft.com/office/2009/07/customui"> ...
- 网页元素检测工具:Spy_for_InternetExplorer下载地址
本工具用于实时查看IE浏览器中打开的网页中元素的信息.支持iframe.frame框架. 下载地址: Spy_for_InternetExplorer.rar
- shell、cmd、dos和脚本语言
问题一:Shell是什么? 操作系统可以分成核心(kernel)和Shell(外壳)两部分,其中,Shell是操作系统与外部的主要接口,位于操作系统的外层,为用户提供与操作系统核心沟通的途径.Shel ...
- JS UTC 昨天
var birthday = new Date("Jan 01, 1983 01:15:00") var formatDate = function (date) { ...
- 学习python-20191108(2)REST接口相关
一.客户登录验证 在使用接口前,需要对客户进行登录验证 enums.py文件代码: #定义枚举,客户端登录的方式有很多种形式:邮箱登录.手机登录.微信小程序登录.微信公众号登录 class Clien ...
- echart封装,前端简单路由,图表设置自动化
https://github.com/cclient/EhartDemoSetByAngular 后端node.js 前端插件 echart,jquery,jqueryui,datapicker,an ...
- 瑞星发布Linux系统安全报告:Linux病毒或将大面积爆发
近半年来,由于中央推荐使用国产Linux操作系统,国产Linux操作系统开始受到政府机关及大型企事业机关单位的高度重视.很多人都认为,以Linux系统为基础的国产操作系统最符合国家.政府和企业信息安全 ...