TensorFlow从0到1之TensorFlow优化器(13)
高中数学学过,函数在一阶导数为零的地方达到其最大值和最小值。梯度下降算法基于相同的原理,即调整系数(权重和偏置)使损失函数的梯度下降。
在回归中,使用梯度下降来优化损失函数并获得系数。本节将介绍如何使用 TensorFlow 的梯度下降优化器及其变体。
按照损失函数的负梯度成比例地对系数(W 和 b)进行更新。根据训练样本的大小,有三种梯度下降的变体:
- Vanilla 梯度下降:在 Vanilla 梯度下降(也称作批梯度下降)中,在每个循环中计算整个训练集的损失函数的梯度。该方法可能很慢并且难以处理非常大的数据集。该方法能保证收敛到凸损失函数的全局最小值,但对于非凸损失函数可能会稳定在局部极小值处。
- 随机梯度下降:在随机梯度下降中,一次提供一个训练样本用于更新权重和偏置,从而使损失函数的梯度减小,然后再转向下一个训练样本。整个过程重复了若干个循环。由于每次更新一次,所以它比 Vanilla 快,但由于频繁更新,所以损失函数值的方差会比较大。
- 小批量梯度下降:该方法结合了前两者的优点,利用一批训练样本来更新参数。
TensorFlow优化器的使用
首先确定想用的优化器。TensorFlow 为你提供了各种各样的优化器:
- 这里从最流行、最简单的梯度下降优化器开始:
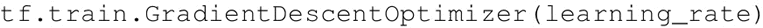
GradientDescentOptimizer 中的 learning_rate 参数可以是一个常数或张量。它的值介于 0 和 1 之间。
必须为优化器给定要优化的函数。使用它的方法实现最小化。该方法计算梯度并将梯度应用于系数的学习。该函数在 TensorFlow 文档中的定义如下:

综上所述,这里定义计算图:

馈送给 feed_dict 的 X 和 Y 数据可以是 X 和 Y 个点(随机梯度)、整个训练集(Vanilla)或成批次的。
- 梯度下降中的另一个变化是增加了动量项。为此,使用优化器 tf.train.MomentumOptimizer()。它可以把 learning_rate 和 momentum 作为初始化参数:
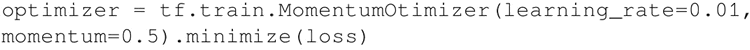
- 可以使用 tf.train.AdadeltaOptimizer() 来实现一个自适应的、单调递减的学习率,它使用两个初始化参数 learning_rate 和衰减因子 rho:

- TensorFlow 也支持 Hinton 的 RMSprop,其工作方式类似于 Adadelta 的 tf.train.RMSpropOptimizer():
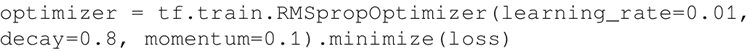
Adadelta 和 RMSprop 之间的细微不同可参考 http://www.cs.toronto.edu/~tijmen/csc321/slides/lecture_slides_lec6.pdf 和 https://arxiv.org/pdf/1212.5701.pdf。
- 另一种 TensorFlow 支持的常用优化器是 Adam 优化器。该方法利用梯度的一阶和二阶矩对不同的系数计算不同的自适应学习率:
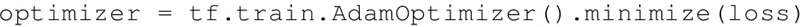
- 除此之外,TensorFlow 还提供了以下优化器:

通常建议你从较大学习率开始,并在学习过程中将其降低。这有助于对训练进行微调。可以使用 TensorFlow 中的 tf.train.exponential_decay 方法来实现这一点。
根据 TensorFlow 文档,在训练模型时,通常建议在训练过程中降低学习率。该函数利用指数衰减函数初始化学习率。需要一个 global_step 值来计算衰减的学习率。可以传递一个在每个训练步骤中递增的 TensorFlow 变量。函数返回衰减的学习率。
变量:
- learning_rate:标量float32或float64张量或者Python数字。初始学习率。
- global_step:标量int32或int64张量或者Python数字。用于衰减计算的全局步数,非负。
- decay_steps:标量int32或int64张量或者Python数字。正数,参考之前所述的衰减计算。
- decay_rate:标量float32或float64张量或者Python数字。衰减率。
- staircase:布尔值。若为真则以离散的间隔衰减学习率。
- name:字符串。可选的操作名。默认为ExponentialDecay。
返回:
- 与learning_rate类型相同的标量张量。衰减的学习率。
实现指数衰减学习率的代码如下:

推荐阅读
下面是讲解不同优化器的链接:
- https://arxiv.org/pdf/1609.04747.pdf:该文章提供了不同优化器算法的综述。
- https://www.tensorflow.org/api_guides/python/train#Optimizers:这是 TensorFlow.org 链接,详述了 TensorFlow 中优化器的使用方法。
- https://arxiv.org/pdf/1412.6980.pdf:关于 Adam 优化器的论文。
TensorFlow从0到1之TensorFlow优化器(13)的更多相关文章
- TensorFlow从0到1之TensorFlow Keras及其用法(25)
Keras 是与 TensorFlow 一起使用的更高级别的作为后端的 API.添加层就像添加一行代码一样简单.在模型架构之后,使用一行代码,你可以编译和拟合模型.之后,它可以用于预测.变量声明.占位 ...
- TensorFlow从0到1之TensorFlow多层感知机函数逼近过程(23)
Hornik 等人的工作(http://www.cs.cmu.edu/~bhiksha/courses/deeplearning/Fall.2016/notes/Sonia_Hornik.pdf)证明 ...
- TensorFlow从0到1之TensorFlow实现反向传播算法(21)
反向传播(BPN)算法是神经网络中研究最多.使用最多的算法之一,它用于将输出层中的误差传播到隐藏层的神经元,然后用于更新权重. 学习 BPN 算法可以分成以下两个过程: 正向传播:输入被馈送到网络,信 ...
- TensorFlow从0到1之TensorFlow超参数及其调整(24)
正如你目前所看到的,神经网络的性能非常依赖超参数.因此,了解这些参数如何影响网络变得至关重要. 常见的超参数是学习率.正则化器.正则化系数.隐藏层的维数.初始权重值,甚至选择什么样的优化器优化权重和偏 ...
- TensorFlow从0到1之TensorFlow多层感知机实现MINIST分类(22)
TensorFlow 支持自动求导,可以使用 TensorFlow 优化器来计算和使用梯度.它使用梯度自动更新用变量定义的张量.本节将使用 TensorFlow 优化器来训练网络. 前面章节中,我们定 ...
- TensorFlow从0到1之TensorFlow实现单层感知机(20)
简单感知机是一个单层神经网络.它使用阈值激活函数,正如 Marvin Minsky 在论文中所证明的,它只能解决线性可分的问题.虽然这限制了单层感知机只能应用于线性可分问题,但它具有学习能力已经很好了 ...
- TensorFlow从0到1之TensorFlow实现多元线性回归(16)
在 TensorFlow 实现简单线性回归的基础上,可通过在权重和占位符的声明中稍作修改来对相同的数据进行多元线性回归. 在多元线性回归的情况下,由于每个特征具有不同的值范围,归一化变得至关重要.这里 ...
- TensorFlow从0到1之TensorFlow实现简单线性回归(15)
本节将针对波士顿房价数据集的房间数量(RM)采用简单线性回归,目标是预测在最后一列(MEDV)给出的房价. 波士顿房价数据集可从http://lib.stat.cmu.edu/datasets/bos ...
- TensorFlow从0到1之TensorFlow常用激活函数(19)
每个神经元都必须有激活函数.它们为神经元提供了模拟复杂非线性数据集所必需的非线性特性.该函数取所有输入的加权和,进而生成一个输出信号.你可以把它看作输入和输出之间的转换.使用适当的激活函数,可以将输出 ...
随机推荐
- Error creating bean with name 'org.springframework.aop.aspectj.AspectJPointc
问题 出现报错: Error creating bean with name 'org.springframework.aop.aspectj.AspectJPointc 原因 缺失两个库文件: as ...
- SpringBoot系列——状态机(附完整源码)
1. 简单介绍状态机 2. 状态机的本质 3. 状态机应用场景 1. 简单介绍状态机 状态机由状态寄存器和组合逻辑电路构成,能够根据控制信号按照预先设定的状态进行状态转移,是协调相关信号动作.完成特定 ...
- 三,<ul><li>实际应用时遇到的问题
在布局中使用的比较多的就是这个,快速排列一行或多行文字,还有横排显示作为导航栏标题栏等等书写格式:<ul> <li>山东教育.....</li></ul ...
- Python 绘制全球疫情地图
国内疫情得到控制后,我就没怎么再关心过疫情,最近看到一条新闻,全球疫情累计确诊人数已经突破 500w 大关,看到这个数字我还是有点吃惊的. 思来想去,还是写一篇全球疫情的分析的文章,本文包括网络爬虫. ...
- javascript中日期的最简单格式化
// 假设要转换的日期数据来源是date(一个timestamp) let date = Date.now() // 1574141546000 let strDate = (new Date(dat ...
- Bank3
Account: package banking3; //账户 public class Account { private double balance;// 账户余额 public Account ...
- Parrot os安装nvidia失败恢复
因为两种显卡,amd和nvidia,所以按照parrot官方文档安装驱动,结果可想而知,安装失败--- 内心万马奔腾,去国外论坛也发现很多求助的小伙伴,所以有了我这次随笔,如何恢复你的parrot 黑 ...
- .NET编程5月小结 - Blazor, Unity, Dependency Injection
本文是我在5月份看到的一些有趣的内容的集合.在这里你可以找到许多有关Blazor.ASPNET Core的学习资源和示例项目,有关在Unity中使用Zenject进行单元测试的博客,有关Unity项目 ...
- Beta冲刺——5.24
这个作业属于哪个课程 软件工程 这个作业要求在哪里 Beta冲刺 这个作业的目标 Beta冲刺 作业正文 正文 github链接 项目地址 其他参考文献 无 一.会议内容 1.安排每个人进行为期3天的 ...
- Chisel3 - Tutorial - Stack
https://mp.weixin.qq.com/s/-AVJD1IfvNIJhmZM40DemA 实现后入先出(last in, first out)的栈. 参考链接: https://gi ...