入门大数据---HDFS-API
第一步:创建一个新的项目 并导入需要的jar包
公共核心包
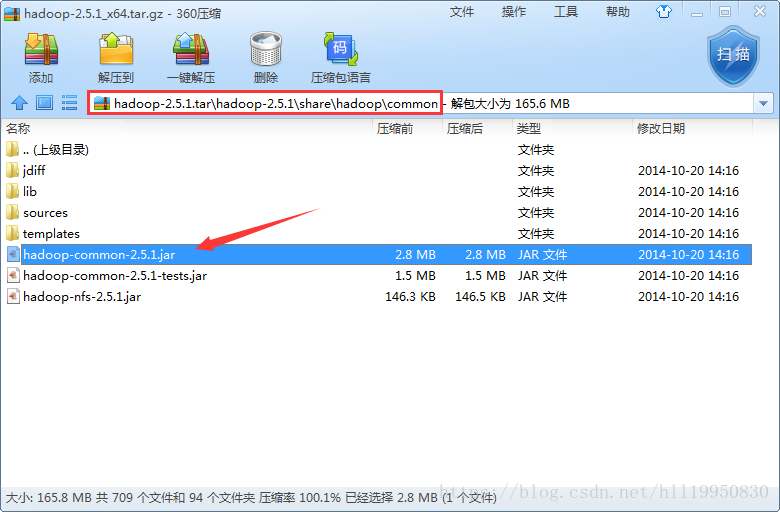
公共依赖包

hdfs核心包

hdfs依赖包
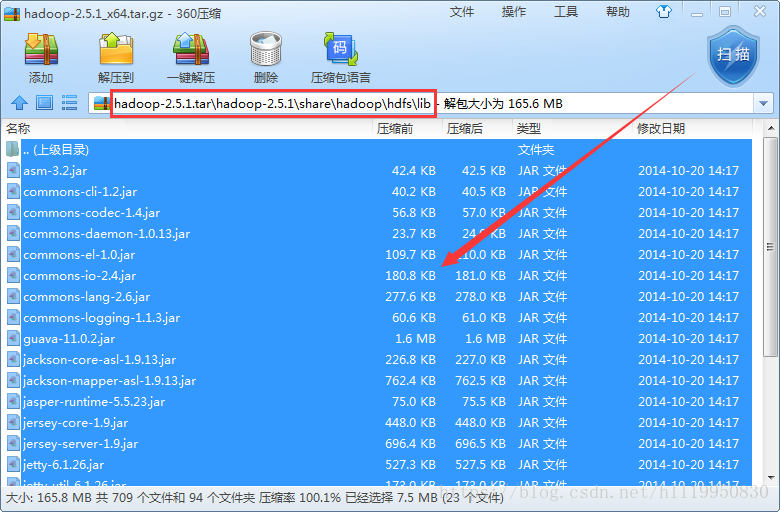
第二步:将Linux中hadoop的配置文件拷贝到项目的src目录下

第三步:配置windows本地的hadoop环境变量(HADOOP_HOME:hadoop的安装目录 Path:在后面添加hadoop下的bin目录)
第四步:使用windows下编译好的hadoop替换hadoop的bin目录和lib目录
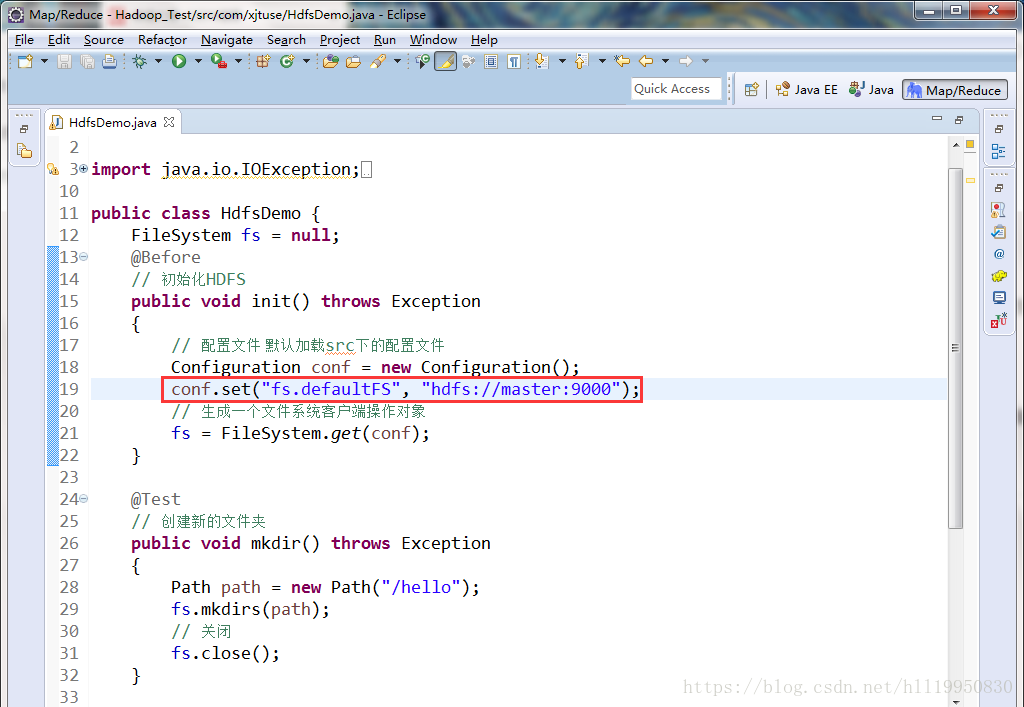
第五步:使用FileSystem对象对hdfs进行操作(注意:FileSystem默认是本地文件系统 因此要通过Configuration对象配置为hdfs系统)
第六步:在运行之前 需要保证本地的用户名和hadoop的用户名一致 在不修改windows用户名的情况下 可以配置Eclipse的参数实现:右击项目->Run As ->Run Configurations
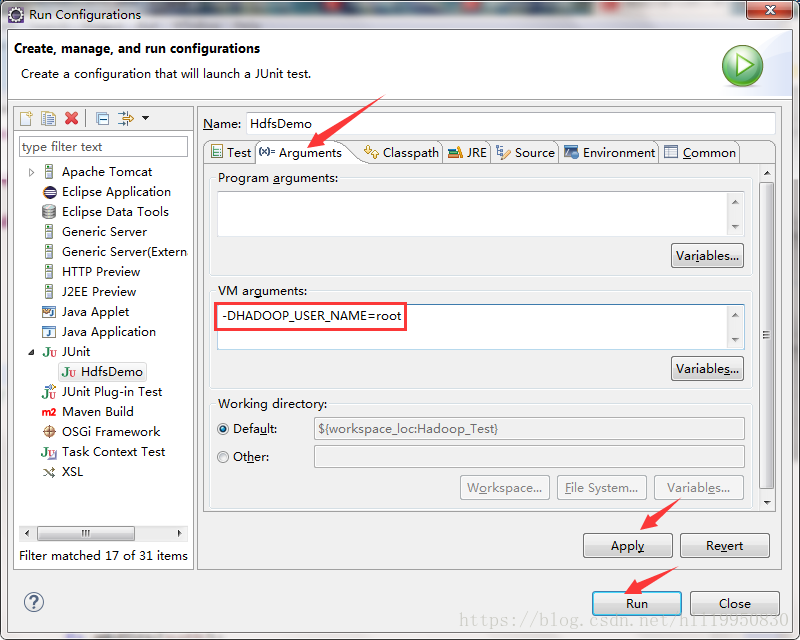
运行即可成功上传本地文件到hdfs
代码如下:
package com.xjtuse;
import java.net.URI;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import org.junit.Before;
import org.junit.Test;
public class HdfsDemo {
FileSystem fs = null;
@Before
// 初始化HDFS
public void init() throws Exception
{
// 配置文件 默认加载src下的配置文件
Configuration conf = new Configuration();
// conf.set("fs.defaultFS", "hdfs://master:9000");
// 生成一个文件系统客户端操作对象
// fs = FileSystem.get(conf);
// 第一个参数是URI指明了是hdfs文件系统 第二个参数是配置文件 第三个参数是指定用户名 需要与hadoop用户名保持一致
fs = FileSystem.get(new URI("hdfs://master:9000"), conf, "root");
}
@Test
// 创建新的文件夹
public void mkdir() throws Exception
{
Path path = new Path("/hello");
fs.mkdirs(path);
// 关闭
fs.close();
}
@Test
// 上传文件
public void upload() throws Exception
{
// 第一个参数是本地windows下的文件路径 第二个参数是hdfs的文件路径
fs.copyFromLocalFile(new Path("F:/Files/data/README.txt"), new Path("/"));
// 关闭
fs.close();
}
}
转自: https://blog.csdn.net/hll19950830/article/details/79824928
补充:最后我们运行可能报如下异常。

这个时候在项目根目录下创建一个文件命名为log4j.properties并填写如下内容,然后重新运行就好了。
hadoop.root.logger=DEBUG, console
log4j.rootLogger = DEBUG, console
log4j.appender.console=org.apache.log4j.ConsoleAppender
log4j.appender.console.target=System.out
log4j.appender.console.layout=org.apache.log4j.PatternLayout
log4j.appender.console.layout.ConversionPattern=%d{yy/MM/dd HH:mm:ss} %p %c{2}: %m%n
有的时候我们新建文件的时候选择File->New没有选择文件这个选项,这个时候不用着急,它给隐藏了,找到Window->Perspective->Customize Perspective 勾选上File即可。
更多内容参阅官方API文档。
入门大数据---HDFS-API的更多相关文章
- 入门大数据---HDFS,Zookeeper,ZookeeperFailOverController(简称:ZKFC),JournalNode是什么?
HDFS介绍: 简述: Hadoop Distributed File System(HDFS)是一种分布式文件系统,设计用于在商用硬件上运行.它与现有的分布式文件系统有许多相似之处.但是,与其他分布 ...
- 入门大数据---Spark_Structured API的基本使用
一.创建DataFrame和Dataset 1.1 创建DataFrame Spark 中所有功能的入口点是 SparkSession,可以使用 SparkSession.builder() 创建.创 ...
- 入门大数据---Spark整体复习
一. Spark简介 1.1 前言 Apache Spark是一个基于内存的计算框架,它是Scala语言开发的,而且提供了一站式解决方案,提供了包括内存计算(Spark Core),流式计算(Spar ...
- 入门大数据---Flink学习总括
第一节 初识 Flink 在数据激增的时代,催生出了一批计算框架.最早期比较流行的有MapReduce,然后有Spark,直到现在越来越多的公司采用Flink处理.Flink相对前两个框架真正做到了高 ...
- 入门大数据---SparkSQL外部数据源
一.简介 1.1 多数据源支持 Spark 支持以下六个核心数据源,同时 Spark 社区还提供了多达上百种数据源的读取方式,能够满足绝大部分使用场景. CSV JSON Parquet ORC JD ...
- 入门大数据---Hadoop是什么?
简单概括:Hadoop是由Apache组织使用Java语言开发的一款应对大数据存储和计算的分布式开源框架. Hadoop的起源 2003-2004年,Google公布了部分GFS和MapReduce思 ...
- 入门大数据---Kylin是什么?
一.Kylin是什么? Apache Kylin是一个开源的.分布式的分析型数据仓库,提供Hadoop/Spark 上的SQL查询接口及多维度分析(OLAP)能力以支持超大规模的数据,最初由eBay开 ...
- 大数据-hdfs技术
hadoop 理论基础:GFS----HDFS:MapReduce---MapReduce:BigTable----HBase 项目网址:http://hadoop.apache.org/ 下载路径: ...
- 入门大数据---MapReduce-API操作
一.环境 Hadoop部署环境: Centos3.10.0-327.el7.x86_64 Hadoop2.6.5 Java1.8.0_221 代码运行环境: Windows 10 Hadoop 2.6 ...
- 入门大数据---安装ClouderaManager,CDH和Impala,Hue,oozie等服务
1.要求和支持的版本 (PS:我使用的环境,都用加粗标识了.) 1.1 支持的操作系统版本 操作系统 版本 RHEL/CentOS/OL with RHCK kernel 7.6, 7.5, 7.4, ...
随机推荐
- Alpha冲刺 —— 5.4
这个作业属于哪个课程 软件工程 这个作业要求在哪里 团队作业第五次--Alpha冲刺 这个作业的目标 Alpha冲刺 作业正文 正文 github链接 项目地址 其他参考文献 无 一.会议内容 1.展 ...
- Rocket - tilelink - BankBinder
https://mp.weixin.qq.com/s/oZCYBdy5glxJQmYKVWvpvA 简单介绍BankBinder的实现. 1. 基本介绍 A BankBinder ...
- Chisel3 - Tutorial - FullAdder
https://mp.weixin.qq.com/s/Aye-SrUUuIP6_o67Rlt5OQ 全加器 逻辑图如下: 参考链接: https://github.com/ucb-b ...
- Java实现洛谷 P1007独木桥
题目背景 战争已经进入到紧要时间.你是运输小队长,正在率领运输部队向前线运送物资.运输任务像做题一样的无聊.你希望找些刺激,于是命令你的士兵们到前方的一座独木桥上欣赏风景,而你留在桥下欣赏士兵们.士兵 ...
- java中Timer类的详细介绍(详解)
一.概念 定时计划任务功能在Java中主要使用的就是Timer对象,它在内部使用多线程的方式进行处理,所以它和多线程技术还是有非常大的关联的.在JDK中Timer类主要负责计划任务的功能,也就是在指定 ...
- Java实现LeetCode_0014_LongestCommonPrefix
package javaLeetCode.primary; /** * Write a function to find the longest common prefix string amongs ...
- Java实现LeetCode_0009_PalindromeNumber
package javaLeetCode_primary; import java.util.Scanner; import java.util.Stack; public class Palindr ...
- Java实现行列递增矩阵的查找
1 问题描述 在一个m行n列的二维数组中,每一行都按照从左到右递增的顺序排列,每一列都按照从上到下递增的顺序排列.现在输入这样的一个二维数组和一个整数,请完成一个函数,判断数组中是否含有该整数. 2 ...
- requireJS模块化
1. JavaScript里面js代码的写法:目标是解决冲突和依赖 函数式编程,全局函数和变量--很容易覆盖 对象的写法--也会从外面改变 命名空间:利用名称不同缓冲js代码的冲突---名称太长,不方 ...
- 读取Excel文件,抛出类似Cleaning up unclosed ZipFile for archive D:\project\myTest\autoAppUI\excelMode\用例模板2.xlsx 错误解决
读excel用例的时候总报这个错误,一直不知道什么原因~~~~~~~~~~ 今天突然顿悟了,原来是读excel的时候用到了文件流,我在读文件的方法里加了流关闭的操作,完美解决报错