入门大数据---MapReduce-API操作
一.环境
Hadoop部署环境:
Centos3.10.0-327.el7.x86_64
Hadoop2.6.5
Java1.8.0_221
代码运行环境:
Windows 10
Hadoop 2.6.5
二.安装Hadoop-Eclipse-Plugin
在Eclipse中编译和运行Mapreduce程序,需要安装hadoop-eclipse-plugin,可下载Github上的 hadoop2x-eclipse-plugin 。
下载后将release中的hadoop-eclipse-plugin-2.6.0.jar放在eclipse下面plugins目录下。
三.配置Hadoop-Plugin
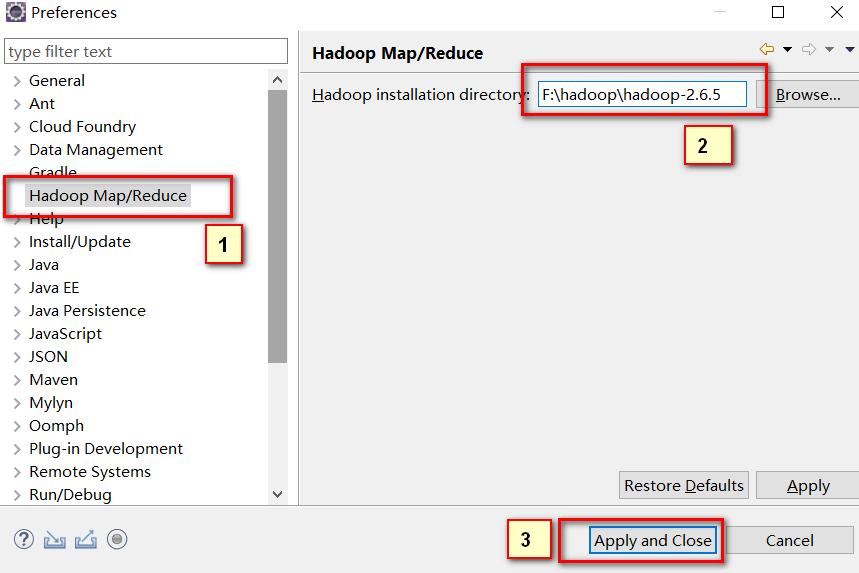
运行eclipse后,点击Window->Preferences在Hadoop Map/Reduce中填上计算机中安装的hadoop目录。
四.在Eclipse中操作HDFS中的文件
我们之前一直使用命令操作Hdfs,接下来再配置几步就可以在Eclipse中可视化操作啦。
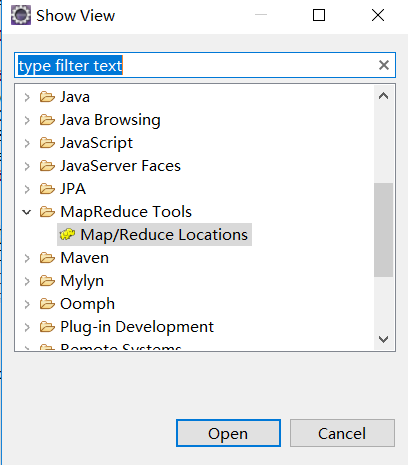
选择Window下面的Show View->Other... ,在弹出的框里面展开MapReduce Tools,选择Map/Reduce Locations点击Open。
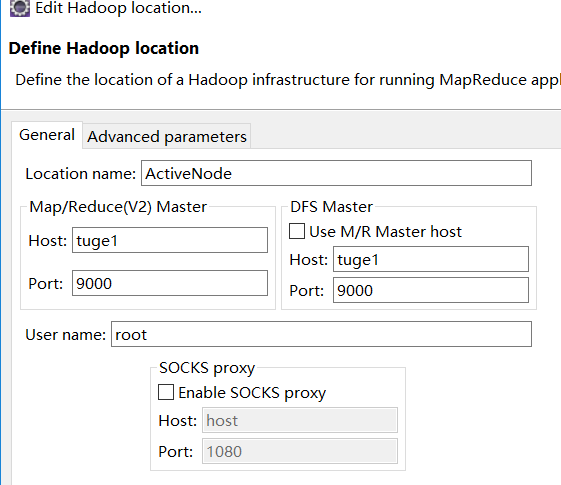
然后在弹出的栏目右键,点击New Hadoop location在弹出框General下面填上活跃的NameNode和端口号信息。

配置好后,可以在左侧刷新即可看到HDFS文件(Tips:对HDFS很多操作后,插件不会自动帮我们刷新内容,需要我们手动刷新)

五.在Eclipse中创建MapReduce项目
选择File->New->Project... 选择Map/Reduce Project ,选择Next,填写项目名称,这里我起名MapReduceFirstDemo。
然后将服务器上的core-site.xml和hdfs-site.xml复制到项目根目录下,并在根目录下创建一个log4j.properties,填上如下内容:
hadoop.root.logger=DEBUG, console
log4j.rootLogger = DEBUG, console
log4j.appender.console=org.apache.log4j.ConsoleAppender
log4j.appender.console.target=System.out
log4j.appender.console.layout=org.apache.log4j.PatternLayout
log4j.appender.console.layout.ConversionPattern=%d{yy/MM/dd HH:mm:ss} %p %c{2}: %m%n
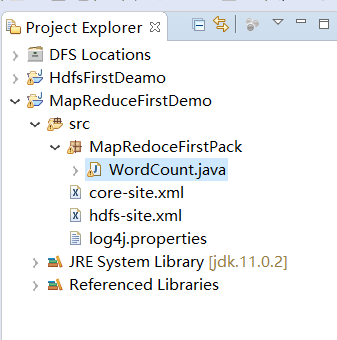
在src中右键创建一个Package,起名MapReduceFirstPack,然后在MapReduceFirstPack下面创建一个WordCount类。大致结构如下图:
将下面的代码复制到WordCount里面
package MapRedoceFirstPack; import java.io.IOException;
import java.util.Iterator;
import java.util.StringTokenizer;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import org.apache.hadoop.util.GenericOptionsParser; public class WordCount { public static void main(String[] args) throws Exception {
// TODO Auto-generated method stub
Configuration conf=new Configuration();
String[] otherArgs=(new GenericOptionsParser(conf, args)).getRemainingArgs();
if(otherArgs.length<) {
System.err.println("Usage:wordcount");
System.exit();
}
Job job=Job.getInstance(conf,"word count");
job.setJarByClass(WordCount.class);
job.setMapperClass(WordCount.TokenizerMapper.class);
job.setCombinerClass(WordCount.IntSumReducer.class);
job.setReducerClass(WordCount.IntSumReducer.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class);
for(int i=;i<otherArgs.length-;++i) {
FileInputFormat.addInputPath(job, new Path(otherArgs[i]));
}
FileOutputFormat.setOutputPath(job, new Path(otherArgs[otherArgs.length-]));
System.exit(job.waitForCompletion(true)?:); } private static class IntSumReducer extends Reducer<Text,IntWritable,Text,IntWritable>{
public IntSumReducer() {} private IntWritable result=new IntWritable();
public void reduce(Text key,Iterable<IntWritable> values,Reducer<Text,IntWritable,Text,IntWritable>.Context context) throws IOException,InterruptedException{
int sum=;
IntWritable val;
for(Iterator i$=values.iterator();i$.hasNext();sum+=val.get()) {
val=(IntWritable)i$.next();
}
this.result.set(sum);
context.write(key, this.result);
}
} public static class TokenizerMapper extends Mapper<Object,Text,Text,IntWritable>{
private static final IntWritable one=new IntWritable();
private Text word=new Text();
public TokenizerMapper() { }
public void map(Object key,Text value,Mapper<Object,Text,Text,IntWritable>.Context context) throws IOException,InterruptedException {
StringTokenizer itr=new StringTokenizer(value.toString());
while(itr.hasMoreTokens()) {
this.word.set(itr.nextToken());
context.write(this.word, one);
} } } }
六.在Eclipse中运行MapReduce项目
在运行上述项目之前,我们需要配置下运行参数。 在项目右键Run As->Run Configuration。 在弹出的框里面选择Java Applicaton下面的WordCount(Tips:如果没有WordCount,则双击Java Application就有了),在Arguments下面添加input output(Tips:代表了输入目录和输出目录,输入目录放要计算的内容,这个需要自己创建,输出目录一定不要创建,它会自动生成,否则会提示已存在此目录的错误),如下图:
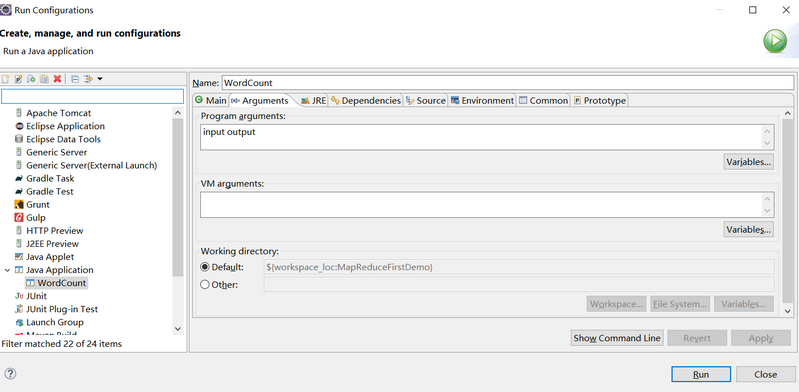
然后点击Run运行。
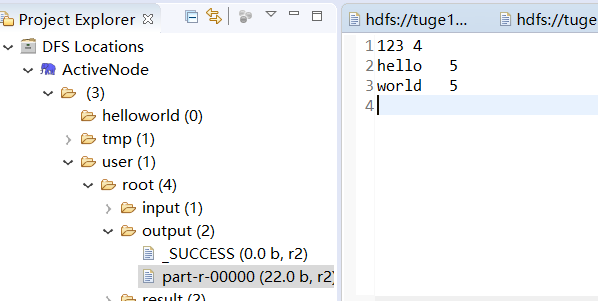
运行完毕后,在左侧刷新,在output目录可以看到两个文件,_SUCCESS是标识文件,代表执行成功的意思。part-r-00000存放的执行结果。
参考资料:
入门大数据---MapReduce-API操作的更多相关文章
- 入门大数据---SparkSQL联结操作
一. 数据准备 本文主要介绍 Spark SQL 的多表连接,需要预先准备测试数据.分别创建员工和部门的 Datafame,并注册为临时视图,代码如下: val spark = SparkSessio ...
- 入门大数据---Spark_Structured API的基本使用
一.创建DataFrame和Dataset 1.1 创建DataFrame Spark 中所有功能的入口点是 SparkSession,可以使用 SparkSession.builder() 创建.创 ...
- 入门大数据---Spark整体复习
一. Spark简介 1.1 前言 Apache Spark是一个基于内存的计算框架,它是Scala语言开发的,而且提供了一站式解决方案,提供了包括内存计算(Spark Core),流式计算(Spar ...
- 入门大数据---Flink学习总括
第一节 初识 Flink 在数据激增的时代,催生出了一批计算框架.最早期比较流行的有MapReduce,然后有Spark,直到现在越来越多的公司采用Flink处理.Flink相对前两个框架真正做到了高 ...
- 入门大数据---Kylin是什么?
一.Kylin是什么? Apache Kylin是一个开源的.分布式的分析型数据仓库,提供Hadoop/Spark 上的SQL查询接口及多维度分析(OLAP)能力以支持超大规模的数据,最初由eBay开 ...
- 大数据 --> MapReduce原理与设计思想
MapReduce原理与设计思想 简单解释 MapReduce 算法 一个有趣的例子:你想数出一摞牌中有多少张黑桃.直观方式是一张一张检查并且数出有多少张是黑桃? MapReduce方法则是: 给在座 ...
- 入门大数据---SparkSQL外部数据源
一.简介 1.1 多数据源支持 Spark 支持以下六个核心数据源,同时 Spark 社区还提供了多达上百种数据源的读取方式,能够满足绝大部分使用场景. CSV JSON Parquet ORC JD ...
- 入门大数据---Hadoop是什么?
简单概括:Hadoop是由Apache组织使用Java语言开发的一款应对大数据存储和计算的分布式开源框架. Hadoop的起源 2003-2004年,Google公布了部分GFS和MapReduce思 ...
- 入门大数据---Hbase_Java_API
一.简述 截至到目前 (2019.04),HBase 有两个主要的版本,分别是 1.x 和 2.x ,两个版本的 Java API 有所不同,1.x 中某些方法在 2.x 中被标识为 @depreca ...
随机推荐
- win10和centos7双系统双磁盘引导的实现
win10和centos7双系统双磁盘引导的实现1.背景:dell5460笔记本电脑M2-120G固态盘无法在bios中引导,新装了M360G固态盘后,考虑把120G固态盘安装centos7.5系统做 ...
- Beta冲刺 —— 5.31
这个作业属于哪个课程 软件工程 这个作业要求在哪里 Beta冲刺 这个作业的目标 Beta冲刺 作业正文 正文 github链接 项目地址 其他参考文献 无 一.会议内容 1.讨论并解决每个人存在的问 ...
- Rocket - tilelink - first
https://mp.weixin.qq.com/s/0nzkV4K1osNEQzrtITYxmw 介绍Edges中first/last/done的实现. 1. firstlastH ...
- Java实现 LeetCode 474 一和零
474. 一和零 在计算机界中,我们总是追求用有限的资源获取最大的收益. 现在,假设你分别支配着 m 个 0 和 n 个 1.另外,还有一个仅包含 0 和 1 字符串的数组. 你的任务是使用给定的 m ...
- Java实现 蓝桥杯VIP 算法训练 大小写判断
问题描述 给定一个英文字母判断这个字母是大写还是小写. 输入格式 输入只包含一个英文字母c. 输出格式 如果c是大写字母,输出"upper",否则输出"lower&quo ...
- Java实现 LeetCode 52 N皇后 II
52. N皇后 II n 皇后问题研究的是如何将 n 个皇后放置在 n×n 的棋盘上,并且使皇后彼此之间不能相互攻击. 上图为 8 皇后问题的一种解法. 给定一个整数 n,返回 n 皇后不同的解决方案 ...
- java实现 蓝桥杯 算法训练 操作格子
问题描述 有n个格子,从左到右放成一排,编号为1-n. 共有m次操作,有3种操作类型: 1.修改一个格子的权值, 2.求连续一段格子权值和, 3.求连续一段格子的最大值. 对于每个2.3操作输出你所求 ...
- Java实现第九届蓝桥杯快速排序
快速排序 以下代码可以从数组a[]中找出第k小的元素. 它使用了类似快速排序中的分治算法,期望时间复杂度是O(N)的. 请仔细阅读分析源码,填写划线部分缺失的内容. package bb; impor ...
- requireJS模块化
1. JavaScript里面js代码的写法:目标是解决冲突和依赖 函数式编程,全局函数和变量--很容易覆盖 对象的写法--也会从外面改变 命名空间:利用名称不同缓冲js代码的冲突---名称太长,不方 ...
- (三)Host头攻击
01 漏洞描述 为了方便获取网站域名,开发人员一般依赖于请求包中的Host首部字段.例如,在php里用_SERVER["HTTP_HOST"].但是这个Host字段值是不可信赖的( ...