sql server 索引阐述系列一索引概述
一. 索引概述
关于介绍索引,有一种“文章太守,挥毫万字,一饮千钟”的豪迈感觉,因为索引需要讲的知识点太多。在每个关系型数据库里都会作为重点介绍,因为索引关系着数据库的整体性能, 它在数据库性能优化里占有重要地位。由于索引关联面广,我想通过一系列来把索引尽量阐述清楚,大概包括索引存储单元、堆介绍、聚集索引与非聚集索引介绍、索引参数(填充因子,包含列,约束等)、索引的使用,索引维护管理,索引统计信息、索引访问方法、索引存储与文件组、索引视图、索引数据修改内部机制、索引的分析调优排查等。尽量争取把索引的知识点讲到讲明白,借鉴一些资料和经验,整理输出理论,实践列出案例。
索引可以提供了对数据的快速访问。就像是一本书的目录,一个好的目录可以极大的减少查询时间,索引使数据以一种特定的方式组织起来,使查询操作具有最佳性能。当表变得越来越大,索引就变得十分明显,可以利用索引快速满足where条件的数据行。某些情况还可以利用索引帮助对数据进行排序,组合,分组,筛选。
在sqlserver里索引类型包括:堆,聚集索引,非聚集索引,列存储索引,特殊索引(如全文索引),其它索引如分区索引,过滤索引等。
1. 堆:堆不是索引,但讲索引时会讲到堆,两者有紧密联系,堆结构在数据插入,没有更改时是有存储顺序的,但一改动如修改删除,结构就会发生变化。没有聚集索引的表称为堆表。
2. 聚集索引:对于聚集索引,数据实际上是按顺序存储的是B-Tree结构,B树是代表平衡的树,在寻找记录时都只需等量的资源,获取速度总是一致的,因为根索引到叶索引都具有相同的深度, 就像一本书把所有目录编排一样,一旦找到所要的数据,就完成了这次搜索,当查询使用到了索引时,sqlserver优化器可以快速定位,最少I/O次数获取所需的数据。
3. 非聚集索引:非聚集索引也是B-Tree结构,在sql server 08可中多达999个。它是完全独立于数据本身结构的,也就是说它存储的是键值,有指针指向数据本身的位置。
4. 列存储索引:它是sql server 2012开始引入的一种索引类型,,主要用于对大数据量的查询操作,与传统的索引行存储不同,通过列存储的压缩方式,在某些场景大大提高索引效率。
二. 索引元数据
元数据是对应每个功能的一些描述与特性,这里的元数据是索引相关描述,后面查询分析还会使用到这些元数据,具体了解使用可以先查看msdn, 索引常用相关元数据如下:
sys.indexes 它提供索引名,索引类型(堆或索引),聚集与非聚集类型,索引填充因子,索引过滤等信息。
sys.index_columns 它提供了索引包含的列信息,可通过与sys.indexes关联获得索引列定义。
SELECT i.name AS index_name
,COL_NAME(ic.object_id,ic.column_id) AS column_name
,ic.index_column_id
,ic.key_ordinal
,ic.is_included_column
FROM sys.indexes AS i
INNER JOIN sys.index_columns AS ic
ON i.object_id = ic.object_id AND i.index_id = ic.index_id
WHERE i.object_id = OBJECT_ID('表名xx');
如下图所示: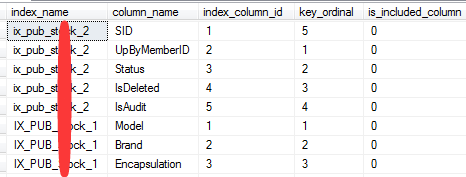
sys.columns_store_dictionaries和sys.columns_store_segments:用于描述列存储信息。
sys.xml_indexes:与sys.indexes类似 主要是用于xml索引。
sys.spatial_indexes:也与sys.indexes类似 主要是用于spatial索引。
sys.dm_db_index_physical_stats:它描述了索引的大小和碎片信息,代替了DBCC SHOWCONTIG。有三种获取统计信息扫描碎片模式:LIMITED,SAMPLED,DETAILED 这三种顺序描述需要的时间是越来越多。
sys.dm_db_index_operational_stats:用来跟踪索引 I/O、 锁定、 闩锁、访问方法。索引访问方式(叶级插入累计数,叶级删除累计数,叶级更新累积数)。 索引或堆上闩锁争用次数时间,lock锁定数量时间,以及索引载入内存 I/O 数。
sys.objects:用户自定义对象(如:表,视图..)的标识号,可以通过索引的objectid找到相关表名或视图名。
sys.PARTITIONS:描述索引在每个分区中各对应一行,表和索引都至少包含一个分区(在表内部结构里,顶层是表,中间层是分区,分区下面再是数据和索引)。
sys.dm_db_index_usage_stats:描述不同类型索引操作的计数(如:全表描述次数、走索引次数,书签查找次数等)以及对应各操作时间。每次查询索引,所进行的每个单独的搜索、扫描、查找或更新都被计为对该索引的一次使用,并使此视图中的相应计数器递增。
sys.dm_db_missing_index_groups:索引组中包含的缺失索引信息。
sys.dm_db_missing_index_details:描述有关缺失索引的详细信息。
sys.dm_db_missing_index_group_stats:描述缺失索引组中包含的缺失索引。
如下图是三个元数据组合,分析出缺失的索引
SELECT DB_NAME(database_id) AS database_name ,
OBJECT_NAME(object_id, database_id) AS table_name ,
mid.equality_columns ,
mid.inequality_columns ,
mid.included_columns ,
( migs.user_seeks + migs.user_scans ) * migs.avg_user_impact AS Impact ,
migs.avg_total_user_cost * ( migs.avg_user_impact / 100.0 )
* ( migs.user_seeks + migs.user_scans ) AS Score ,
migs.user_seeks ,
migs.user_scans
FROM sys.dm_db_missing_index_details mid
INNER JOIN sys.dm_db_missing_index_groups mig ON mid.index_handle = mig.index_handle
INNER JOIN sys.dm_db_missing_index_group_stats migs ON mig.index_group_handle = migs.group_handle
ORDER BY migs.avg_total_user_cost * ( migs.avg_user_impact / 100.0 )
* ( migs.user_seeks + migs.user_scans ) DESC
sys.dm_db_missing_index_columns:缺少索引列的有关的信息。
sql server 索引阐述系列一索引概述的更多相关文章
- sql server 索引阐述系列二 索引存储结构
一.概述. "流光容易把人抛,红了樱桃,绿了芭蕉“ 转眼又年中了,感叹生命的有限,知识的无限.在后续讨论索引之前,先来了解下索引和表数据的内部结构,这一节将介绍页的存储,页分配单元类型,区的 ...
- sql server 索引阐述系列五 索引参数与碎片
-- 创建聚集索引 create table [dbo].[pub_stocktest] add constraint [pk_pub_stocktest] primary key clustered ...
- sql server 索引阐述系列七 索引填充因子与碎片
一.概述 索引填充因子作用:提供填充因子选项是为了优化索引数据存储和性能. 当创建或重新生成索引时,填充因子的值可确定每个叶级页上要填充数据的空间百分比,以便在每一页上保留一些剩余存储空间作为以后扩展 ...
- 【目录】sql server 进阶篇系列
随笔分类 - sql server 进阶篇系列 sql server 下载安装标记 摘要: SQL Server 2017 的各版本和支持的功能 https://docs.microsoft.com/ ...
- SQL Server调优系列基础篇(索引运算总结)
前言 上几篇文章我们介绍了如何查看查询计划.常用运算符的介绍.并行运算的方式,有兴趣的可以点击查看. 本篇将分析在SQL Server中,如何利用先有索引项进行查询性能优化,通过了解这些索引项的应用方 ...
- SQL Server调优系列进阶篇(如何索引调优)
前言 上一篇我们分析了数据库中的统计信息的作用,我们已经了解了数据库如何通过统计信息来掌控数据库中各个表的内容分布.不清楚的童鞋可以点击参考. 作为调优系列的文章,数据库的索引肯定是不能少的了,所以本 ...
- SQL Server调优系列进阶篇(如何维护数据库索引)
前言 上一篇我们研究了如何利用索引在数据库里面调优,简要的介绍了索引的原理,更重要的分析了如何选择索引以及索引的利弊项,有兴趣的可以点击查看. 本篇延续上一篇的内容,继续分析索引这块,侧重索引项的日常 ...
- SQL Server调优系列玩转篇三(利用索引提示(Hint)引导语句最大优化运行)
前言 本篇继续玩转模块的内容,关于索引在SQL Server的位置无须多言,本篇将分析如何利用Hint引导语句充分利用索引进行运行,同样,还是希望扎实掌握前面一系列的内容,才进入本模块的内容分析. 闲 ...
- SQL Server调优系列进阶篇 - 如何索引调优
前言 上一篇我们分析了数据库中的统计信息的作用,我们已经了解了数据库如何通过统计信息来掌控数据库中各个表的内容分布.不清楚的童鞋可以点击参考. 作为调优系列的文章,数据库的索引肯定是不能少的了,所以本 ...
随机推荐
- VB 读取列表文件名
Private Sub Command1_Click()Dim d As String, s As String If Dir(App.Path & "\down", vb ...
- 从零开始学java (五)接口与内部类
接口,是描述类具有什么样的功能,而不是给出每个功能的实现.一个类可以implements多个接口...接口中可以含有 变量和方法.但是要注意, 接口中的变量会被隐式地指定为public static ...
- Jmeter—关联【学习截图】
- 从React组件划分的纠结到总结
在实际开发项目中,我将所有的React组件划分为容器组件和展示组件,展示组件其实就是一个纯函数组件,没有任何副作用,基本都是PureComponent.但是突然,出现了这么一个问题: 我有一个浮层组件 ...
- 02.02.03第3章 餐饮项目案例(Power BI商业智能分析)
02.02.03第3章 餐饮项目案例 02.02.03.01餐饮数据理解与读入 00:06:12 02.02.03.02餐饮数据处理 00:29:57 处理生成的表为: 02.02.03.03餐饮数据 ...
- WPF一组Radio与enum绑定
工作中用到了一组RadioButton对应一组数据的情况,这个时候最好能将一组RadioButton绑定Enum. 步骤 1.MyControl库中Type.cs中定义Enum namespace M ...
- .net HttpListener 很慢
使用 HttpListener 做的webserver ,撒逻辑没有,内网跨机器访问,都要200ms 替换方案 EvHttpSharp.dll 使用了 libevent_core,libevent ...
- VS2017 处理 Rdlc , microsoft report viewer 轻量级报表处理(WPF CS客户端版本)
VS 2017没有安装处理Rdlc的包,需要手动安装: 点击主菜单中Tools 下拉菜单中 扩展和升级: 点选左侧Online ,然后在右侧输入rdlc进行查询,然后 Download 下载安装 M ...
- 长见识-python小知识
操作系统:桌面操作系统,服务器操作系统,嵌入式操作系统,移动设备操作系统. 作用:1直接控制计算机不同的硬件比如cpu,硬盘等进行工作. 2 把操作这些硬件的方法封装成一个又一个的系统调用, 供其他成 ...
- ie页面数据导入共享版
为了解决自动输入号码的正确率,原来的版本一直采用鼠标检测的方法.但是这个方法在其他ie平台的使用不太方便.于是直接检测ie的方法.现在的这个版本完全不需要鼠标的检测.方便而且快速精准可靠. 经过作者的 ...