迁移学习《Pseudo-Label : The Simple and Efficient Semi-Supervised Learning Method for Deep Neural Networks》
论文信息
论文标题:Pseudo-Label : The Simple and Efficient Semi-Supervised Learning Method for Deep Neural Networks
论文作者:Dong-Hyun Lee
论文来源:2013——ICML
论文地址:download
论文代码:download
视屏讲解:click
1 介绍
本文提出了一种简单有效的深度神经网络半监督学习方法。本文所提出的网络是在监督方式下同时使用标记和未标记数据进行训练。对于未标记数据,$\text{Pseudo-Label}$ 是选择具有最大预测概率的类,假设他们形如真实标签。
伪标签等同于熵正则化,它有利于类之间的低密度分离,这是半监督学习通常假设的先验。
2 方法
$\text{Pseudo-Label}$ 模型作为一个简单、有效的半监督学习方法早在 2013年就被提出,其核心思想包括两步:
- 第一步:运用训练好的模型给予无标签数据一个伪标签,可以用概率最高的类别作为无标签数据的伪标签;
- 第二步:运用 $\text{entropy regularization}$ 思想,将无监督数据转为目标函数(Loss)的正则项。实际中,就是将拥有伪标签的无标签数据视为有标签的数据,然后用交叉熵来评估误差大小;
目标函数:
$L=\frac{1}{n} \sum_{m=1}^{n} \sum_{i=1}^{C} L\left(y_{i}^{m}, f_{i}^{m}\right)+\alpha(t) \frac{1}{n^{\prime}} \sum_{m=1}^{n^{\prime}} \sum_{i=1}^{C} L\left(y_{i}^{\prime m}, f_{i}^{\prime m}\right)$
其中,左边第一项为交叉熵,用来评估有标签数据的误差。第二项即为 $\text{entropy regularization}$ 项,用来从无标签的数据中获取训练信号;
为了平衡有标签数据和无标签数据的信号强度,引入时变参数 $\alpha(t)$,随着训练时间的增加,$\alpha(t)$ 将会从零开始线性增长至某个饱和值。背后的核心想法也很直观,早期模型预测效果不佳,因此 $\text{entropy regularization}$ 产生信号的误差也较大,因而 $\alpha(t)$ 应该从零开始,由小逐渐增大;
其中,$\alpha_{f}=3$、$T_{1}=100$、$T_{2}=600$。
3 为什么伪标签有效
低密度分离
聚类假设指出决策边界应位于低密度区域以提高泛化性能。
熵正则化
该方案通过最小化未标记数据的类概率的条件熵来支持类之间的低密度分离,而无需对密度进行任何建模。
$H\left(y \mid x^{\prime}\right)=-\frac{1}{n^{\prime}} \sum_{m=1}^{n^{\prime}} \sum_{i=1}^{C} P\left(y_{i}^{m}=1 \mid x^{\prime m}\right) \log P\left(y_{i}^{m}=1 \mid x^{\prime m}\right)$
熵是类重叠的量度,随着类别重叠的减少,决策边界处的数据点密度会降低。
使用伪标签作为熵正则化进行训练
可视化结果:

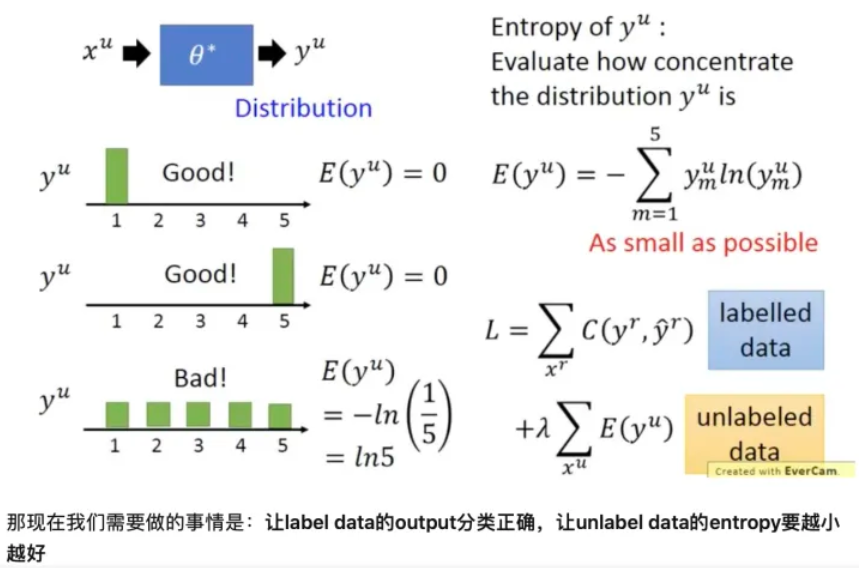
在使用神经网络进行分类时, $y^{u}=f_{\theta^{*}}^{*}\left(x^{u}\right)$ , 其中 $y_{u}$ 是 one-hot 编码。现在我们并不限制其必须是某个类 别, 而是将其看做1个分布, 我们希望这个分布越集中越好("非黑即白"), 因为分布越集中时它的含义就是样本 $x^{u}$ 属于某类别的概率很大属于其它类别的概率很小。
我们可以使用 Entropy 评估分布 $ y^{\mu}$ 的集中程度 $ E\left(y^{\mu}\right)=-\sum_{m=1}^{5} y_{m}^{\mu} \ln \left(y_{m}^{\mu}\right)$ , 假设是5分类, 其值越小则表示分布 $ y^{\mu}$ 越集中。
如下图左侧所示, 上面两个的 $E$为 0 , 所以 $\mathrm{y}$ 的分布很集中; 最后一个 $\mathrm{E}=1 / 5 $, 比上面两个大, 我们 只管也可以看出, 他的分布不那么集中。
参考
迁移学习《Pseudo-Label : The Simple and Efficient Semi-Supervised Learning Method for Deep Neural Networks》的更多相关文章
- 迁移学习(IIMT)——《Improve Unsupervised Domain Adaptation with Mixup Training》
论文信息 论文标题:Improve Unsupervised Domain Adaptation with Mixup Training论文作者:Shen Yan, Huan Song, Nanxia ...
- 迁移学习(JDDA) 《Joint domain alignment and discriminative feature learning for unsupervised deep domain adaptation》
论文信息 论文标题:Joint domain alignment and discriminative feature learning for unsupervised deep domain ad ...
- 论文解读(CDCL)《Cross-domain Contrastive Learning for Unsupervised Domain Adaptation》
论文信息 论文标题:Cross-domain Contrastive Learning for Unsupervised Domain Adaptation论文作者:Rui Wang, Zuxuan ...
- 论文解读(CDTrans)《CDTrans: Cross-domain Transformer for Unsupervised Domain Adaptation》
论文信息 论文标题:CDTrans: Cross-domain Transformer for Unsupervised Domain Adaptation论文作者:Tongkun Xu, Weihu ...
- 虚假新闻检测(CADM)《Unsupervised Domain Adaptation for COVID-19 Information Service with Contrastive Adversarial Domain Mixup》
论文信息 论文标题:Unsupervised Domain Adaptation for COVID-19 Information Service with Contrastive Adversari ...
- 论文解读(CAN)《Contrastive Adaptation Network for Unsupervised Domain Adaptation》
论文信息 论文标题:Contrastive Adaptation Network for Unsupervised Domain Adaptation论文作者:Guoliang Kang, Lu Ji ...
- Unsupervised Domain Adaptation by Backpropagation
目录 概 主要内容 代码 Ganin Y. and Lempitsky V. Unsupervised Domain Adaptation by Backpropagation. ICML 2015. ...
- Deep Transfer Network: Unsupervised Domain Adaptation
转自:http://blog.csdn.net/mao_xiao_feng/article/details/54426101 一.Domain adaptation 在开始介绍之前,首先我们需要知道D ...
- Unsupervised Domain Adaptation Via Domain Adversarial Training For Speaker Recognition
年域适应挑战(DAC)数据集的实验表明,所提出的方法不仅有效解决了数据集不匹配问题,而且还优于上述无监督域自适应方法.
- 论文笔记:Unsupervised Domain Adaptation by Backpropagation
14年9月份挂出来的文章,基本思想就是用对抗训练的方法来学习domain invariant的特征表示.方法也很只管,在网络的某一层特征之后接一个判别网络,负责预测特征所属的domain,而后特征提取 ...
随机推荐
- reactHooks_useEffect
当在直接在组件内使用setState时,会产生"渲染次数过多"的错误 例如: const A = ( ) => { const [num,setNum] = useSta ...
- 链表反转,C++实现
1 // To Compile and Run: g++ invert_list.cc -std=c++11 -Wall -O3 && ./a.out 2 3 4 #include & ...
- STM32任意引脚模拟IIC
关于模拟I2C,任意接口都可模拟(未全部测试,可能存在特殊情况). 关于SDA_IN与SDAOUT:如下定义: 举例:#define MPU_SDA_IN() {GPIOA->CRL&= ...
- Python数据可视化-条形图渐变颜色
import pandas as pd from pyecharts.charts import Bar from pyecharts.commons.utils import JsCode data ...
- python读书笔记-网页制作
socket()函数 Python 中,我们用 socket()函数来创建套接字,语法格式如下: Socket 对象(内建)方法 Python Internet 模块:
- 论C语言数组
一维数组 对于一个一维数组a[10]来说 它对储存空间的申请可以看成是这样的 数组名a就代表着首元素a[0]的地址,也很容易看出a+5是元素a[5]的地址. 二维数组 对于一个二维数组a[3] ...
- 5G如何加速无人快递?5G智能网关新应用
网上购物已经是现代生活的主流消费方式之一,伴随网购的繁荣,物流快递行业也进入到一个最火热的时期.而在这之中,有限的快递配送能力和日益增长的配送需求的矛盾持续凸显,因此无人快递车一类的创新应用也应运而生 ...
- Hive启动留下的RunJar进程不能使用Kill -9 杀不掉怎么办?
1.问题示例 [Hadoop@master Logs]$ jps 3728 ResourceManager 6976 RunJar 7587 Jps 4277 Master 3095 NameNode ...
- 手写 ArrayList 核心源码
手写 ArrayList 核心源码 手写 ArrayList 核心源码 ArrayList 是 Java 中常用的数据结构,不光有 ArrayList,还有 LinkedList,HashMap,Li ...
- 记一个jdbc创建数据库、用户操作时,创建新用户提示CREATE USER权限问题
手写存储表数据库信息,访问链接动态数据源操作: mysql: 1.root登录服务器 进入数据库 mysql -u root -p2.创建数据库 create database shop; shop ...