python爬取猫眼电影Top100榜单的信息
爬取并写入MySQL中
import pymysql
import requests
from bs4 import BeautifulSoup
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) '
'Chrome/80.0.3987.163 Safari/537.36 '
}
connect = pymysql.Connect(
host='localhost',
port=3306,
user='root',
passwd='root',
db='python',
charset='utf8'
)
# 获取游标
cursor = connect.cursor()
def toMySQL(imgBlob, titleSQL, starringSQL, releaseTimeSQL, scoreSQL):
print(requests.get(imgBlob).content)
print(imgBlob)
print(titleSQL)
print(starringSQL[3:])
print(releaseTimeSQL[5:])
print(scoreSQL)
insertSql = """INSERT INTO `python`.`maoyan`(`img`, `title`, `starring`, `release_time`, `score`) VALUES ('{a}','{b}','{c}','{d}','{e}')"""
cursor.execute(
insertSql.format(a=r'' + str(requests.get(imgBlob).content), b=titleSQL, c=starringSQL[3:], d=releaseTimeSQL[5:],
e=scoreSQL))
print("------------------执行了插入")
connect.commit()
def mingzihaonanqi(page):
url = 'https://maoyan.com/board/4?offset=' + str(page)
res = requests.get(url, headers=headers)
# 页面session失效, 需要重新验证, 打印出来方便使用
print(res.url)
# 打印出页面的所有代码
# print(res.text)
soup = BeautifulSoup(res.text, 'html.parser')
ResultSets = soup.find_all('dd')
for resultSet in ResultSets:
tag = resultSet
soupTag = BeautifulSoup(str(tag), 'html.parser')
Title = soupTag.find('a').get('title')
imgSrc = soupTag.find('img', class_='board-img').get('data-src')
starring = soupTag.find('p', class_='star').text.strip()
releaseTime = soupTag.find('p', class_='releasetime').text.strip()
score = soupTag.find('p', class_='score').text.strip()
toMySQL(imgSrc, Title, starring, releaseTime, score)
print(str(page) + "----------")
if __name__ == '__main__':
for i in range(30, 100, 10):
print(i) # 0 10 20 ````
mingzihaonanqi(i)
库表信息

运行结果:
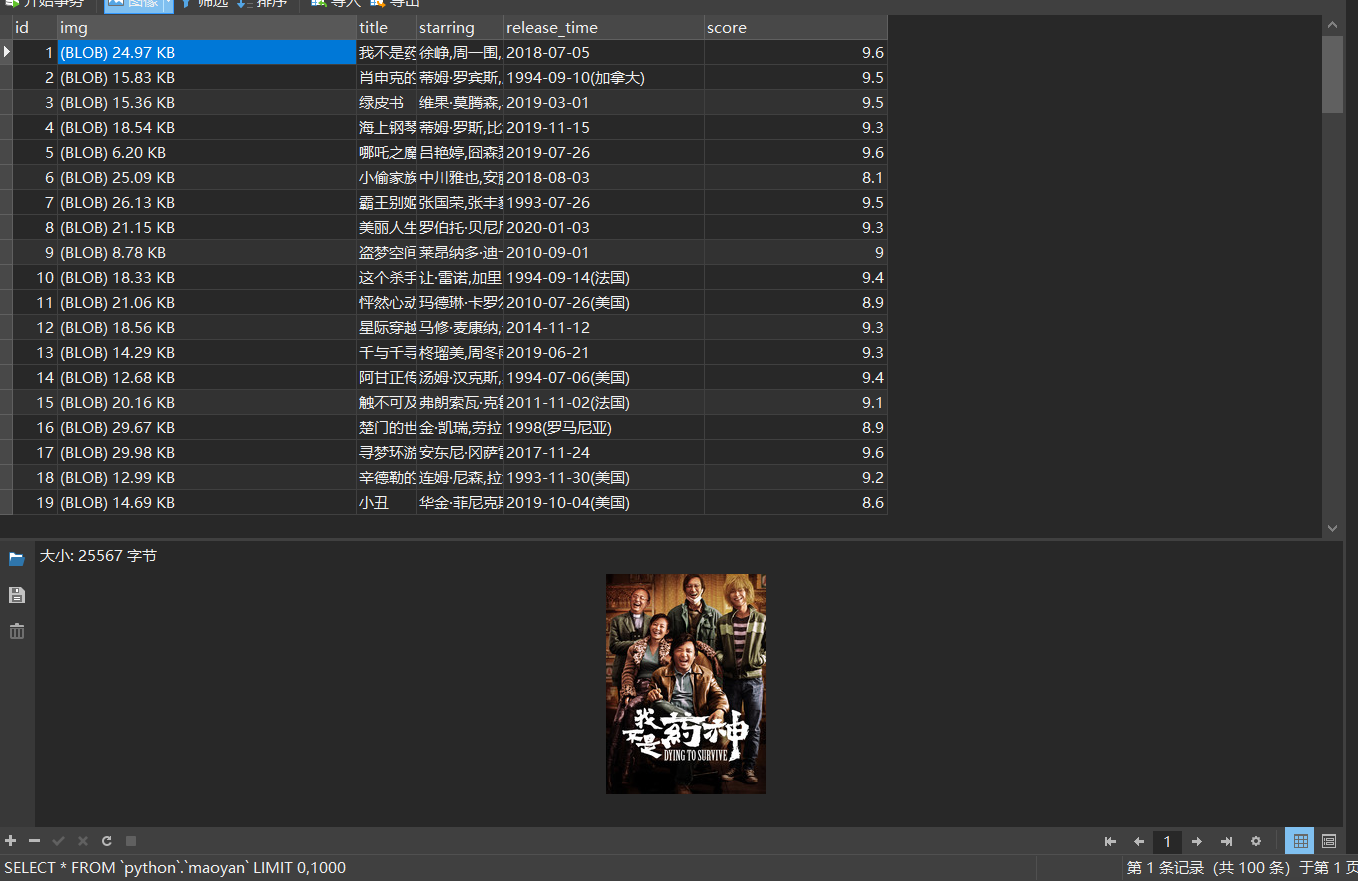
爬取后写入MongoDB
import pymongo
import requests
from bs4 import BeautifulSoup
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) '
'Chrome/80.0.3987.163 Safari/537.36 '
}
def toMongoDB(imgSrc, Title, starring, releaseTime, score):
print(imgSrc)
print(Title)
print(starring[3:])
print(releaseTime[5:])
print(score)
myClient = pymongo.MongoClient("mongodb://localhost:27017/")
myDb = myClient["maoyan"]
myCollection = myDb["maoyanTop100"]
myDictionary = {
"imgSrc": imgSrc,
"Title": Title,
"starring": starring[3:],
"releaseTime": releaseTime[5:],
"score": score
}
result = myCollection.insert_one(myDictionary)
print(result)
pass
def mingzihaonanqi(page):
url = 'https://maoyan.com/board/4?offset=' + str(page)
res = requests.get(url, headers=headers)
# 页面session失效, 需要重新验证, 打印出来方便使用
print(res.url)
# 打印出页面的所有代码
# print(res.text)
soup = BeautifulSoup(res.text, 'html.parser')
ResultSets = soup.find_all('dd')
for resultSet in ResultSets:
tag = resultSet
soupTag = BeautifulSoup(str(tag), 'html.parser')
Title = soupTag.find('a').get('title')
imgSrc = soupTag.find('img', class_='board-img').get('data-src')
starring = soupTag.find('p', class_='star').text.strip()
releaseTime = soupTag.find('p', class_='releasetime').text.strip()
score = soupTag.find('p', class_='score').text.strip()
# 写入MongoDB
toMongoDB(imgSrc, Title, starring, releaseTime, score)
print(str(page) + "----------")
if __name__ == '__main__':
for i in range(0, 100, 10):
print(i) # 0 10 20 ````
mingzihaonanqi(i)
运行结果
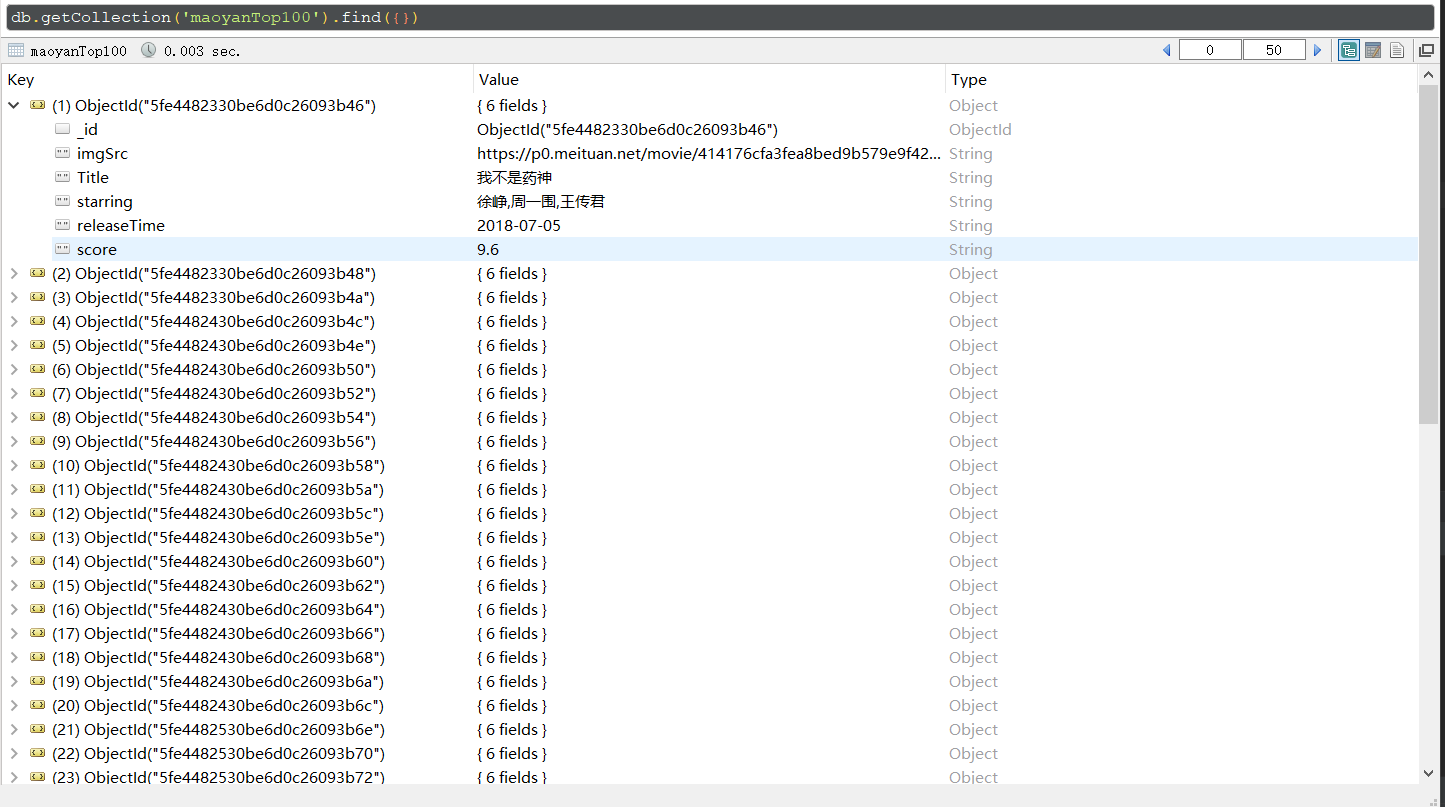
python爬取猫眼电影Top100榜单的信息的更多相关文章
- 爬虫系列(1)-----python爬取猫眼电影top100榜
对于Python初学者来说,爬虫技能是应该是最好入门,也是最能够有让自己有成就感的,今天在整理代码时,整理了一下之前自己学习爬虫的一些代码,今天先上一个简单的例子,手把手教你入门Python爬虫,爬取 ...
- 使用requests爬取猫眼电影TOP100榜单
Requests是一个很方便的python网络编程库,用官方的话是"非转基因,可以安全食用".里面封装了很多的方法,避免了urllib/urllib2的繁琐. 这一节使用reque ...
- python 爬取猫眼电影top100数据
最近有爬虫相关的需求,所以上B站找了个视频(链接在文末)看了一下,做了一个小程序出来,大体上没有修改,只是在最后的存储上,由txt换成了excel. 简要需求:爬虫爬取 猫眼电影TOP100榜单 数据 ...
- 50 行代码教你爬取猫眼电影 TOP100 榜所有信息
对于Python初学者来说,爬虫技能是应该是最好入门,也是最能够有让自己有成就感的,今天,恋习Python的手把手系列,手把手教你入门Python爬虫,爬取猫眼电影TOP100榜信息,将涉及到基础爬虫 ...
- 40行代码爬取猫眼电影TOP100榜所有信息
主要内容: 一.基础爬虫框架的三大模块 二.完整代码解析及效果展示 1️⃣ 基础爬虫框架的三大模块 1.HTML下载器:利用requests模块下载HTML网页. 2.HTML解析器:利用re正则表 ...
- Python爬虫项目--爬取猫眼电影Top100榜
本次抓取猫眼电影Top100榜所用到的知识点: 1. python requests库 2. 正则表达式 3. csv模块 4. 多进程 正文 目标站点分析 通过对目标站点的分析, 来确定网页结构, ...
- Requests+正则表达式爬取猫眼电影(TOP100榜)
猫眼电影网址:www.maoyan.com 前言:网上一些大神已经对猫眼电影进行过爬取,所用的方法也是各有其优,最终目的是把影片排名.图片.名称.主要演员.上映时间与评分提取出来并保存到文件或者数据库 ...
- Python爬取猫眼电影100榜并保存到excel表格
首先我们前期要导入的第三方类库有; 通过猫眼电影100榜的源码可以看到很有规律 如: 亦或者是: 根据规律我们可以得到非贪婪的正则表达式 """<div class ...
- python爬取猫眼电影top100
最近想研究下python爬虫,于是就找了些练习项目试试手,熟悉一下,猫眼电影可能就是那种最简单的了. 1 看下猫眼电影的top100页面 分了10页,url为:https://maoyan.com/b ...
- python 爬取猫眼下的榜单(一)--单个页面
#!/usr/bin/env python # -*- coding: utf- -*- # @Author: Dang Kai # @Date: -- :: # @Last Modified tim ...
随机推荐
- backward函数中gradient参数的一些理解
当标量对向量求导时不需要该参数,但当向量对向量求导时,若不加上该参数则会报错,显示"grad can be implicitly created only for scalar output ...
- win10 + ubuntu 下右键新建md文件(转载)
win10系统 由于前人的总结很不错,所以,在这里附上链接 原文链接 ubuntu系统(linux) 对于ubuntu系统下,这个操作更方便了. 原文链接 不仅是markdown文档,还有.doc.e ...
- oracle 存过调试 stepinto stepover stepout
step into:单步执行,遇到子函数就进入并且继续单步执行(简而言之,进入子函数): step over:在单步执行时,在函数内遇到子函数时不会进入子函数内单步执行,而是将子函数整个执行完再停止, ...
- #Python #字符画 #灰度图 使用Python绘制字符画及其原理
由于最近身体状况不太好所以更新会有点慢,请大家多多包涵.同时也提醒大家注意保重身体! 前提:默认大家已经正确安装了 Python,且正确将Python配置到了系统Path . 目录 1.字符画的概况 ...
- 中国台湾BSMI认证变动
China Taiwan 中国台湾 2022 年 11 月 1 日,BSMI和经济部发布了针对 18 种音像产品的修订法定检验要求. 自发布之日起,CNS 15598-1:2020 Audio/vid ...
- Charles 抓取 HTTPS 协议内容,需要做什么操作?
抓取 HTTPS 需要安装证书,Charles 端需要安装 Android.iOS手机端也需要安装 电脑的 Charles 操作:1.proxy - proxy setting - http prox ...
- SQL Server 错误:特殊符号“•”导致的sql查询问题
问题描述: 对于一些标题或字符串,例如: 如果导入数据库,就会发现会自动变成?号了: 在进行SQL查询的时候,会出现一个同一条sql语句在mysql直接执行sql可以查询到,但是mssql进行查询的时 ...
- Redis集群模式及工作原理
Redis有三种集群模式:主从模式.哨兵模式和集群模式. 1. 主从模式 所有的写请求都被发送到主数据库上,再由主数据库将数据同步到从数据库上.主数据库主要用于执行写操作和数据同步,从数据库主要用于执 ...
- 微信小程序 css overflow :hidden 子元素不生效
原css .item .right { width: 70%; } .item .right .name { font-size: 32rpx; font-family ...
- LeetCode 之 559. N叉树的最大深度
原题链接 思路: 递归计算每个子树的深度,返回最大深度即可 python/python3: class Solution(object): def maxDepth(self, root): &quo ...