python爬取猫眼电影Top100榜单的信息
爬取并写入MySQL中
import pymysql
import requests
from bs4 import BeautifulSoup
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) '
'Chrome/80.0.3987.163 Safari/537.36 '
}
connect = pymysql.Connect(
host='localhost',
port=3306,
user='root',
passwd='root',
db='python',
charset='utf8'
)
# 获取游标
cursor = connect.cursor()
def toMySQL(imgBlob, titleSQL, starringSQL, releaseTimeSQL, scoreSQL):
print(requests.get(imgBlob).content)
print(imgBlob)
print(titleSQL)
print(starringSQL[3:])
print(releaseTimeSQL[5:])
print(scoreSQL)
insertSql = """INSERT INTO `python`.`maoyan`(`img`, `title`, `starring`, `release_time`, `score`) VALUES ('{a}','{b}','{c}','{d}','{e}')"""
cursor.execute(
insertSql.format(a=r'' + str(requests.get(imgBlob).content), b=titleSQL, c=starringSQL[3:], d=releaseTimeSQL[5:],
e=scoreSQL))
print("------------------执行了插入")
connect.commit()
def mingzihaonanqi(page):
url = 'https://maoyan.com/board/4?offset=' + str(page)
res = requests.get(url, headers=headers)
# 页面session失效, 需要重新验证, 打印出来方便使用
print(res.url)
# 打印出页面的所有代码
# print(res.text)
soup = BeautifulSoup(res.text, 'html.parser')
ResultSets = soup.find_all('dd')
for resultSet in ResultSets:
tag = resultSet
soupTag = BeautifulSoup(str(tag), 'html.parser')
Title = soupTag.find('a').get('title')
imgSrc = soupTag.find('img', class_='board-img').get('data-src')
starring = soupTag.find('p', class_='star').text.strip()
releaseTime = soupTag.find('p', class_='releasetime').text.strip()
score = soupTag.find('p', class_='score').text.strip()
toMySQL(imgSrc, Title, starring, releaseTime, score)
print(str(page) + "----------")
if __name__ == '__main__':
for i in range(30, 100, 10):
print(i) # 0 10 20 ````
mingzihaonanqi(i)
库表信息

运行结果:
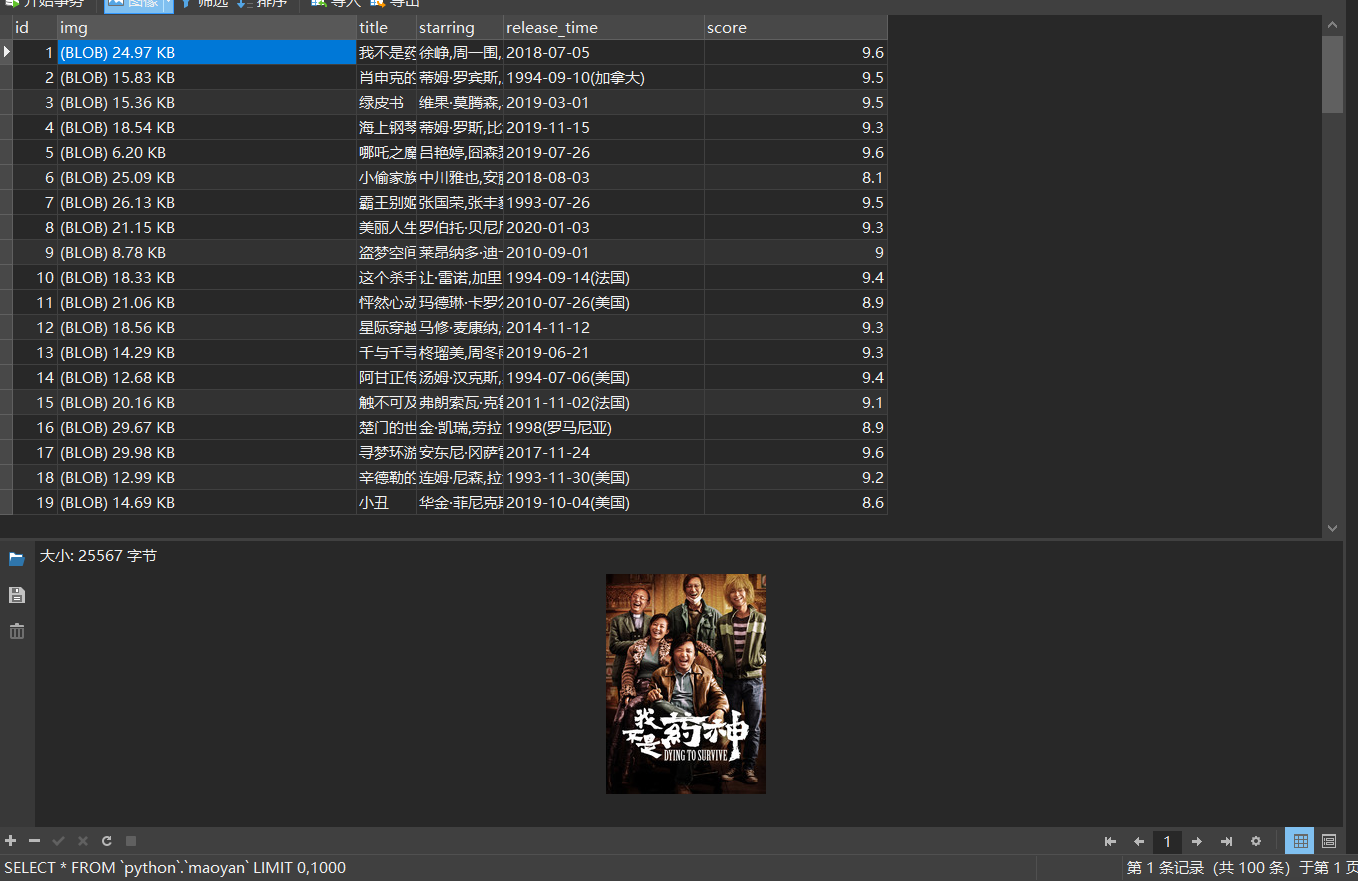
爬取后写入MongoDB
import pymongo
import requests
from bs4 import BeautifulSoup
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) '
'Chrome/80.0.3987.163 Safari/537.36 '
}
def toMongoDB(imgSrc, Title, starring, releaseTime, score):
print(imgSrc)
print(Title)
print(starring[3:])
print(releaseTime[5:])
print(score)
myClient = pymongo.MongoClient("mongodb://localhost:27017/")
myDb = myClient["maoyan"]
myCollection = myDb["maoyanTop100"]
myDictionary = {
"imgSrc": imgSrc,
"Title": Title,
"starring": starring[3:],
"releaseTime": releaseTime[5:],
"score": score
}
result = myCollection.insert_one(myDictionary)
print(result)
pass
def mingzihaonanqi(page):
url = 'https://maoyan.com/board/4?offset=' + str(page)
res = requests.get(url, headers=headers)
# 页面session失效, 需要重新验证, 打印出来方便使用
print(res.url)
# 打印出页面的所有代码
# print(res.text)
soup = BeautifulSoup(res.text, 'html.parser')
ResultSets = soup.find_all('dd')
for resultSet in ResultSets:
tag = resultSet
soupTag = BeautifulSoup(str(tag), 'html.parser')
Title = soupTag.find('a').get('title')
imgSrc = soupTag.find('img', class_='board-img').get('data-src')
starring = soupTag.find('p', class_='star').text.strip()
releaseTime = soupTag.find('p', class_='releasetime').text.strip()
score = soupTag.find('p', class_='score').text.strip()
# 写入MongoDB
toMongoDB(imgSrc, Title, starring, releaseTime, score)
print(str(page) + "----------")
if __name__ == '__main__':
for i in range(0, 100, 10):
print(i) # 0 10 20 ````
mingzihaonanqi(i)
运行结果
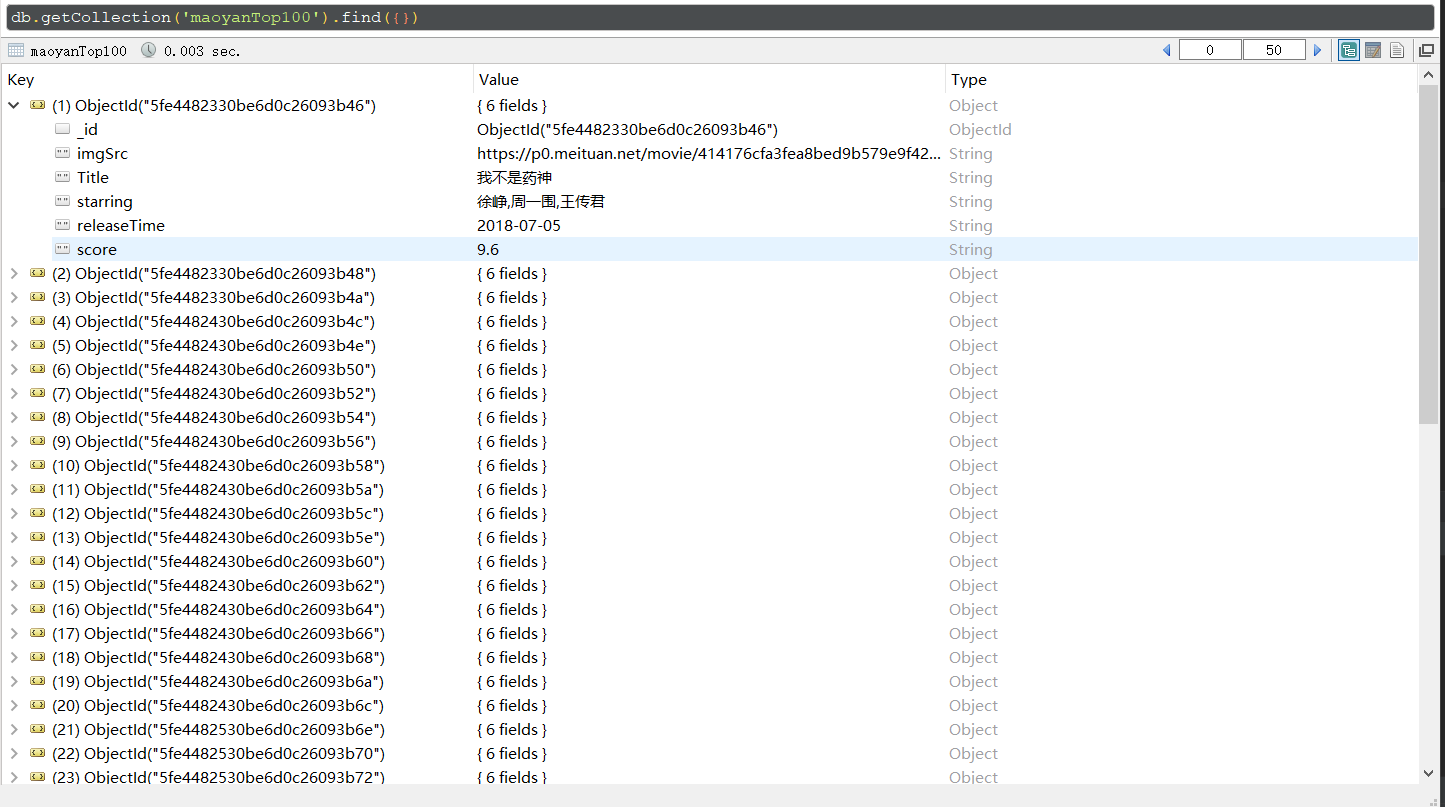
python爬取猫眼电影Top100榜单的信息的更多相关文章
- 爬虫系列(1)-----python爬取猫眼电影top100榜
对于Python初学者来说,爬虫技能是应该是最好入门,也是最能够有让自己有成就感的,今天在整理代码时,整理了一下之前自己学习爬虫的一些代码,今天先上一个简单的例子,手把手教你入门Python爬虫,爬取 ...
- 使用requests爬取猫眼电影TOP100榜单
Requests是一个很方便的python网络编程库,用官方的话是"非转基因,可以安全食用".里面封装了很多的方法,避免了urllib/urllib2的繁琐. 这一节使用reque ...
- python 爬取猫眼电影top100数据
最近有爬虫相关的需求,所以上B站找了个视频(链接在文末)看了一下,做了一个小程序出来,大体上没有修改,只是在最后的存储上,由txt换成了excel. 简要需求:爬虫爬取 猫眼电影TOP100榜单 数据 ...
- 50 行代码教你爬取猫眼电影 TOP100 榜所有信息
对于Python初学者来说,爬虫技能是应该是最好入门,也是最能够有让自己有成就感的,今天,恋习Python的手把手系列,手把手教你入门Python爬虫,爬取猫眼电影TOP100榜信息,将涉及到基础爬虫 ...
- 40行代码爬取猫眼电影TOP100榜所有信息
主要内容: 一.基础爬虫框架的三大模块 二.完整代码解析及效果展示 1️⃣ 基础爬虫框架的三大模块 1.HTML下载器:利用requests模块下载HTML网页. 2.HTML解析器:利用re正则表 ...
- Python爬虫项目--爬取猫眼电影Top100榜
本次抓取猫眼电影Top100榜所用到的知识点: 1. python requests库 2. 正则表达式 3. csv模块 4. 多进程 正文 目标站点分析 通过对目标站点的分析, 来确定网页结构, ...
- Requests+正则表达式爬取猫眼电影(TOP100榜)
猫眼电影网址:www.maoyan.com 前言:网上一些大神已经对猫眼电影进行过爬取,所用的方法也是各有其优,最终目的是把影片排名.图片.名称.主要演员.上映时间与评分提取出来并保存到文件或者数据库 ...
- Python爬取猫眼电影100榜并保存到excel表格
首先我们前期要导入的第三方类库有; 通过猫眼电影100榜的源码可以看到很有规律 如: 亦或者是: 根据规律我们可以得到非贪婪的正则表达式 """<div class ...
- python爬取猫眼电影top100
最近想研究下python爬虫,于是就找了些练习项目试试手,熟悉一下,猫眼电影可能就是那种最简单的了. 1 看下猫眼电影的top100页面 分了10页,url为:https://maoyan.com/b ...
- python 爬取猫眼下的榜单(一)--单个页面
#!/usr/bin/env python # -*- coding: utf- -*- # @Author: Dang Kai # @Date: -- :: # @Last Modified tim ...
随机推荐
- Vue.js + TypeScript 项目构建 (图形界面构建)
一,打开图形界面 vue ui 二,创建文件 三,创建成功
- 进入容器后不显示id
https://www.656463.com/wenda/dockerexejrrqbxsrqID_493 net=host的原因
- 创建一个HashMap实例,该实例具有足够高的“初始容量”
创建一个HashMap实例,该实例具有足够高的"初始容量" /** * 创建一个{@link HashMap}实例,该实例具有足够高的"初始容量" * * @p ...
- JavaScript数据类型以及转换
一.数据类型 分类 基本(值)类型: String Number Boolean undefined unll 对象(引用)类型: Object:任意对象 Array:一种特别的对象 Function ...
- Treewidget节点的增加
父节点的创建 // 隐藏QTreewidget标题头 ui->treeWidget->header()->hide(); // 实现Treewidget父节点的挂载 // 创建存放Q ...
- ubuntu | virtualbox报错:不能为虚拟电脑打开一个新任务
百度了几个办法 都不行. 还得是gxd,说在vmware虚拟机设置勾上这个就行了
- C# 获取当前路径7种方法及输出
//获取模块的完整路径.string path1 = System.Diagnostics.Process.GetCurrentProcess().MainModule.FileName;D:\wor ...
- .NET 6 的 docker 镜像可以有多小
https://blog.csdn.net/sD7O95O/article/details/120135032 Docker Image Size - How to Keep It Small? ht ...
- java 在 map put方法是报 java.lang.NullPointerException的异常 处理办法
当在定义map变量时,如果没有初始化对象,那么默认map值为空的,此时对map进行操作,会报空指针异常,解决办法就是初始化map变量 或者,直接初始化变量,不用在代码块里面设置 Map<Stri ...
- 【组会】2023_1_27 google soli
Soli: Ubiquitous Gesture Sensing with Millimeter Wave Radar (59) soli是一项运用微型雷达监测空中手势动作的传感技术,这种特殊设计的雷 ...