[数据结构]广度优先搜索算法(Breadth-First-Search,BFS)
广度优先搜索的概念
广度优先搜索(BFS)类似于二叉树的层序遍历算法,它的基本思想是:首先访问起始顶点v,然后由v出发,依次访问v的各个未被访问过的邻接顶点w1,w2,w3….wn,然后再依次访问w1,w2,…,wi的所有未被访问过的邻接顶点,再从这些访问过的顶点出发,再访问它们所有未被访问过的邻接顶点….以此类推,直到途中所有的顶点都被访问过为止。类似的想法还将应用与Dijkstra单源最短路径算法和Prim最小生成树算法。(这个过程我觉得可以举个这样的例子来理解:比如要从你开始介绍你的家人,可以先从你开始,然后一个一个介绍和你有直接血缘关系的这一层亲属(爸爸妈妈儿子女儿),当把你所有的这些第一层亲属全都遍历完之后再从你的妈妈开始遍历(也可以从爸爸或儿子),把你妈妈的有直接血缘关系的亲戚先遍历一遍,然后再从爸爸开始,以此类推,直到全部都遍历完成)。
广度优先搜索是一种分层的查找过程,每向前走一步可能访问一批顶点,不像深度优先搜索那样有回退的情况(另一篇博客会介绍),因此它不是一个递归的算法,为了实现逐层的访问,算法必须借助一个辅助队列并且以非递归的形式来实现。
算法伪代码
其伪代码如下:
bool visited[MAX_VERTEX_NUM];//访问数组,也就是顶点个数
void BFSTraverse(Graph G)
//外层的函数,为准备实现遍历做一些准备工作。
{
for(int i=0;i<G.vexnum;++i)
visited[i]=false;//先将所有的顶点都设置为没有被访问过
InitQueue(Q);//初始化辅助队列方便遍历顶点
for(int i=0;i<G.vexnum;++i)
if(!visited[i])
BFS(G,i);
//外层循环使用if语句来调用BFS的原因是为了防止有的顶点它不能从初始顶点出发而遍历到,所以这里需要一个完全的循环来避免这种极端情况。
}
void BFS(Graph G,int v)
//从顶点v出发,广度优先遍历图G,算法借助了一个辅助队列Q
visit(v);//visit函数访问这个顶点的信息
visited[v]=true;//访问过了这个顶点之后就将这个顶点设置为已访问,即true
Enqueue(Q,v);//将顶点v入队列,这样就可以从队列中出队并访问它的相邻顶点
while(!isEmpty(Q)){
DeQueue(Q,v);//将队头的元素出队列存储在v
for(w=FirstNeighbor(G,v);w>=0;w=NextNeighbor(G,v,w))//这一步是检查v的所有邻接顶点
if(!visited[w]){
visit(w);
visited[w]=true;
EnQueue(Q,w);
//如果w没有被访问过,那么访问这个顶点,并把它入队
}
}实例以及解析
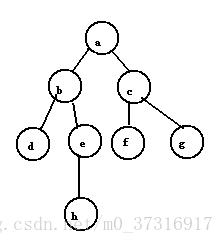
假设从a顶点开始访问,a先入队。此时队列非空,取出队头元素a,由于b,c和a直接相邻且未被访问过,于是依次访问b,c,并且b,c依次入队。队列非空,取出队头元素b,依次访问与b相邻且未被访问的顶点d,e,并且将d,e入队(注意:a与b也邻接,但是a已经访问过,就不会再访问了)。此时队列非空,取出队头元素c,访问与c邻接且未被访问过的顶点f,g,并且将f,g入队。此时,取出队头元素d,但与d邻接且为被访问的顶点为空,故不再进行任何操作,继续取出对头元素e,将h入队….当最后取出队头元素h后,队列为空,从而循环自动跳出,遍历的结果为abcdefgh。
BFS算法性能分析
无论是邻接表还是邻接矩阵的存储访问,BFS算法都需要借助一个辅助队列Q,n个顶点都需要入队依次,在最坏的情况下,空间复杂度为O(|V|)。
当采用邻接表存储方式时,每个顶点均需要搜索依次(或入队依次),故时间复杂度为O(|V|),再搜索任一顶点时,每条边至少访问依次,故时间复杂度为O(|E|),算法的总时间复杂度为O(|V|+|E|);当采用邻接矩阵存储方式的时候,查找每个顶点的邻接点所需时间为O(|V|),故算法总的时间复杂度为O(|V|²)。
BFS算法求单源最短路径问题
如果图G=(V,E)为非带权图。定义从顶点u到顶点v的最短路径d(u,v)为从u到v的任何路径中最少的边数;如果从u到v没有通路,则d(u,v)=∞。
使用BFS,我们可以求解一个满足上述定义的非带权图的单源最短路径问题,这是由广度优先搜索总是按照距离由近到远来遍历图中每个顶点的性质决定的(这让我想到:在2d游戏中计算两个位置的最短路径是否可以采用BFS算法来求出呢?)
BFS算法求解单源最短路径问题的算法如下:
void BFS_MIN_Distance(Graph G,int u){
//d[i]表示从u到i结点的最短路径
for(i=0;i<G.vexnum;++i)
d[i]=∞; //初始化路径长度
visited[u]=true;
d[u]=0;
while(!isEmpty(Q)){
DeQueue(Q,u);
for(w=FirstNeighbor(G,u);w>=0;w=NextNeighbor(G,u,w))
if(!visited[w]){//w为u未曾访问的邻接顶点
visited[w]=true;//设为已经访问
d[w]=d[u]+1;//路径长度+1
EnQueque(Q,w);//w顶点入队
}
}
}[数据结构]广度优先搜索算法(Breadth-First-Search,BFS)的更多相关文章
- 广度优先搜索(Breadth First Search, BFS)
广度优先搜索(Breadth First Search, BFS) BFS算法实现的一般思路为: // BFS void BFS(int s){ queue<int> q; // 定义一个 ...
- 【2018.07.30】(广度优先搜索算法/队列)学习BFS算法小记
一些BFS参考的博客: https://blog.csdn.net/ldx19980108/article/details/78641127 https://blog.csdn.net/u011437 ...
- ZH奶酪:【数据结构与算法】搜索之BFS
1.目标 通过本文,希望可以达到以下目标,当遇到任意问题时,可以: 1.很快建立状态空间: 2.提出一个合理算法: 3.简单估计时空性能: 2.搜索分类 2.1.盲目搜索 按照预定的控制策略进行搜索, ...
- python 递归深度优先搜索与广度优先搜索算法模拟实现
一.递归原理小案例分析 (1)# 概述 递归:即一个函数调用了自身,即实现了递归 凡是循环能做到的事,递归一般都能做到! (2)# 写递归的过程 1.写出临界条件2.找出这一次和上一次关系3.假设当前 ...
- python 递归,深度优先搜索与广度优先搜索算法模拟实现
一.递归原理小案例分析 (1)# 概述 递归:即一个函数调用了自身,即实现了递归 凡是循环能做到的事,递归一般都能做到! (2)# 写递归的过程 1.写出临界条件 2.找出这一次和上一次关系 3.假设 ...
- AI广度优先搜索算法,项目实战北京地图/贪心学院
广度优先搜索算法详解地铁路线 北京很大,附上地铁图,不要迷路!!! 作为一个程序员,在北京,你很有可能住在回龙观地区,经常从龙泽上地铁,然后畅游北京. 当有一天,你老家的朋友来北京了,希望你能够带她去 ...
- [数据结构]深度优先搜索算法(Depth-First-Search,DFS)
深度优先搜索算法的概念 与广度优先搜索算法不同,深度优先搜索算法类似与树的先序遍历.这种搜索算法所遵循的搜索策略是尽可能"深"地搜索一个图.它的基本思想如下:首先访问图中某一个起始 ...
- javascript实现的图数据结构的广度优先 搜索(Breadth-First Search,BFS)和深度优先搜索(Depth-First Search,DFS)
最后一例,搞得快.三天之内走了一次.. 下一步,面象对像的javascript编程. function Dictionary(){ var items = {}; this.has = functio ...
- 数据结构之 图论---基于邻接矩阵的广度优先搜索遍历(输出bfs遍历序列)
数据结构实验图论一:基于邻接矩阵的广度优先搜索遍历 Time Limit: 1000MS Memory limit: 65536K 题目描述 给定一个无向连通图,顶点编号从0到n-1,用广度优先搜索( ...
随机推荐
- 简单将Springboot项目部署到linux服务器上
1.使用springboot的jar包方式 直接使用maven工具按照步骤点击就可以直接打包 2.到target目录下找到 jar包 3.将jar包放到linux的任意文件夹下(此项目是之前的kafk ...
- springboot+redis+虚拟机 springboot连接linux虚拟机中的redis服务
文章目录 1.前提条件:确保虚拟机开启.并且连接到redis 2.新建立一个springboot项目,创建项目时勾选web选项 3.在pom中引入redis依赖 4.在application.prop ...
- 创建Vue工程常用的命令
创建一个vue项目的步骤 1.创建一个名称为myapp的工程 vue init webpack myapp 2.进入工程目录 cd myapp 3.安装 vue-router npm install ...
- 齐博x1工单碎片模板制作教程
可以把工单插入到任何频道的内容里边,如下图所示 碎片模板制作标准如下 <form action="{:urls('order/add')}" class="wn_f ...
- 盘它!基于CANN的辅助驾驶AI实战案例,轻松搞定车辆检测和车距计算!
摘要:基于昇腾AI异构计算架构CANN(Compute Architecture for Neural Networks)的简易版辅助驾驶AI应用,具备车辆检测.车距计算等基本功能,作为辅助驾驶入门级 ...
- 成熟企业级开源监控解决方案Zabbix6.2关键功能实战-下
@ 目录 实战 Zabbix server源码安装使用示例 部署 配置 Zabbix agent2使用示例 部署 配置 Zabbix proxy使用示例 部署 配置 自定义监控使用示例 触发器使用示例 ...
- Ant Design Pro:Layout 组件——嵌套布局
在 BasicLayout.jsx 文件中修改 <ProLayout layout="topmenu" className="chenshuai2144&q ...
- zabbix-钉钉报警部署
zabbix-钉钉报警部署 1. 流程说明 申请钉钉机器人 获取Webhook配置安全设置 获取钉钉号 使用脚本(shell/python)调用钉钉接口: python 输入收件人 信息 配置发件人 ...
- solidedge型材库/.sldlfp格式转.par
一.打开solidworks型材库:D:\Program Files\SOLIDWORKS Corp\SOLIDWORKS\lang\chinese-simplified\weldment profi ...
- linux 挂载 vdi 文件(virtual box虚拟机镜像文件)
1. 下载 vdfuse 下载地址 2.解压deb文件 解压deb安装包文件,这里不使用安装命令是因为你的virtualbox 可能和vdfuse的版本不一致,导致安装失败,而我们只需要用到 vdfu ...