NCDC 天气数据的预处理
“Hadoop: The Definitive Guild” 这本书的例子都是使用NCDC 天气数据的,但由于书的出版和现在已经有一段时间了,NCDC现在提供的原始数据结构已经有了一些变化,本文主要描述书中附表C中的GSOD数据的预处理过程。
GSOD的数据可以在NCDC官网找到:
其实就是如下FTP信息:
ftp://ftp.ncdc.noaa.gov/pub/data/gsod
路径:/pub/data/gsod
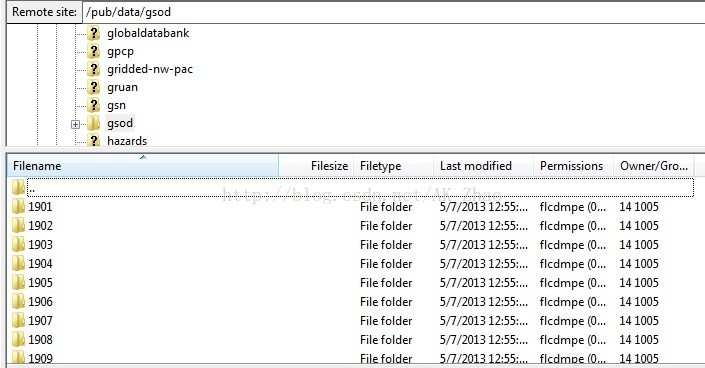
进入FTP你会发现所有天气信息按年保存文件夹里面,当前有115个文件夹(1901至2015年):
以2012年的数据为例,里面含有12409个文件:这表示里面含有全球12408个观测站点提供的数据,分别各占一个gz包,每一年的数据最终被打包在gsod_2012.tar的文件里面:
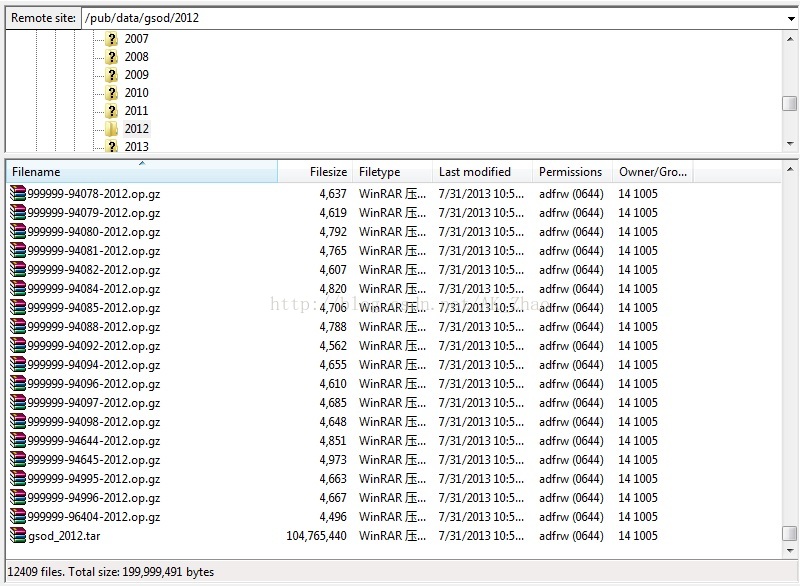
如果这时候你打算下载所有包,那你需要下载约40万个,所以我们filter掉gz包,只需要下载115个tar包就含有所有数据。
在FileZila中新建一个filter:

在远程文件中应用该设置:

此时FTP上只显示tar文件:

然后下载整个gsod文件夹到本地,最终是3.43GB的数据.
每个tar文件是如下文件结构:

由于每个tar文件都含有数千上万的小文件,在Hadoop在数量小且单个文件大的场景下表现得最好,所以Hadoop: The Definitive Guild建议大家讲将每一年所有站点的数据合并问一个大文件,这也就是最后一本书讲的内容。
首先介绍下我的环境:
Hadoop 2.6.0 一个主节点 三个从节点:
Ubuntu 14.04.01
192.168.137.10 namenode
192.168.137.11 datanode1
192.168.137.12 datanode2
192.168.137.13 datanode3
首先将Windows本地的gsod文件夹上传到namenode:

在HDFS上新建GSOD文件夹保存所有tar文件,新建GSOD_ALL文件夹来保存打包后的文件:
hdfs dfs -mkdir /GSOD /GSOD_ALL查看文件夹是否建立:
hdfs dfs -ls /输出如下:

将本地的namenode上的gsod文件夹里的文件上传到HDFS上:
hdfs dfs -put gsod/* /GSOD/
本例中我只上传了10个文件到HDFS:
hadoopid@namenode:~$ hdfs dfs -ls /GSOD
Found 10 items
drwxr-xr-x - hadoopid supergroup 0 2015-01-26 11:06 /GSOD/2000
drwxr-xr-x - hadoopid supergroup 0 2015-01-26 11:06 /GSOD/2001
drwxr-xr-x - hadoopid supergroup 0 2015-01-26 11:06 /GSOD/2002
drwxr-xr-x - hadoopid supergroup 0 2015-01-26 11:06 /GSOD/2003
drwxr-xr-x - hadoopid supergroup 0 2015-01-26 11:06 /GSOD/2004
drwxr-xr-x - hadoopid supergroup 0 2015-01-26 11:06 /GSOD/2005
drwxr-xr-x - hadoopid supergroup 0 2015-01-26 11:06 /GSOD/2006
drwxr-xr-x - hadoopid supergroup 0 2015-01-26 11:06 /GSOD/2007
drwxr-xr-x - hadoopid supergroup 0 2015-01-26 11:06 /GSOD/2008
drwxr-xr-x - hadoopid supergroup 0 2015-01-26 11:06 /GSOD/2009
你可以通过如下命令查看文件块的分布情况:
hdfs fsck /GSOD -files -blocks -racks结果如下:
/GSOD/2007 <dir>
/GSOD/2007/gsod_2007.tar 88842240 bytes, 1 block(s): OK
0. BP-1861083552-192.168.137.10-1420535325500:blk_1073742813_2006 len=88842240 repl=3 [/default-rack/192.168.137.13:50010, /default-rack/192.168.137.12:50010, /default-rack/192.168.137.11:50010]
/GSOD/2008 <dir>
/GSOD/2008/gsod_2008.tar 59555840 bytes, 1 block(s): OK
0. BP-1861083552-192.168.137.10-1420535325500:blk_1073742814_2007 len=59555840 repl=3 [/default-rack/192.168.137.12:50010, /default-rack/192.168.137.11:50010, /default-rack/192.168.137.13:50010]
/GSOD/2009 <dir>
/GSOD/2009/gsod_2009.tar 47206400 bytes, 1 block(s): OK
0. BP-1861083552-192.168.137.10-1420535325500:blk_1073742815_2008 len=47206400 repl=3 [/default-rack/192.168.137.13:50010, /default-rack/192.168.137.11:50010, /default-rack/192.168.137.12:50010]
Status: HEALTHY
Total size: 754892800 B
Total dirs: 11
Total files: 10
Total symlinks: 0
Total blocks (validated): 10 (avg. block size 75489280 B)
Minimally replicated blocks: 10 (100.0 %)
Over-replicated blocks: 0 (0.0 %)
Under-replicated blocks: 0 (0.0 %)
Mis-replicated blocks: 0 (0.0 %)
Default replication factor: 3
Average block replication: 3.0
Corrupt blocks: 0
Missing replicas: 0 (0.0 %)
Number of data-nodes: 3
Number of racks: 1
FSCK ended at Mon Jan 26 11:09:42 CST 2015 in 8 milliseconds
接下来我们在Hadoop上处理这些文件:
首先我新建了一个generate_input_list.sh来生成MR的input文件
#!/bin/bash
a=$1
rm ncdc_files.txt
hdfs dfs -rm /ncdc_files.txt
while [ $a -le $2 ]
do
filename="/GSOD/${a}/gsod_${a}.tar"
echo -e "$filename" >>ncdc_files.txt
a=`expr $a + 1`
done
hdfs dfs -put ncdc_files.txt /给generate_input_list.sh添加执行能力:
chmod +x generate_input_list.sh使用如下命令来生成在本例中需要处理的文件列表:
./generate_input_list.sh 2000 2009查看ncdc_files.txt文件:
more ncdc_files.txt结果如下:
hadoopid@namenode:~$ more ncdc_files.txt
/GSOD/2000/gsod_2000.tar
/GSOD/2001/gsod_2001.tar
/GSOD/2002/gsod_2002.tar
/GSOD/2003/gsod_2003.tar
/GSOD/2004/gsod_2004.tar
/GSOD/2005/gsod_2005.tar
/GSOD/2006/gsod_2006.tar
/GSOD/2007/gsod_2007.tar
/GSOD/2008/gsod_2008.tar
/GSOD/2009/gsod_2009.tar
我们在接下来的MapReduce中将读取ncdc_files.txt作为入参,读入的格式是Nline,这里我们指定了10个tar文件,所以会产生10个mapper作业
借来新建一个load_ncdc_map.sh文件:
#!/bin/bash
read hdfs_file
echo "$hdfs_file"
# Retrieve file from HDFS to local disk
echo "reporter:status:Retrieving $hdfs_file" >&2
/hadoop/hadoop260/bin/hdfs dfs -get $hdfs_file .
# Create local directory
target=`basename $hdfs_file .tar`
mkdir $target
echo "reporter:status:Un-tarring $hdfs_file to $target" >&2
tar xf `basename $hdfs_file` -C $target
# Unzip each station file and concat into one file
echo "reporter:status:Un-gzipping $target" >&2
for file in $target/*
do
gunzip -c $file >> $target.all
echo "reporter:status:Processed $file" >&2
done
# Put gzipped version into HDFS
echo "reporter:status:Gzipping $target and putting in HDFS" >&2
gzip -c $target.all | /hadoop/hadoop260/bin/hdfs dfs -put - /GSOD_ALL/$target.gz
rm `basename $hdfs_file`
rm -r $target
rm $target.all给load_ncdc_map.sh添加运行权限:
chmod +x load_ncdc_map.sh通过如下命令查看结果是否正确:
ll load_ncdc_map.sh结果如下:
-rwxrwxr-x 1 hadoopid hadoopid 792 Jan 26 11:21 load_ncdc_map.sh*
streaming的程序可以通过如下简单的方式检测下运气情况:
cat ncdc_files.txt |./load_ncdc_map.sh 结果如下:
reporter:status:Processed gsod_2000/996430-99999-2000.op.gz
reporter:status:Processed gsod_2000/996440-99999-2000.op.gz
reporter:status:Gzipping gsod_2000 and putting in HDFS
但是本例中的代码只会处理第一行记录,即2000年的
查看HDFS上目标文件是否生成:
hdfs dfs -ls /GSOD_ALL 结果如下:
Found 1 items
-rw-r--r-- 3 hadoopid supergroup 70931742 2015-01-26 11:27 /GSOD_ALL/gsod_2000.gz
接下来你需要修改load_ncdc_map.sh,使其可以在MapReduce的Streaming上正常运行,因为使用NLineInputFormat,所以只修改了read那一行:
#!/bin/bash
read offset hdfs_file
echo -e "$offset\t$hdfs_file"
接下来使用如下命令调用streaming:
hadoop jar /hadoop/hadoop260/share/hadoop/tools/lib/hadoop-streaming-2.6.0.jar \
-D mapreduce.job.reduces=0 \
-D mapreduce.map.speculative=false \
-D mapreduce.task.timeout=12000000 \
-inputformat org.apache.hadoop.mapred.lib.NLineInputFormat \
-input /ncdc_files.txt \
-output /output/1 \
-mapper load_ncdc_map.sh \
-file load_ncdc_map.sh作业提交后屏幕显示如下:

提示运行完毕后使用如下命令查看目标文件是否生成:
hdfs dfs -ls /GSOD_ALL结果如下:

运行的最后一行告诉你log的位置:
15/01/26 16:29:21 INFO streaming.StreamJob: Output directory: /output/1查看目录:
hdfs dfs -ls /output/1结果如下:
Found 11 items
-rw-r--r-- 3 hadoopid supergroup 0 2015-01-26 16:29 /output/1/_SUCCESS
-rw-r--r-- 3 hadoopid supergroup 71 2015-01-26 16:26 /output/1/part-00000
-rw-r--r-- 3 hadoopid supergroup 71 2015-01-26 16:22 /output/1/part-00001
-rw-r--r-- 3 hadoopid supergroup 71 2015-01-26 16:27 /output/1/part-00002
-rw-r--r-- 3 hadoopid supergroup 72 2015-01-26 16:26 /output/1/part-00003
-rw-r--r-- 3 hadoopid supergroup 72 2015-01-26 16:23 /output/1/part-00004
-rw-r--r-- 3 hadoopid supergroup 72 2015-01-26 16:29 /output/1/part-00005
-rw-r--r-- 3 hadoopid supergroup 72 2015-01-26 16:27 /output/1/part-00006
-rw-r--r-- 3 hadoopid supergroup 72 2015-01-26 16:20 /output/1/part-00007
-rw-r--r-- 3 hadoopid supergroup 72 2015-01-26 16:28 /output/1/part-00008
-rw-r--r-- 3 hadoopid supergroup 70 2015-01-26 16:25 /output/1/part-00009因为我们的input文件里面有10天记录,所以MR自动产生了10个mapper作业,也就产生了10个output文件
使用cat命令查看文件内容:
hdfs dfs -cat /output/1/part-00000hadoopid@namenode:~$ hdfs dfs -cat /output/1/part-00000
25 /GSOD/2001/gsod_2001.tar
hadoopid@namenode:~$ hdfs dfs -cat /output/1/part-00001
50 /GSOD/2002/gsod_2002.tar
hadoopid@namenode:~$ hdfs dfs -cat /output/1/part-00003
100 /GSOD/2004/gsod_2004.tar前面就是输入行的offset,每天记录占25字节“/GSOD/2000/gsod_2000.tar”
生成的文件用Notepad++打开就是如下的样子:

GSOD_DESC.txt有文件的描述
接下来书中的所有实验都可以继续展开了
NCDC 天气数据的预处理的更多相关文章
- hive查询ncdc天气数据
使用hive查询ncdc天气数据 在hive中将ncdc天气数据导入,然后执行查询shell,可以让hive自动生成mapredjob,快速去的想要的数据结果. 1. 在hive中创建ncdc表,这个 ...
- hadoop-hive查询ncdc天气数据实例
使用hive查询ncdc天气数据 在hive中将ncdc天气数据导入,然后执行查询shell,可以让hive自动生成mapredjob,快速去的想要的数据结果. 1. 在hive中创建ncdc表,这个 ...
- Hadoop学习之NCDC天气数据获取
期望目的 下载<Hadoop权威教程>里用到的NCDC天气数据,供后续在此数据基础上跑mapred程序. 操作过程 步骤一.编写简单的shell脚本,下载数据文件到本地文件系统 已知NCD ...
- 使用腾讯云无服务器云函数(SCF)分析天气数据
欢迎大家前往云+社区,获取更多腾讯海量技术实践干货哦~ 作者:李想 无服务器云函数(SCF)是腾讯云提供的Serverless执行环境,也是国内首款FaaS(Function as a Service ...
- 附录C 准备NCDC气象数据(加解释)
附录C 准备NCDC气象数据 这里首先简要介绍如何准备原始气象数据文件,以便我们能用Hadoop对它们进行分析.如果打算得到一份数据副本供Hadoop处理,可按照本书配套网站(网址为http://ww ...
- C#+HtmlAgilityPack+XPath带你采集数据(以采集天气数据为例子)
第一次接触HtmlAgilityPack是在5年前,一些意外,让我从技术部门临时调到销售部门,负责建立一些流程和寻找潜在客户,最后在阿里巴巴找到了很多客户信息,非常全面,刚开始是手动复制到Excel, ...
- caffe中关于数据进行预处理的方式
caffe的数据层layer中再载入数据时,会先要对数据进行预处理.一般处理的方式有两种: 1. 使用均值处理 transform_param { mirror: true crop_size: me ...
- C#抓取天气数据
使用C#写的一个抓取天气数据的小工具,使用正则匹配的方式实现,代码水平有限,供有需要的同学参考.压缩包中的两个sql语句是建表用的. http://files.cnblogs.com/files/yu ...
- C# 解析百度天气数据,Rss解析百度新闻以及根据IP获取所在城市
百度天气 接口地址:http://api.map.baidu.com/telematics/v3/weather?location=上海&output=json&ak=hXWAgbsC ...
随机推荐
- window.onload=function(){};
window.onload=function(){}; 只要页面加载完毕,这个事件才会触发 扩展事件--页面关闭后才触发的事件 window.onunload=function(){}; 扩展事件-- ...
- Java 多线程 - 死锁deadlock产生原因+避免方法
ref: java中产生死锁的原因及如何避免 https://blog.csdn.net/m0_38126177/article/details/78587845 java如何避免死锁 http:// ...
- [JZOJ4665] 【GDOI2017模拟7.21】数列
题目 题目大意 给你一个数列,让你找到一个最长的连续子序列,满足在添加了至多KKK个数之后,能够变成一条公差为DDD的等差数列. 思考历程 一眼看上去似乎是一道神题-- 没有怎么花时间思考,毕竟时间都 ...
- 思维构造——cf1090D
/* 只要找到两个没有关系的点即可 */ #include<bits/stdc++.h> using namespace std; #define maxn 100005 long lon ...
- LightOJ-1234-Harmonic Number-调和级数+欧拉常数 / 直接打表
In mathematics, the nth harmonic number is the sum of the reciprocals of the first n natural numbers ...
- IE6/IE7尿性笔记 && avalon && director
表单提交 [ie6] form默认特性(input回车以及点击type=submit的按钮会自动触发form submit),在ie6中,不能使button[submit],必须是input[subm ...
- 二分图最佳匹配KM算法 /// 牛客暑期第五场E
题目大意: 给定n,有n间宿舍 每间4人 接下来n行 是第一年学校规定的宿舍安排 接下来n行 是第二年学生的宿舍安排意愿 求满足学生意愿的最少交换次数 input 2 1 2 3 4 5 6 7 8 ...
- 使用Flume+Kafka+SparkStreaming进行实时日志分析
每个公司想要进行数据分析或数据挖掘,收集日志.ETL都是第一步的,今天就讲一下如何实时地(准实时,每分钟分析一次)收集日志,处理日志,把处理后的记录存入Hive中,并附上完整实战代码 1. 整体架构 ...
- Reboot- Linux必学的60个命令
1.作用 reboot命令的作用是重新启动计算机,它的使用权限是系统管理者. 2.格式 reboot [-n] [-w] [-d] [-f] [-i] 3.主要参数 -n: 在重开机前不做将记忆体资料 ...
- SQLServer 2008 还原数据库备份版本不兼容的问题
我们准备还原一个数据库备份的时候,经常会弹出这样的错误:System.Data.SqlClient.SqlError: 该数据库是在运行版本 10.50.1600 的服务器上备份的.该版本与此服务器( ...