tensor数据基操----索引与切片
玩过深度学习图像处理的都知道,对于一张分辨率超大的图片,我们往往不会采取直接压平读入的方式喂入神经网络,而是将它切成一小块一小块的去读,这样的好处就是可以加快读取速度并且减少内存的占用。就拿医学图像处理来说吧,医学CT图像一般都是比较大的,一张图片就可能达到500MB+,有的甚至超过1GB,下面是切过的一张已经被各种压缩过的肝脏CT图像的一角。
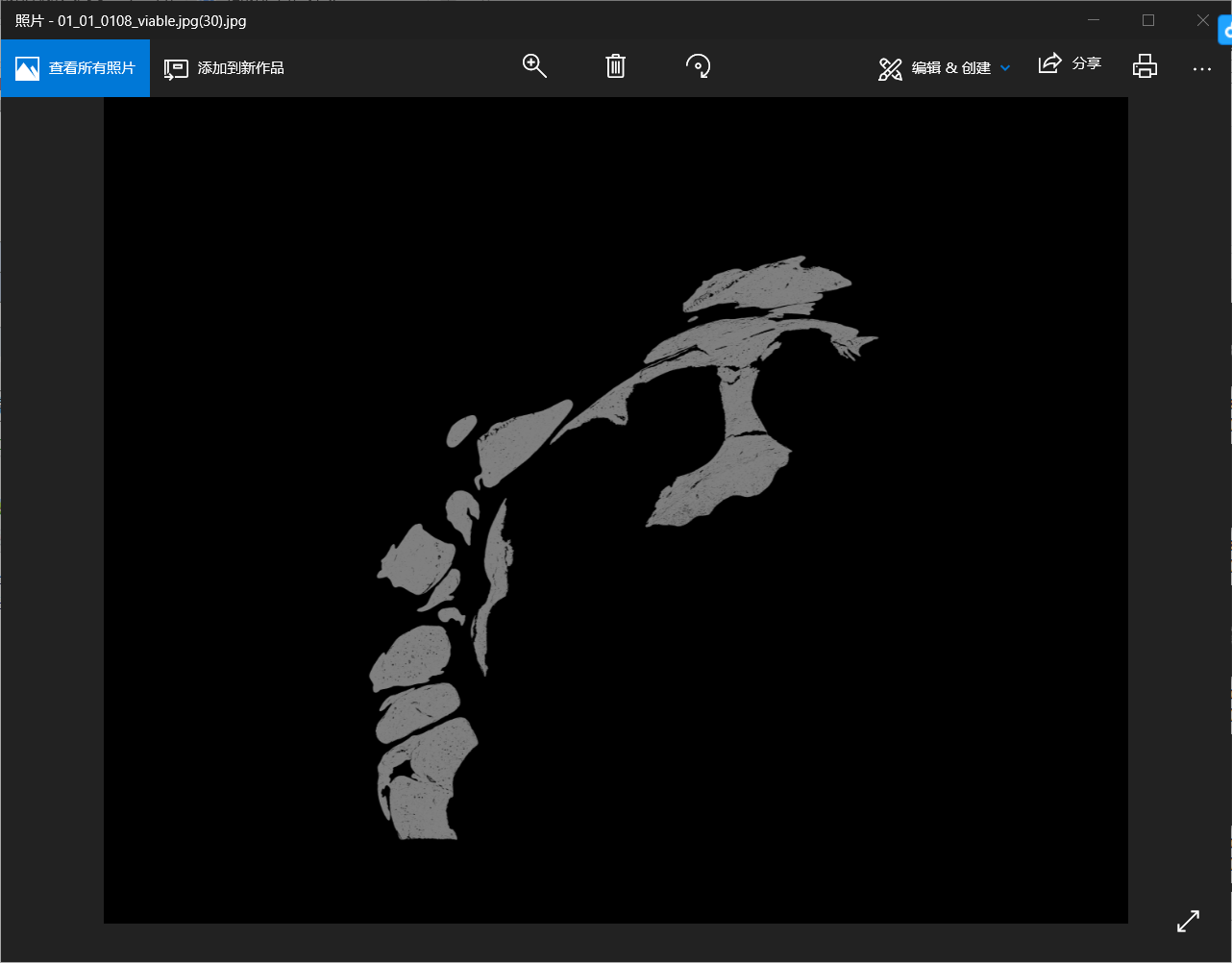
我们可以看到它的像素仍有5210*4200之多,如果直接把这样一张图片压平,将会得到一个5210*4200=21882000维的tensor,将这样一个上千万维的数据直接喂入神经网络,我不知道性能特别特别好的电脑能不能撑起来,反正我的电脑是肯定崩溃。那么如何处理这样图片呢?回到我们的标题----索引和切片。通过切片的方式我们可以把这张图片分成若干28*28(或者其他合适分辨率)的小图,分批次将这张图喂入神经网络,可想而知会取得不错的效果。接下来就记录几种索引切片的方式。
方式1:通过连续的[ ]
这种方式在各种编程语言中都很常见,即数组的索引,但是这种方式只能取到某一具体维度的数值,不能随心所欲的固定间隔或者非固定间隔的切片
a = tf.ones([1,5,5,3])
print(a[0][0])
print(a[0][0][0])
print(a[0][0][0][2])

方式2:通过[ , , ,……]
这种方式其实是numpy对方式1的一种在可读性方面的优化,和方式1相比,可读性明显提高
a = tf.random.normal([4,28,28,3])
print(a[1].shape)
print(a[1,2].shape)
print(a[1,2,3].shape)
print(a[1,2,3,2].shape)

方式3:一维tensor可通过[ :]
这种方式也是python中比较常用的数组切片方式,切片范围[ A:B)
a=tf.range(10)
print(a)
print(a[-1:])
print(a[-2:])
print(a[:2])
print(a[:-1])

方式4:对于多维tensor可通过[ ,:,:,:……]
相对前面几种切片方式都更加丰富,也可以完成多样的切片(跳过某一维度)start:end
a = tf.random.normal([4,28,28,3])
print(a[0,:,:,:].shape)
print(a[0,1,:,:].shape)
print(a[:,:,:,0].shape)
print(a[:,:,:,2].shape)
print(a[:,0,:,:].shape)

方式5:隔行采样[ : : ,: : ,: : ,……]
通过增加了一个:,使用方式start:end:step进行间隔采样(::step代表从最开始到最末尾以步长step间隔采样)
a = tf.random.normal([4,28,28,3])
print(a[:,0:28:2,0:28:2,:].shape)
print(a[:,:14,:14,:].shape)
print(a[:,14:,14:,:].shape)
print(a[:,::2,::2,:].shape)

注:若step<0则倒序采样
方式6:用…进行采样
...可以代替连续的:,增强代码的易书写性和可读性
a = tf.random.normal([2,4,28,28,3])
print(a[0,:,:,:,:].shape)
print(a[0,...].shape)
print(a[:,:,:,:,0].shape)
print(a[...,0].shape)
print(a[0,...,2].shape)
print(a[1,0,...,0].shape)
方式6:selective indexing
使用tf.gather、tf.gather_nd、tf.boolean_mask进行随机采样
(1)tf.gather(在某一维度指定index)
# 下面的tensor即表示,4个班级,每个班级35名学生,每个学生8门课的成绩
a = tf.random.normal([4,35,8])
# axis表示维度,indices表示在axis维度上要取数据的索引
print(tf.gather(a,axis=0,indices=[2,3]).shape) # 可理解为取第2、3个班级的学生成绩,同a[2:4].shape
print(tf.gather(a,axis=0,indices=[2,1,3,0]).shape) # 可理解为依次取第2、1、3、0个班级的学生成绩
print(tf.gather(a,axis=1,indices=[2,3,7,9,16]).shape) # 可理解为取所有班级第2,3,7,9,16个学生的成绩
print(tf.gather(a,axis=2,indices=[2,3,7]).shape) # 可理解为取所有班级所有学生第2,3,7门课的成绩

(2)tf.gather_nd(在多个维度指定index)
a = tf.random.normal([4,35,8])
# axis表示维度,indices表示在axis维度上要取数据的索引
print(tf.gather_nd(a,[0]).shape) # 可理解为取0号班级的所有成绩
print(tf.gather_nd(a,[0,1]).shape) # 可理解为取0号班级1号学生的成绩
print(tf.gather_nd(a,[0,1,2]).shape) # 可理解为取0号班级1号学生的第2门课成绩
print(tf.gather_nd(a,[[0,0],[1,1]]).shape) # 可理解为取0号班级0号学生和1号班级1号学生的成绩
print(tf.gather_nd(a,[[0,0],[1,1],[2,2]]).shape) # 可理解为取0号班级0号学生、1号班级1号学生、2号班级2号学生的成绩
print(tf.gather_nd(a,[[0,0,0],[1,1,1],[2,2,2]]).shape) # 可理解为0班0学0课,1班1学1课,2班2学2课的成绩
print(tf.gather_nd(a,[[[0,0,0],[1,1,1],[2,2,2]]]).shape) # shape与上不同

(3)tf.boolean_mask(通过True和False的方式选择数据)
a = tf.random.normal([4,28,28,3])
print(tf.boolean_mask(a,mask=[True,True,False,False]).shape)
print(tf.boolean_mask(a,mask=[True,True,False],axis=3).shape)
a = tf.ones([2,3,4])
print(tf.boolean_mask(a,mask=[[True,False,False],[False,True,True]]))

tensor数据基操----索引与切片的更多相关文章
- pytorch——不用包模拟简单线性预测,数据类型,创建tensor,索引与切片
常见的学习种类 线性回归,最简单的y=wx+b型的,就像是调节音量大小.逻辑回归,是否问题.分类问题,是猫是狗是猪 最简单的线性回归y=wx+b 目的:给定大量的(x,y)坐标点,通过机器学习来找出最 ...
- 编码,基本数据类型,str索引和切片,for循环
1. 编码 1. 最早的计算机编码是ASCII. 美国人创建的. 包含了英文字母(大写字母, 小写字母). 数字, 标点等特殊字符!@#$% 128个码位 2**7 在此基础上加了一位 2**8 8位 ...
- numpy之索引和切片
索引和切片 一维数组 一维数组很简单,基本和列表一致. 它们的区别在于数组切片是原始数组视图(这就意味着,如果做任何修改,原始都会跟着更改). 这也意味着,如果不想更改原始数组,我们需要进行显式的复制 ...
- Numpy系列(四)- 索引和切片
Python 中原生的数组就支持使用方括号([])进行索引和切片操作,Numpy 自然不会放过这个强大的特性. 单个元素索引 1-D数组的单元素索引是人们期望的.它的工作原理与其他标准Python序 ...
- 金融量化分析【day110】:Pandas-DataFrame索引和切片
一.实验文档准备 1.安装 tushare pip install tushare 2.启动ipython C:\Users\Administrator>ipython Python 3.7.0 ...
- Numpy学习二:数组的索引与切片
1.一维数组索引与切片#创建一维数组arr1d = np.arange(10)print(arr1d) 结果:[0 1 2 3 4 5 6 7 8 9] #数组的索引从0开始,通过索引获取第三个元素a ...
- 数据类型&字符串得索引及切片
一:数据类型 1):int 1,2,3用于计算 2):bool ture false 用于判断,也可做为if的条件 3):str 用引号引起来的都是str 存储少量数据,进行 ...
- 3.3Python数据处理篇之Numpy系列(三)---数组的索引与切片
目录 (一)数组的索引与切片 1.说明: 2.实例: (二)多维数组的索引与切片 1.说明: 2.实例: 目录: 1.一维数组的索引与切片 2.多维数组的索引与切片 (一)数组的索引与切片 1.说明: ...
- NumPy学习(索引和切片,合并,分割,copy与deep copy)
NumPy学习(索引和切片,合并,分割,copy与deep copy) 目录 索引和切片 合并 分割 copy与deep copy 索引和切片 通过索引和切片可以访问以及修改数组元素的值 一维数组 程 ...
随机推荐
- WeChall_Training: Get Sourced (Training)
The solution is hidden in this page Use View Sourcecode to get it 解题: 网页源码,最后一行 <!-- You are look ...
- (二)MyBatis延迟加载,一级缓存,二级缓存
延迟加载配置: 什么时候用延迟加载?比如现在有班级和学生表,一对多关系,你可能只需要班级的信息,而不需要该班级学生的信息,这时候可以进行配置,让查询时先查询到班级的信息,在之后需要学生信息时候,再进行 ...
- 【译文连载】 理解Istio服务网格(第三章 流控)
第3章 流控.............................................................................................. ...
- 使用sass语法生成自己的css的样式库
前言 先说一下 sass 和 scss的区别 sass 是一种缩进语法(即没有花括号和分号,只使用换行 缩进的方式去区别子元素,PS:这是我个人的理解) scss 是css-like语法 (它的语法 ...
- malloc返回地址的对齐问题
http://man7.org/linux/man-pages/man3/malloc.3.html RETURN VALUE top The malloc() and calloc( ...
- margin合并及解决办法
外边距合并指的是,当两个垂直外边距相遇时,它们将形成一个外边距. 合并后的外边距的高度等于两个发生合并的外边距的高度中的较大者 水平方向不会发生合并 只有普通文档流中块框的垂直外边距才会发生外边距合并 ...
- android手机遍历安装应用
/** * 遍历程序列表,判断是否安装安全支付服务 * * @return */ public boolean isMobile_spExist() { PackageManager manager ...
- 在Django中连接MySQL数据库(Python3)
我的环境: python3.6, Django2.1.5, MySQL8.0.15, win10, PyCharm, 要求:已经安装了MySQL数据库 ...
- UWP通过机器学习加载ONNX进行表情识别
首先我们先来说说这个ONNX ONNX是一种针对机器学习所设计的开放式的文件格式,用于存储训练好的模型.它使得不同的人工智能框架(如Pytorch, MXNet)可以采用相同格式存储模型数据并交互. ...
- 解决egg-mysql连接数据库报错问题
遇到这个问题,我在网上找了好多资料,最终于解决了!!!★,°:.☆( ̄▽ ̄)/$:.°★ . 我遇到的问题是这样的:链接mysql完全按照官网上做的,但是在yarn dev 时就是一直报错,错误我就不 ...