软件工程——Word-Counter
Python实现Word-Counter
一、前言
Github地址:https://github.com/hzquestion/Word-Counter
二、项目概述
实现一个统计程序,它能正确统计程序文件中的字符数、单词数、行数,以及还具备其他扩展功能,并能够快速地处理多个文件。
处理模式:
python Word-Counter.py [parameter] [filename]
基本功能列表(实现):
Word-Counter.py -c file.c//返回文件 file.c 的字符数Word-Counter.py -w file.c//返回文件 file.c 的词的数目Word-Counter.py -l file.c//返回文件 file.c 的行数
扩展功能(未实现):
-s递归处理目录下符合条件的文件。-a返回更复杂的数据(代码行 / 空行 / 注释行)。
高级功能(未实现):
-x参数。这个参数单独使用。如果命令行有这个参数,则程序会显示图形界面,用户可以通过界面选取单个文件,程序就会显示文件的字符数、行数等全部统计信息。
三、PSP
|
PSP2.1 |
Personal Software Process Stages |
预估耗时(分钟) |
实际耗时(分钟) |
|
Planning |
计划 |
10 |
10 |
|
· Estimate |
· 估计这个任务需要多少时间 |
480 |
600 |
|
Development |
开发 |
420 |
540 |
|
· Analysis |
· 需求分析 (包括学习新技术) |
120 |
200 |
|
· Design Spec |
· 生成设计文档 |
20 |
20 |
|
· Design Review |
· 设计复审 (和同事审核设计文档) |
20 |
10 |
|
· Coding Standard |
· 代码规范 (为目前的开发制定合适的规范) |
20 |
30 |
|
· Design |
· 具体设计 |
90 |
100 |
|
· Coding |
· 具体编码 |
110 |
130 |
|
· Code Review |
· 代码复审 |
20 |
20 |
|
· Test |
· 测试(自我测试,修改代码,提交修改) |
20 |
30 |
|
Reporting |
报告 |
60 |
60 |
|
· Test Report |
· 测试报告 |
30 |
30 |
|
· Size Measurement |
· 计算工作量 |
10 |
10 |
|
· Postmortem & Process Improvement Plan |
· 事后总结, 并提出过程改进计划 |
20 |
20 |
|
合计 |
490 |
610 |
四、解题思路描述
- 读取文件,并完成对文件的处理工作
- 对基础功能进行分析,先完成基础功能
- 测试运行,修复bug
- 优化代码,尝试完成扩展功能
五、设计实现过程
- 实现计算字符数的函数
- 实现计算单词数的函数
- 实现计算行数的函数
- 设计主函数输出结果
- 用不同的源代码文件进行测试
- 优化代码
六、代码说明
计算字符数
def Char_Count(filename):
#字符数统计
charcount = 0
try:
with open(filename, encoding = 'utf-8') as fi:
for x in fi:
match = re.findall(r'[\s]+', x)
for i in match:
x = x.replace(i, '')
charcount += len(x)
return charcount
except IOError:
print("Failed to open the file,please check if the path is correct.")
计算单词数
def Word_Count(filename, encoding = 'utf-8'):
#单词数统计
wordcount = 0
try:
with open(filename) as fi:
for x in fi:
match = re.findall(r'[a-zA-Z-\']+',x)
wordcount += len(match)
return wordcount
except IOError:
print("Failed to open the file,please check if the path is correct.")
计算行数
def Line_Count(filename, encoding = 'utf-8'):
#行数统计
linecount = 0
try:
with open(filename) as fi:
for x in fi:
linecount += 1
return linecount
except IOError:
print("Failed to open the file,please check if the path is correct.")
主函数输出
if __name__=='__main__':
#主函数
print('Word-Counter starts working...')
print('--------------------------------')
parser = argparse.ArgumentParser(description="This is a Word-Counter.")
parser.add_argument("-c", metavar = "--character", dest = "char_arg", help = "Return number of characters.")
parser.add_argument("-w", metavar = "--word", dest = "word_arg", help = "Return number of words.")
parser.add_argument("-l", metavar = "--line", dest = "line_arg", help = "Return number of lines.")
args = parser.parse_args()
if args.char_arg:
charcount = Char_Count(args.char_arg)
print("Number of characters:%s" % (charcount))
if args.word_arg:
wordcount = Word_Count(args.word_arg)
print("Number of words:%s" % (wordcount))
if args.line_arg:
linecount = Line_Count(args.line_arg)
print("Number of lines:%s" % (linecount))
七、测试运行
1.空文件

2.只有一个字符的文件(#)
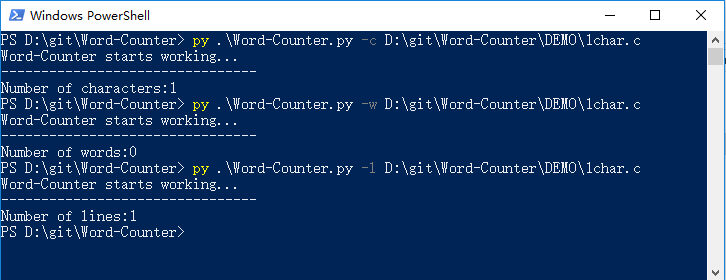
3.只有一个词的文件(test)
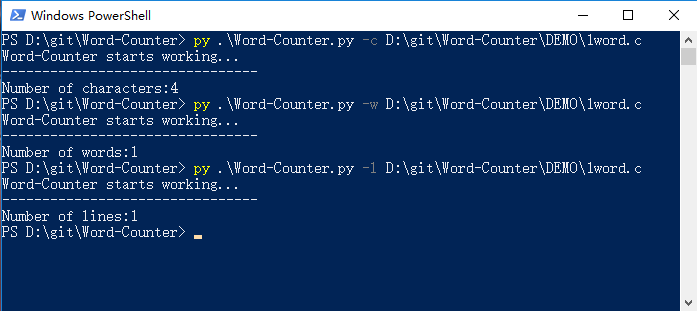
4.只有一行的文件(i like it very much.)

5.一个典型的源文件
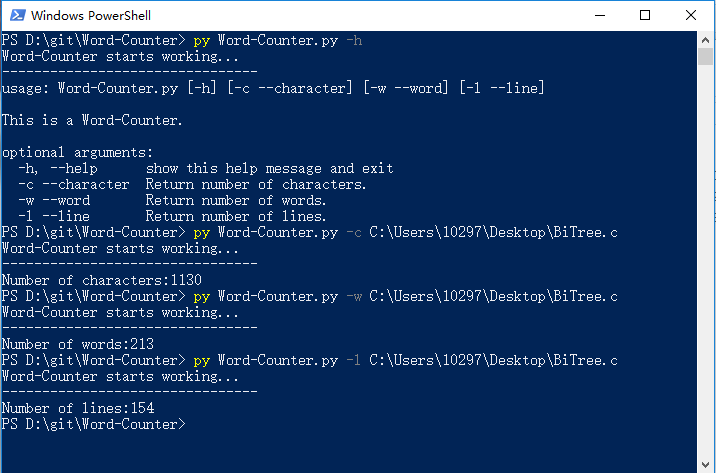
八、项目小结
此次是我第一次用python编写一个完整的小工程。由于暑假后半段时间有空闲,学了些许python,然后就拿这个作业来练练手了。
过程中遇到的问题有很多,所以学习新东西的时间出乎意料的长,说一些主要的问题:
一是对许多模块功能没有使用过,特别是argparse模块,花费了大量时间;
二是该项目涉及到的部分函数没有接触过,对其用法的学习也花费了不少时间;
三是其中对于读取文件的编码方式,一开始经常读取错误,后来把编码方式限定为‘utf-8’才解决问题;
四是对于.c文件中含有中文字符的代码文件的计算会出错,这个bug至今没有修复,由于开始项目的时间较晚,且最后在编辑博客贴运行结果截图的时候才偶然发现,已经没有足够的时间,留待日后有空再进行修复。
总的来说本次作业的完成不算是顺利,由于时间问题没有完全修复bug以及完成扩展功能,但也基本完成了基础功能。此次作业对我的提升还是挺大的,毕竟之前并未尝试独立完成一个软件工程,以后可以继续尝试。
软件工程——Word-Counter的更多相关文章
- 软件工程作业——Word Counter
github地址 https://github.com/Pryriat/Word_Counter 项目说明 wc.exe 是一个常见的工具,它能统计文本文件的字符数.单词数和行数.这个项目要求写一个命 ...
- 第三周作业--Word Counter
需求分析: 1.写出一个程序,模仿wc.exe,通过输入文件名,实现文件内容读取: 2.统计出文件内容的总字符数.总单词数.行数.每行字符数.每行单词数. 代码分析: 一.打开文件. FILE *fp ...
- 软件工程firstblood
https://github.com/happyeven/WC 项目要求 wc.exe 是一个常见的工具,它能统计文本文件的字符数.单词数和行数.这个项目要求写一个命令行程序,模仿已有wc.exe 的 ...
- 小白Linux入门 四
http://edu.51cto.com/lesson/id-11372.html 28了 文件管理类命令 目录: mkdir mkdir /tmp/x mkdir -p /tmp/a/b -pv b ...
- 【大数据】Linux下Storm(0.9版本以上)的环境配置和小Demo
一.引言: 在storm发布到0.9.x以后,配置storm将会变得简单很多,也就是只需要配置zookeeper和storm即可,而不再需要配置zeromq和jzmq,由于网上面的storm配置绝大部 ...
- Flex的正则表达式匹配速度与手工代码的比较
flex是一个词法分析器生成器,它是编译器和解释器编程人员的常用工具之一.flex的程序主要由一系列带有指令(称为动作代码)的正则表达式组成.在匹配输入时,flex会将所有的正则表达式翻译成确定性有穷 ...
- Storm工程创建
1.创建maven项目: pom.xml: <project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi=&quo ...
- Asp.net MVC Bundle 的使用与扩展
一.Asp.net 自带Bundle的使用: 1. 在Globale中注册与配置 BundleConfig.RegisterBundles(BundleTable.Bundles); public c ...
- Hadoop平台提供离线数据和Storm平台提供实时数据流
1.准备工作 2.一个Storm集群的基本组件 3.Topologies 4.Stream 5.数据模型(Data Model) 6.一个简单的Topology 7.流分组策略(Stream grou ...
- word2vec代码解释
以前看的国外的一篇文章,用代码解释word2vec训练过程,觉得写的不错,转过来了 原文链接 http://nbviewer.jupyter.org/github/dolaameng/tutorial ...
随机推荐
- [BZOJ1370][Baltic2003]Gang团伙 并查集+拆点
Description 在某城市里住着n个人,任何两个认识的人不是朋友就是敌人,而且满足: 1. 我朋友的朋友是我的朋友: 2. 我敌人的敌人是我的朋友: 所有是朋友的人组成一个团伙.告诉你关于这n个 ...
- 初识C++继承
先是自己凭借自己在课堂上的记忆打了一遍.自然出了错误. //编译错误 #include <iostream> #include <cstdlib> using namespac ...
- C++课程上 有关“指针” 的小结
上完了C++的第二节课以后,觉得应该对这个内容进行一个小结,巩固知识点,并对我的心情进行了一个侧面烘托... 开始上课的老师: 正在上课的我: 上去敲代码的我: 过程是这样的: 下来的我: 非常的尴尬 ...
- DFS回溯-函数递归-xiaoz triangles
题目:小z 的三角形 ★实验任务 三角形的第1 行有n 个由"+"和"-"组成的符号,以后每行符 号比上行少1 个,2 个同号下面是"+", ...
- Python的collections模块中的OrderedDict有序字典
如同这个数据结构的名称所说的那样,它记录了每个键值对添加的顺序. ? 1 2 3 4 5 6 d = OrderedDict() d['a'] = 1 d['b'] = 10 d['c'] = 8 f ...
- Python 以指定宽度格式化输出
当对一组数据输出的时候,我们有时需要输出以指定宽度,来使数据更清晰.这时我们可以用format来进行约束 mat = "{:20}\t{:28}\t{:32}" print(mat ...
- Jmeter高阶学习,运用NotePad++编写工程,随意复制多个工程到同一个工程
Jmeter创建了工程之后,保存文件后就是一个jmx后缀的文件,你有没有试过单独用文本编辑器打开文件,编辑文件? Step1: 最简单的Jmeter工程,只有一个测试计划 <?xml versi ...
- tomcat和java环境
mac tomcat http://blog.csdn.net/huyisu/article/details/38372663 mac jdk 1.8 http://wlb.wlb.blog.163. ...
- dat.gui.js
].appendChild(b)},inject:function(e,a){a=a||document;].appendChild(b)}}}(); dat.utils.common=functio ...
- Vue.js教程--基础(实例 模版语法template computed, watch v-if, v-show v-for, 一个组件的v-for.)
官网:https://cn.vuejs.org/v2/guide/index.html Vue.js 的核心是一个允许采用简洁的模板语法来声明式地将数据渲染进 DOM 的系统. 视频教程:https: ...