centos7配置hadoop
hadoop压缩包下载:
链接:https://pan.baidu.com/s/1dz0Hh75VNKEebcYcbN-4Hw
提取码:g2e3
java压缩包下载:
链接:https://pan.baidu.com/s/1DriDVSKQWAQme0QuoiEnQg
提取码:cmag
centos7的安装和配置可以再网上搜到,但是在安装的时候一定要注意要选择图形化界面安装,这样在进行后续的操作的时候比较方便
本人实在vbox上面安装的
ip地址的配置:https://www.cnblogs.com/xuzhaoyang/p/11264573.html由于centos采用的小红帽的内核所以在文件的结构上大同小异
然后配置本地的yum源,首先将盘片挂载到虚拟机上面之后
mkdir /mnt/cdrom
mount /dev/cdrom /mnt/cdrom
然后将/etc/yum.repos.d路径下的文件都删除,然后创建本地的yum源
vi /etc/yum.repos.d/CentOS-local.repo
文件里面输入
[base-local]#这个是本源的名字,不能和其他的重复(随便,不重复)
name=CentOS-local #名字(随便)
baseurl=file:///mnt/cdrom #上方步骤一挂载镜像创建的目录
enabled=1 #yum源是否启用 1-启用 0-不启用
gpgcheck=1 #安全检测 1-开启 0-不开启
gpgkey=file:///etc/pki/rpm-gpg/RPM-GPG-KEY-CentOS-7
然后保存,这样本地的yum源就配置好了
一、 安装ssh免密登录
命令:ssh-keygen
overwrite(覆盖写入)输入y
一路回车

将生成的密钥发送到本机地址
ssh-copy-id localhost

(若报错命令无法找到则需要安装openssh-clients)
yum –y install openssh-clients
测试免密设置是否成功
ssh localhost date
卸载已有java
确定JDK版本
rpm –qa | grep jdk
rpm –qa | grep gcj
如果有版本号的话,
切换到root用户,根据结果卸载java
yum -y remove java-1.8.0-openjdk-headless.x86_64
yum -y remove java-1.7.0-openjdk-headless.x86_64

一、 安装java
切换回hadoop用户,命令:su hadoop
查看下当前目标文件,命令:ls,查看当前路径下的文件
新建一个app文件夹,命令:mkdir app

将桌面的hadoop文件夹中的java及hadoop安装包移动到app文件夹中,可以使用Xftp进行传输,Xftp使用步骤参考:https://www.cnblogs.com/xuzhaoyang/p/11264587.html
解压java程序包,命令:tar –zxvf jdk-7u79-linux-x64.tar.gz
创建软连接
ln –s jdk1.8.0_141 jdk

配置jdk环境变量
切换到root用户
再输入vi /etc/profile
输入
export JAVA_HOME=/home/hadoop/app/jdk1.8.0_141
export JAVA_JRE=JAVA_HOME/jre
export CLASSPATH=.:$JAVA_HOME/lib:$JAVA_JRE/lib
export PATH=$PATH:$JAVA_HOME/bin
保存退出,并使/etc/profile文件生效
source /etc/profile
能查询jdk版本号,说明jdk安装成功
java -version

安装hadoop
切换回hadoop用户,解压缩hadoop-2.6.0.tar.gz安装包
创建软连接,命令:ln -s hadoop-2.7.0 hadoop
然后验证单机模式的Hadoop是否安装成功,命令:
hadoop/bin/hadoop version

配置伪分布式登录
进入hadoop/etc/hadoop目录,修改相关配置文件
cd etc/
cd hadoop/
修改core-site.xml配置文件
<configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://localhost:9000</value>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>file:/home/hadoop/data/tmp</value>
</property>
<property>
<name>hadoop.proxyuser.hadoop.hosts</name>
<value>*</value>
</property>
<property>
<name>hadoop.proxyuser.hadoop.groups</name>
<value>*</value>
</property>
</configuration>
修改hdfs-site.xml配置文件
<configuration>
<property>
<name>dfs.namenode.name.dir</name>
<value>/home/hadoop /data/dfs/name</value>
<final>true</final>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>/home/hadoop /data/dfs/data</value>
<final>true</final>
</property>
<property>
<name>dfs.replication</name>
<value></value>
</property>
<property>
<name>dfs.permissions</name>
<value>false</value>
</property>
</configuration>
修改hadoop-env.sh配置文件 vi ~/app/Hadoop/etc/Hadoop/Hadoop-env.sh
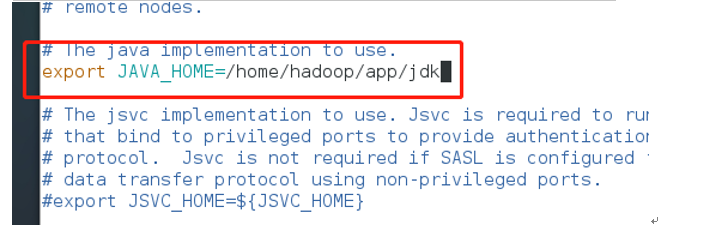
修改mapred-site.xml.template配置文件
<configuration>
<property>
<name>mapreduce.frameword.name</name>
<value>yarn</value>
</property>
</configuration>
修改yarn-site.xml配置文件
<property>
<name>yarn.nodemanager.aux-servies</name>
<value>mapreduce_shuffle</value>
</property>
</configuration>
配置hadoop环境变量 vi ~/.bashrc
JAVA_HOME=/home/localhost/app/jdk
HADOOP_HOME=/home/localhost/app/hadoop
CLASSPATH=.:$JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib/tools.jar
PATH=$JAVA_HOME/bin:$HADOOP_HOME/bin:$PATH
export JAVA_HOME CLASSPATH PATH HADOOP_HOME
使修改生效,命令:source ~/.bashrc
在hadoop相关配置文件中配置了多个数据目录,提前建立这些文件夹
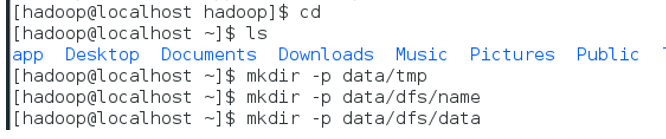
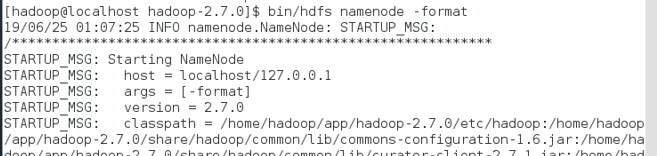
格式化namenode
在启动hadoop集群前需要格式化namenode。需要注意的是,第一次安装Hadoop集群的时候需要格式化Namenode,以后直接启动Hadoop集群即可,不需要重复格式化Namenode。
切回到hadoop目录,输入如下命令:
bin/hdfs namenode -format
启动hadoop伪分布式集群
sbin/start-all.sh

centos7配置hadoop的更多相关文章
- Centos7配置hadoop伪分布式
修改hostname(可选) 通过下面命令查看hostname信息 hostnamectl 通过下面命令修改hostname hostnamectl set-hostname gy01 如图所示 下面 ...
- centos7配置hadoop集群
一:测试环境搭建规划: 主机名称 IP 用户 HDFS YARN hadoop11 192.168.1.101 hadoop NameNode,DataNode NodeManager hadoop1 ...
- centos7配置Hadoop集群环境
参考: https://blog.csdn.net/pucao_cug/article/details/71698903 设置免密登陆后,必须重启ssh服务 systermctl restart ss ...
- Centos7中hadoop配置
Centos7中hadoop配置 1.下载centos7安装教程: http://jingyan.baidu.com/article/a3aad71aa180e7b1fa009676.html (注意 ...
- CentOS 6.4 配置 Hadoop 2.6.5
(以下所有文件:点此链接 里面还有安装的视频教学,我这里是亲测了一次,如有报错请看红色部分.实践高于理论啊兄弟们!!) 一.安装CentOS 6.4 在VMWare虚拟机上,我设置的用户是hadoop ...
- Centos7搭建hadoop完全分布式
虽然说是完全分布式,但三个节点也都是在一台机器上.拿来练手也只能这样咯,将就下.效果是一样滴.这个我自己都忘了步骤,一起来回顾下吧. 必备知识: Linux基本命令 vim基本命令 准备软件: VMw ...
- CentOS7下Hadoop伪分布式环境搭建
CentOS7下Hadoop伪分布式环境搭建 前期准备 1.配置hostname(可选,了解) 在CentOS中,有三种定义的主机名:静态的(static),瞬态的(transient),和灵活的(p ...
- Hadoop单机模式安装-(3)安装和配置Hadoop
网络上关于如何单机模式安装Hadoop的文章很多,按照其步骤走下来多数都失败,按照其操作弯路走过了不少但终究还是把问题都解决了,所以顺便自己详细记录下完整的安装过程. 此篇主要介绍在Ubuntu安装完 ...
- 攻城狮在路上(陆)-- 配置hadoop本地windows运行MapReduce程序环境
本文的目的是实现在windows环境下实现模拟运行Map/Reduce程序.最终实现效果:MapReduce程序不会被提交到实际集群,但是运算结果会写入到集群的HDFS系统中. 一.环境说明: ...
随机推荐
- java.lang.OutOfMemoryError:PermGen space tomcat7 内存溢出
Tomcat 解决 在启动项目的时候,会报java.lang.OutOfMemoryError:PermGen space错误. 在tomcat/bin/catalina.sh windows li ...
- CentOS7 升级Python2.x到3.x
CentOS 7 中默认安装了 Python,版本比较低(2.7.5),为了使用新版 3.x,需要对旧版本进行升级.由于很多基本的命令.软件包都依赖旧版本,比如:yum.所以,在更新 Python 时 ...
- linux redhat 安装了jdk检查版本不是自己安装的版本的解决办法
Linux下安装jdk java -version 不是自己所需要的版本 设置环境变量,这是最重要的 在etc/profile文件下添加 export JAVA_HOME=/usr/java/jdk1 ...
- HNOI2009有趣的数列
首先next_permutation打表,发现Cat规律. 其实考试的时候这么做没什么问题,而且可以节省异常多的时间,那么现在我们来想一下why. 首先我拿模型法解释一下,我们把2n个数看成2n个人, ...
- iOS开发~防止navigation多次push一个页面
在点击push下一个页面时,因为各种原因,点一下cell或按钮没有响应,用户可能就多点几下,这时候会打开好几个一样的页面. 这是因为push后的页面有耗时操作或者刚好push到另一个页面时,另一个页面 ...
- Apache Flink - 作业和调度
Scheduling: Flink中的执行资源通过任务槽(Task Slots)定义.每个TaskManager都有一个或多个任务槽,每个槽都可以运行一个并行任务管道(pipeline).管道由多个连 ...
- xposed代码示例
package com.example.xposedhook; import android.util.Log; import de.robv.android.xposed.IXposedHookLo ...
- Hive和Hadoop
我最近研究了hive的相关技术,有点心得,这里和大家分享下. 首先我们要知道hive到底是做什么的.下面这几段文字很好的描述了hive的特性: 1.hive是基于Hadoop的一个数据仓库工具,可以将 ...
- MyBatis 与 Hibernate
MyBatis 是一个优秀的基于 Java 的持久层框架,它内部封装了 JDBC,使开发者只需关注 SQL 语句本身,而不用再花费精力去处理诸如注册驱动.创建 Connection.配置 Statem ...
- ML_Review_PCA(Ch4)
Note sth about PCA(Principal Component Analysis) ML6月20日就要考试了,准备日更博客,来记录复习一下这次ML课所学习的一些方法. 博客是在参考老 ...