centos7配置Hadoop集群环境
参考:
https://blog.csdn.net/pucao_cug/article/details/71698903
设置免密登陆后,必须重启ssh服务
systermctl restart sshd.service
ssh服务介绍:
两种登陆方式:
1.密码登陆
2.密钥登陆
启动
http://192.168.5.130:8088/cluster
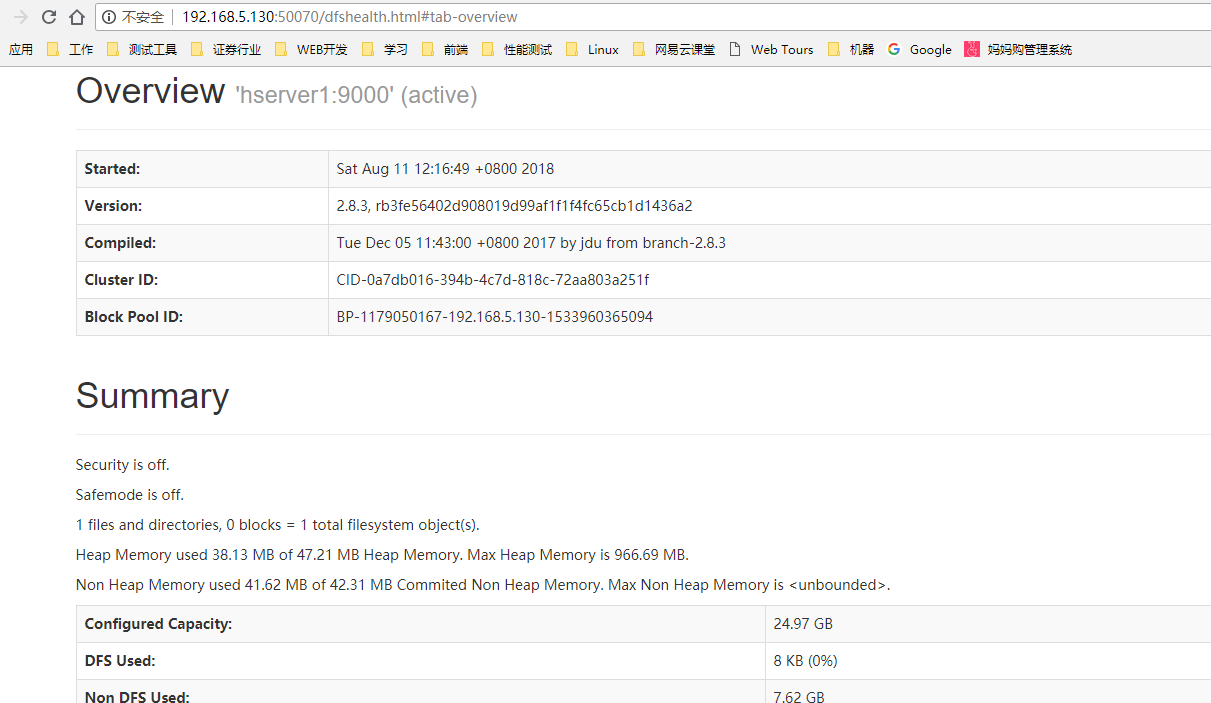
http://192.168.5.130:50070/dfshealth.html#tab-overview
安装Hadoop家族工具
hive 结合 mysql的jdbc插件 https://blog.csdn.net/pucao_cug/article/details/71773665
impala
sqoop https://blog.csdn.net/pucao_cug/article/details/72083172
hbase https://blog.csdn.net/pucao_cug/article/details/72229223
启动会报错
https://blog.csdn.net/l1028386804/article/details/51538611
安装zookeeper
参考:https://blog.csdn.net/pucao_cug/article/details/72228973
zookeeper status

原因是:myid和 zoo.cfg里的配置不匹配
hive 导入txt文件数据到表中:
create table student(id int,name string) row format delimited fields terminated by '\t';
load data local inpath '/opt/hadoop/hive/student.txt' into table db_hive_edu.student;
-- hive导入csv文件
create table table_name(
id string,
name string,
age string
)
row format serde
'org.apache.hadoop.hive.serde2.OpenCSVSerde'
with
SERDEPROPERTIES
("separatorChar"=",","quotechar"="\"")
STORED AS TEXTFILE;
load data local inpath '/opt/hadoop/hive/table_name.csv' overwrite into table table_name;
将表转换成ORC表:
create table table_name_orc(
id string,
name string,
age string
)row format delimited fields terminated by "\t" STORED AS ORC insert overwrite table table_name_orc select * from table_name
centos7配置Hadoop集群环境的更多相关文章
- CentOS7 安装Hadoop集群环境
先按照上一篇安装与配置好CentOS以及zookeeper http://www.cnblogs.com/dopeter/p/4609276.html 本章介绍在CentOS搭建Hadoop集群环境 ...
- centos7配置hadoop集群
一:测试环境搭建规划: 主机名称 IP 用户 HDFS YARN hadoop11 192.168.1.101 hadoop NameNode,DataNode NodeManager hadoop1 ...
- hadoop集群环境搭建之安装配置hadoop集群
在安装hadoop集群之前,需要先进行zookeeper的安装,请参照hadoop集群环境搭建之zookeeper集群的安装部署 1 将hadoop安装包解压到 /itcast/ (如果没有这个目录 ...
- hadoop集群环境搭建之zookeeper集群的安装部署
关于hadoop集群搭建有一些准备工作要做,具体请参照hadoop集群环境搭建准备工作 (我成功的按照这个步骤部署成功了,经实际验证,该方法可行) 一.安装zookeeper 1 将zookeeper ...
- hadoop集群环境搭建准备工作
一定要注意hadoop和linux系统的位数一定要相同,就是说如果hadoop是32位的,linux系统也一定要安装32位的. 准备工作: 1 首先在VMware中建立6台虚拟机(配置默认即可).这是 ...
- hadoop集群环境的搭建
hadoop集群环境的搭建 今天终于把hadoop集群环境给搭建起来了,能够运行单词统计的示例程序了. 集群信息如下: 主机名 Hadoop角色 Hadoop jps命令结果 Hadoop用户 Had ...
- Hadoop集群环境安装
转载请标明出处: http://blog.csdn.net/zwto1/article/details/45647643: 本文出自:[zhang_way的博客专栏] 工具: 虚拟机virtual ...
- Hadoop集群环境搭建步骤说明
Hadoop集群环境搭建是很多学习hadoop学习者或者是使用者都必然要面对的一个问题,网上关于hadoop集群环境搭建的博文教程也蛮多的.对于玩hadoop的高手来说肯定没有什么问题,甚至可以说事“ ...
- Linux中安装配置hadoop集群
一. 简介 参考了网上许多教程,最终把hadoop在ubuntu14.04中安装配置成功.下面就把详细的安装步骤叙述一下.我所使用的环境:两台ubuntu 14.04 64位的台式机,hadoop选择 ...
随机推荐
- 使用pm2来保证Spring Boot应用稳定运行
Spring Boot开发web应用就像开发普通的java程序一般简洁,因为其内嵌了web容易,启动的时候只需要一条命令java -jar server.jar即可,非常方便.但是由此而来的问题是万一 ...
- python函数嵌套定义
python的这个特性是很特别的,与C#和C++都不一样.请看下面的例子 def outFun(): def innerFun_0():#1.在内部定义一个函数 print("i am fi ...
- 两个时间点计算相隔几年,几个月,几天-java
本文采用Calendar 实现 ,当然也可以用java8提供的愉快且方便的时间处理- LocalDate import java.text.ParseException; import java.te ...
- ActiveMQ(1)---初识ActiveMQ
消息中间件的初步认识 什么是消息中间件? 消息中间件是值利用高效可靠的消息传递机制进行平台无关的数据交流,并基于数据通信来进行分布式系统的集成.通过提供消息传递和消息排队模型,可以在分布式架构下扩展进 ...
- Maven Return code is: 401
maven 打包到仓库 需要配置认证: setting.xml <server><id>releases</id><username>admin< ...
- redis安装--单机
本例基于CentOS7.2系统安装 环境需求: 关闭防护墙,selinux 安装好gcc等编译需要的组件 yum -y install gcc c++ 到redis官网下载合适版本的redis安装包, ...
- 译:SOS_SCHEDULER_YIELD类型等待在虚拟机环境中的增多
原文出处:Increased SOS_SCHEDULER_YIELD waits on virtual machines 注: 原文的用词是Increased,想译作增强(增长),或者加强,这么译起来 ...
- python虚拟环境的搭建
使用python虚拟环境作用是项目与项目之间相互隔离,互相不受影响,比如当需要同时部署A.B两个项目时,A项目依赖C库的1.0版本,B项目依赖C库的2.0版本,假如不使用虚拟环境隔离A项目和B项目就很 ...
- 阿里巴巴Java开发手册与自己开发对照笔记
一编程规约 (一)命名风格 某些时候在命名常量的时候,会觉得太长而减少长度导致命名不清. 抽象类及测试类写得比较少. 这一点值得注意,在开发中,布尔变量我都是使用is开始. 关于包名和类名的单数和复数 ...
- python--第十二天总结(Python操作 RabbitMQ、Redis、Memcache、SQLAlchemy)
Memcached Memcached 是一个高性能的分布式内存对象缓存系统,用于动态Web应用以减轻数据库负载.它通过在内存中缓存数据和对象来减少读取数据库的次数,从而提高动态.数据库驱动网站的速度 ...