spark教程(九)-操作数据库
数据库也是 spark 数据源创建 df 的一种方式,因为比较重要,所以单独算一节。
本文以 postgres 为例
安装 JDBC
首先需要 安装 postgres 的客户端驱动,即 JDBC 驱动,这是官方下载地址,JDBC,根据数据库版本下载对应的驱动
上传至 spark 目录下的 jars 目录
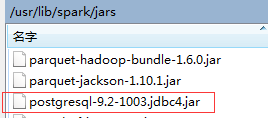
并设置环境变量
export SPARK_CLASSPATH = /usr/lib/spark/jars
编程模板
如何操作数据库,不同的版本方法不同,网上的教程五花八门,往往尝试不成功。
其实我们可以看 spark 自带的样例, 路径为 /usr/lib/spark/examples/src/main/python/sql 【编码时,sparkSession 需要声明 spark jars 的驱动路径,代码调用 API JDBC To Other Databases】
我从 datasource.py 中找到了基本的读写方法,其他自己可以看看
def jdbc_dataset_example(spark):
# $example on:jdbc_dataset$
# Note: JDBC loading and saving can be achieved via either the load/save or jdbc methods
# Loading data from a JDBC source
jdbcDF = spark.read \
.format("jdbc") \
.option("url", "jdbc:postgresql:dbserver") \
.option("dbtable", "schema.tablename") \
.option("user", "username") \
.option("password", "password") \
.load() jdbcDF2 = spark.read \
.jdbc("jdbc:postgresql:dbserver", "schema.tablename",
properties={"user": "username", "password": "password"}) # Specifying dataframe column data types on read
jdbcDF3 = spark.read \
.format("jdbc") \
.option("url", "jdbc:postgresql:dbserver") \
.option("dbtable", "schema.tablename") \
.option("user", "username") \
.option("password", "password") \
.option("customSchema", "id DECIMAL(38, 0), name STRING") \
.load()
# Saving data to a JDBC source
jdbcDF.write \
.format("jdbc") \
.option("url", "jdbc:postgresql:dbserver") \
.option("dbtable", "schema.tablename") \
.option("user", "username") \
.option("password", "password") \
.save() jdbcDF2.write \
.jdbc("jdbc:postgresql:dbserver", "schema.tablename",
properties={"user": "username", "password": "password"}) # Specifying create table column data types on write
jdbcDF.write \
.option("createTableColumnTypes", "name CHAR(64), comments VARCHAR(1024)") \
.jdbc("jdbc:postgresql:dbserver", "schema.tablename",
properties={"user": "username", "password": "password"})
# $example off:jdbc_dataset$
实战案例
仅供参考,请确保 spark 能连接上数据库
from pyspark.sql import SparkSession
import os # 获取 环境变量 SPARK_CLASSPATH, 当然需要你事先设定了 该变量
# 如果没有设定 SPARK_CLASSPATH, 得到 后面的值 /usr/lib/spark/jars/*
sparkClassPath = os.getenv('SPARK_CLASSPATH', '/usr/lib/spark/jars/*') ### 创建 sparkSession
# spark.driver.extraClassPath 设定了 jdbc 驱动的路径
spark = SparkSession \
.builder \
.appName("Python Spark SQL basic example") \
.master("local") \
.config("spark.driver.extraClassPath", sparkClassPath) \
.getOrCreate() ### 连接数据库并读取表
# airDF 已经是个 DataFrame
airDF = spark.read \
.format("jdbc") \
.option("url", "jdbc:postgresql://172.16.89.80:5432/postgres") \
.option("driver", "org.postgresql.Driver") \
.option("dbtable", "road_point002") \
.option("user", "postgres") \
.option("password", "postgres") \
.load() ### 打印schema
airDF.printSchema() # df 的表结构,我们看到的就是 列名即格式等 ### 只打印前20条 -- dsl 方式
airDF.select('id', 'road_number', 'speed_t').show() # id, road_number, speed_t 列名 ### 把 df 转成 table -- sql 方式
def func(x):
print(x) airDF.registerTempTable('pg')
spark.sql("select * from pg limit 20").foreach(func) ### 存储为 RDBMS、xml、json等格式
## 存到数据库
airDF.write.jdbc("jdbc:postgresql://172.16.89.80:5432/postgres" ,
table = "test",mode="append", properties={"user": "postgres", "password": "postgres"}) # 写入数据库 ## 存为 json
airDF.write.format('json').save('jsoin_path') # 存入分区文件
airDF.coalesce(1).write.format('json').save('filtered.json') # 存入单个文件,不建议使用
spark教程(九)-操作数据库的更多相关文章
- Python教程:操作数据库,MySql的安装详解
各位志同道合的同仁请点击上方关注 本教程是基于Python语言的深入学习.本次主要介绍MySql数据库软件的安装.不限制语言语法,对MySql数据库安装有疑惑的各位同仁都可以查看一下. 如想查看学习P ...
- Spring Boot教程(二十九)使用JdbcTemplate操作数据库
使用JdbcTemplate操作数据库 Spring的JdbcTemplate是自动配置的,你可以直接使用@Autowired来注入到你自己的bean中来使用. 举例:我们在创建User表,包含属性n ...
- Spark Streaming通过JDBC操作数据库
本文记录了学习使用Spark Streaming通过JDBC操作数据库的过程,源数据从Kafka中读取. Kafka从0.10版本提供了一种新的消费者API,和0.8不同,因此Spark Stream ...
- HelloDjango 系列教程:第 04 篇:Django 迁移、操作数据库
文中涉及的示例代码,已同步更新到 HelloGitHub-Team 仓库 我们已经编写了博客数据库模型的代码,但那还只是 Python 代码而已,django 还没有把它翻译成数据库语言,因此实际上这 ...
- Python学习(二十九)—— pymysql操作数据库优化
转载自:http://www.cnblogs.com/liwenzhou/articles/8283687.html 我们之前使用pymysql操作数据库的操作都是写死在视图函数中的,并且很多都是重复 ...
- python3入门教程(二)操作数据库(一)
概述 最近在准备写一个爬虫的练手项目,基本想法是把某新闻网站的内容分类爬取下来,保存至数据库,再通过接口对外输出(提供后台查询接口).那么问题就来了,python到底是怎么去操作数据库的呢?我们今天就 ...
- Android学习之基础知识九 — 数据存储(持久化技术)之使用LitePal操作数据库
上一节学习了使用SQLiteDatabase来操作SQLite数据库的方法,接下来我们开始接触第一个开源库:LitePal.LitePal是一款开源的Android数据库框架,它采用了对象关系映射(O ...
- 使用JdbcTemplate操作数据库(二十九)
使用JdbcTemplate操作数据库 Spring的JdbcTemplate是自动配置的,你可以直接使用@Autowired来注入到你自己的bean中来使用. 举例:我们在创建User表,包含属性n ...
- 第二百八十九节,MySQL数据库-ORM之sqlalchemy模块操作数据库
MySQL数据库-ORM之sqlalchemy模块操作数据库 sqlalchemy第三方模块 sqlalchemysqlalchemy是Python编程语言下的一款ORM框架,该框架建立在数据库API ...
随机推荐
- AtCoder AGC031D A Sequence of Permutations (群论、置换快速幂)
题目链接 https://atcoder.jp/contests/agc031/tasks/agc031_d 题解 这居然真的是个找规律神题... 首先要明白置换的一些基本定义,置换\(p\)和\(q ...
- JavaWeb-SpringSecurity初认识
Spring Security 安全 百度百科 功能:Spring Security对Web安全性的支持大量地依赖于Servlet过滤器.这些过滤器拦截进入请求,并且在应用程序处理该请求之前进行某些安 ...
- 费马小定理证明 (copy的,自己捋清楚)
费马小定理:假如p是质数,且gcd(a,p)=1,那么 a^(p-1)≡1(mod p) 证明(copy的百度百科,加点自己的解释) 引理1. 若a,b,c为任意3个整数,m为正整数,且(m,c)=1 ...
- DP&图论 DAY 5 上午
DP&图论 DAY 5 上午 POJ 1125 Stockbroker Grapevine 有 N 个股票经济人可以互相传递消息,他们之间存在一些单向的通信路径.现在有一个消息要由某个人开 ...
- [占位符 ]
在做项目的时候,数据库中的数据会存在空值;这样,我们需要在前台给它加以判断, 如果我们不加以判断也是可行的,我们需要添加一个空白占位符 空白占位符 是个不错的选择,这样我们的页面显示数据的时候就不会 ...
- Android studio 项目支持JNI方法
步骤: 1. build.gradle 配置如下,主要两项 ndk 和 sourceSets apply plugin: 'com.android.application' android { com ...
- openLdap安装教程
环境 操作系统:centOS 7.0 OpenLDAP:2.4.X 安装 从yum源安装 yum install openldap openldap-servers openldap-clients ...
- Python进阶学习之特殊方法实例详析
Python进阶学习之特殊方法实例详析 最近在学习python,学习到了一个之前没接触过的--特殊方法. 什么是特殊方法?当我们在设计一个类的时候,python中有一个用于初始化的方法$__init_ ...
- 使用jdk自带工具jvisualvm 分析内存dump文件
1.获取dump文件 使用 以下命令 创建 进程PID = 16231的 dump文件,命名为 order.hprof jmap -dump:format=b,file=order.hprof 162 ...
- C基础知识(9):输入输出、文件读写
输入输出 (1) getchar() & putchar() 函数: 读写字符. (2) scanf() 和 printf() 函数:根据提供的format来转换输入为其他数据类型,并根据提供 ...