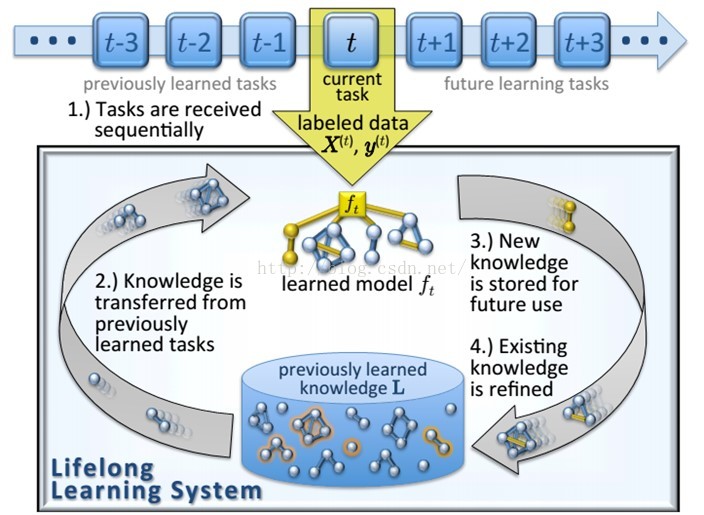
终身机器学习(Lifelong Machine Learning)综述
终身机器学习(Lifelong Machine Learning)综述的更多相关文章
- 我在 B 站学机器学习(Machine Learning)- 吴恩达(Andrew Ng)【中英双语】
我在 B 站学机器学习(Machine Learning)- 吴恩达(Andrew Ng)[中英双语] 视频地址:https://www.bilibili.com/video/av9912938/ t ...
- 机器学习(Machine Learning)
机器学习(Machine Learning)是一门专门研究计算机怎样模拟或实现人类的学习行为,以获取新的知识或技能,重新组织已有的知识结构使之不断改善自身的性能的学科.
- Domain adaptation:连接机器学习(Machine Learning)与迁移学习(Transfer Learning)
domain adaptation(域适配)是一个连接机器学习(machine learning)与迁移学习(transfer learning)的新领域.这一问题的提出在于从原始问题(对应一个 so ...
- K近邻 Python实现 机器学习实战(Machine Learning in Action)
算法原理 K近邻是机器学习中常见的分类方法之间,也是相对最简单的一种分类方法,属于监督学习范畴.其实K近邻并没有显式的学习过程,它的学习过程就是测试过程.K近邻思想很简单:先给你一个训练数据集D,包括 ...
- 学习笔记之机器学习(Machine Learning)
机器学习 - 维基百科,自由的百科全书 https://zh.wikipedia.org/wiki/%E6%9C%BA%E5%99%A8%E5%AD%A6%E4%B9%A0 机器学习是人工智能的一个分 ...
- 学习笔记之机器学习实战 (Machine Learning in Action)
机器学习实战 (豆瓣) https://book.douban.com/subject/24703171/ 机器学习是人工智能研究领域中一个极其重要的研究方向,在现今的大数据时代背景下,捕获数据并从中 ...
- 统计机器学习(statistical machine learning)
组要组成部分:监督学习(supervised learning),非监督学习(unsupervised learning),半监督学习(semi-supervised learning),强化学习(r ...
- 机器学习( Machine Learning)的定义
关于机器学习有两个相关的定义: 1)给计算机赋予没有固定编程的学习能力的研究领域. 2)一种计算机的程序,能从一些任务(T)和性能的度量(P),经验(E)中进行学习.在学习中,任务T的性能P能够随着P ...
- 机器学习(Machine Learning)算法总结-决策树
一.机器学习基本概念总结 分类(classification):目标标记为类别型的数据(离散型数据)回归(regression):目标标记为连续型数据 有监督学习(supervised learnin ...
随机推荐
- P4095 [HEOI2013]Eden 的新背包问题
P4095 [HEOI2013]Eden 的新背包问题 题解 既然假定第 i 个物品不可以选,那么我们就设置两个数组 dpl[][] 正序选前i个物品,dpr[][] 倒序选前i个物品 ,价格不超过 ...
- MySQL 的连接时长控制--interactive_timeout和wait_timeout
在用MySQL客户端对数据库进行操作时,如果一段时间没有操作,再次操作时,常常会报如下错误: ERROR 2013 (HY000): Lost connection to MySQL server d ...
- Python数据分析中 DataFrame axis=0与axis=1的理解
python中的axis究竟是如何定义的呢?他们究竟代表是DataFrame的行还是列? 直接上代码people=DataFrame(np.random.randn(5,5), columns=['a ...
- unix进程通信方式总结(中)(转)
在上一篇博客http://blog.csdn.net/caoyan_12727/article/details/52049417已经总结了<<uinx环境高级编程>>进程通信前 ...
- JSTL优点
1. 在应用程序服务器之间提供了一致的接口,最大程序地提高了WEB应用在各应用服务器之间的移植. 2. 简化了JSP和WEB应用程序的开发.3. 以一种统一的方式减少了JSP中的scriptlet代码 ...
- 【JVM学习笔记】线程上下文类加载器
有许多地方能够看到线程上下文类加载的设置,比如在sun.misc.Launcher类的构造方法中,能够看到如下代码 先写一个例子建立感性认识 public class Test { public st ...
- XmlEncrypt
using System; using System.Collections.Generic; using System.ComponentModel; using System.Data; usin ...
- .net 开源 FTP 组件 edtFTPnet
edtFTPnet官方网站:http://www.enterprisedt.com/products/edtftpnet/ 目前最新版本为2.2.3,下载后在bin目录中找到edtFTPnet.dll ...
- H5 拖拽操作
H5 拖拽操作 前言 在原生H5中,可以通过提供的api实现在网页内元素的拖拽操作.相对于传统的写法更加的简单. 而想要实现拖拽,主要需要进行两个方面的工作,第一是给元素设置draggable='tr ...
- vue等单页面应用优缺点
优点 Vue 的目标是通过尽可能简单的 API 实现响应的数据绑定和组合的视图组件,核心是一个响应的数据绑定系统. 数据驱动 组件化 轻量 简洁 高效 模块友好 页面切换快 缺点 不支持低版本的浏览器 ...