MapReduce --全排序
MapReduce全排序的方法1:
每个map任务对自己的输入数据进行排序,但是无法做到全局排序,需要将数据传递到reduce,然后通过reduce进行一次总的排序,但是这样做的要求是只能有一个reduce任务来完成。
并行程度不高,无法发挥分布式计算的特点。
MapReduce全排序的方法2:
针对方法1的问题,现在介绍方法2来进行改进;
使用多个partition对map的结果进行分区,且分区后的结果是有区间的,将多个分区结果拼接起来,就是一个连续的全局排序文件。
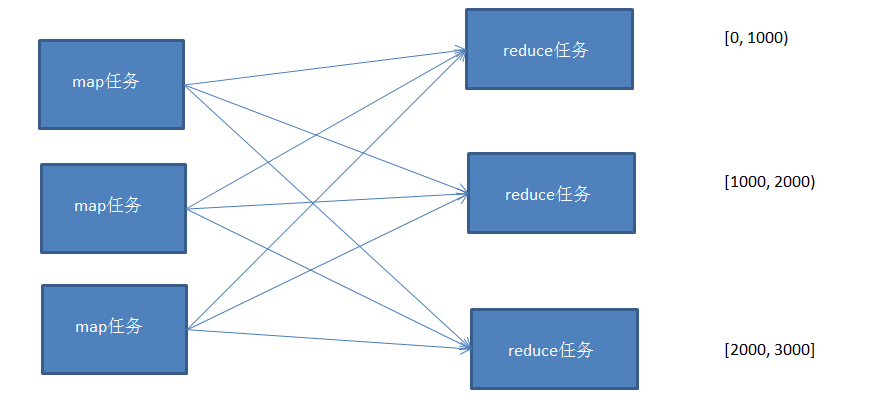
Hadoop自带的Partitioner的实现有两种,一种为HashPartitioner, 默认的分区方式,计算公式 hash(key)%reducernum,另一种为TotalOrderPartitioner, 为排序作业创建分区,分区中数据的范围需要通过分区文件来指定。
分区文件可以人为创建,如采用等距区间,如果数据分布不均匀导致作业完成时间受限于个别reduce任务完成时间的影响。
也可以通过抽样器,先对数据进行抽样,根据数据分布生成分区文件,避免数据倾斜。
这里实现一个通过随机抽样来生成分区文件,然后对数据进行全排序,根据分区文件的范围分配到不同的reducer中。
示例代码:
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.input.KeyValueTextInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import org.apache.hadoop.mapreduce.lib.partition.InputSampler;
import org.apache.hadoop.mapreduce.lib.partition.TotalOrderPartitioner; import java.io.IOException; /**
* Created by Edward on 2016/10/4.
*/
public class TotalSort { public static void main(String[] args) throws IOException, ClassNotFoundException, InterruptedException { //access hdfs's user
System.setProperty("HADOOP_USER_NAME","root"); Configuration conf = new Configuration();
conf.set("mapred.jar", "D:\\MyDemo\\MapReduce\\Sort\\out\\artifacts\\TotalSort\\TotalSort.jar"); FileSystem fs = FileSystem.get(conf); /*RandomSampler 参数说明
* @param freq Probability with which a key will be chosen.
* @param numSamples Total number of samples to obtain from all selected splits.
* @param maxSplitsSampled The maximum number of splits to examine.
*/
InputSampler.RandomSampler<Text, Text> sampler = new InputSampler.RandomSampler<>(0.1, 10, 10); //设置分区文件, TotalOrderPartitioner必须指定分区文件
Path partitionFile = new Path( "_partitions");
TotalOrderPartitioner.setPartitionFile(conf, partitionFile); Job job = Job.getInstance(conf);
job.setJarByClass(TotalSort.class);
job.setInputFormatClass(KeyValueTextInputFormat.class); //数据文件默认以\t分割
job.setMapperClass(Mapper.class);
job.setReducerClass(Reducer.class);
job.setNumReduceTasks(4); //设置reduce任务个数,分区文件以reduce个数为基准,拆分成n段 job.setOutputKeyClass(Text.class);
job.setOutputValueClass(Text.class); job.setPartitionerClass(TotalOrderPartitioner.class); FileInputFormat.addInputPath(job, new Path("/test/sort")); Path path = new Path("/test/wc/output"); if(fs.exists(path))//如果目录存在,则删除目录
{
fs.delete(path,true);
}
FileOutputFormat.setOutputPath(job, path); //将随机抽样数据写入分区文件
InputSampler.writePartitionFile(job, sampler); boolean b = job.waitForCompletion(true);
if(b)
{
System.out.println("OK");
} }
}
测试数据:
1 1
2 1
3 1
4 1
5 1
6 1
7 1
8 1
9 1
10 2
11 2
12 2
13 2
14 2
15 2
16 2
17 2
18 2
19 2
20 2
...
5999 4
6000 4
6001 4
6002 4
6003 4
6004 4
6005 4
6006 4
6007 4
6008 4
6009 4
6010 4
抽样生成的分区文件为:
# hadoop fs -text /user/root/_partitions
2673 (null)
4441 (null)
5546 (null)
生成的抽样文件为sequence file通过 -text打开查看
生成的排序结果文件:

文件内容:
hadoop fs -cat /test/wc/output/part-r-00000
...
hadoop fs -cat /test/wc/output/part-r-00001
...
hadoop fs -cat /test/wc/output/part-r-00002
...
554
hadoop fs -cat /test/wc/output/part-r-00003
...
99
MapReduce --全排序的更多相关文章
- Hadoop学习笔记: 全排序
在Hadoop中实现全排序有如下三种方法: 1. 只使用一个reducer 2. 自定义partitioner 3. 使用TotalOrderPartitioner 其中第一种方法显然违背了mapre ...
- hive中的全排序
写mapreduce程序时,如果reduce个数>1,想要实现全排序需要控制好map的输出 现在学了Hive,写sql大家都很熟悉,如果一个order by解决了全排序还用那么麻烦写mapred ...
- Hadoop的partitioner、全排序
按数值排序 示例:按气温字段对天气数据集排序问题:不能将气温视为Text对象并以字典顺序排序正统做法:用顺序文件存储数据,其IntWritable键代表气温,其Text值就是数据行常用简单做法:首先, ...
- Hadoop 学习笔记 (十) MapReduce实现排序 全局变量
一些疑问:1 全排序的话,最后的应该sortJob.setNumReduceTasks(1);2 如果多个reduce task都去修改 一个静态的 IntWritable ,IntWritable会 ...
- Hadoop基础-MapReduce的排序
Hadoop基础-MapReduce的排序 作者:尹正杰 版权声明:原创作品,谢绝转载!否则将追究法律责任. 一.MapReduce的排序分类 1>.部分排序 部分排序是对单个分区进行排序,举个 ...
- 大数据系列之分布式计算批处理引擎MapReduce实践-排序
清明刚过,该来学习点新的知识点了. 上次说到关于MapReduce对于文本中词频的统计使用WordCount.如果还有同学不熟悉的可以参考博文大数据系列之分布式计算批处理引擎MapReduce实践. ...
- [大数据相关] Hive中的全排序:order by,sort by, distribute by
写mapreduce程序时,如果reduce个数>1,想要实现全排序需要控制好map的输出,详见Hadoop简单实现全排序. 现在学了hive,写sql大家都很熟悉,如果一个order by解决 ...
- hadoop笔记之MapReduce的应用案例(利用MapReduce进行排序)
MapReduce的应用案例(利用MapReduce进行排序) MapReduce的应用案例(利用MapReduce进行排序) 思路: Reduce之后直接进行结果合并 具体样例: 程序名:Sort. ...
- hadoop排序 -- 全排序
目录 一.关于Reducer全排序 1.1. 什么叫全排序 1.2. 分区的标准是什么 二.全排序的三种方式 2.1. 一个Reducer 2.2. 自定义分区函数 2.3. 采样 一.关于Reduc ...
随机推荐
- 如何让AutoCAD自动加载Arx,比如ArxDbg.arx
1.在AutoCAD的安装根目录下,用记事本创建一个acad.rx文件,如下 ------acad.rx----- ArxDbg.arx -------------------- 2.将ArxDbg. ...
- Django中csrf错误
CSRF(Cross-site request forgery)跨站请求伪造,也被称为“one click attack”或者session riding,通常缩写为CSRF或者XSRF,是一种对网站 ...
- CentOS 6.5 安装 Python3
1.安装环境 yum -y install gcc zlib-devel make 2.下载python版本 wget http://www.python.org/ftp/python/3.5.1/P ...
- ruby md5加签验签方法
# md5签名def md5_sign(data,key) return OpenSSL::Digest::MD5.hexdigest(data+key)end # md5验签def md5_veri ...
- AttributeTargets 枚举
AttributeUsage AttributeTargets 在C#的类中,有的类加上了[AttributeUsage(AttributeTargets.Property)]这个是起什么作用的呢?A ...
- vim(5)vim下wimrc的配置,解决中文乱码问题
解决linux下vim乱码的情况:(修改vimrc的内容) 全局的情况下:即所有用户都能用这个配置 文件地址:/etc/vimrc 在文件中添加: ,ucs-bom,gb18030,gbk,gb231 ...
- php操作文件及下载图片脚本
<?php set_time_limit(0); $handle = fopen('article.txt','r'); for($i=0;$i<1;$i++) { $count = 0; ...
- Android广播机制简介
为什么说Android中的广播机制更加灵活呢?这是因为Android中的每个应用程序都可以对自己感兴趣的广播进行注册,这样该程序就只会接收到自己所关心的广播内容,这些广播可能是来自于系统的,也可能是来 ...
- [HTML] CSS Id 和 Class选择器
id 和 class 选择器 如果你要在HTML元素中设置CSS样式,你需要在元素中设置"id" 和 "class"选择器. id 选择器 id 选择器可以为标 ...
- 整理: Android HAL
这篇文章整理来自http://bbs.chinaunix.net/thread-3675980-1-1.html 在论坛中看到的Android HAL讨论,有个ID描述的比较清楚,摘录如下: temp ...