爬虫之Xpath案例
案例:使用XPath的爬虫
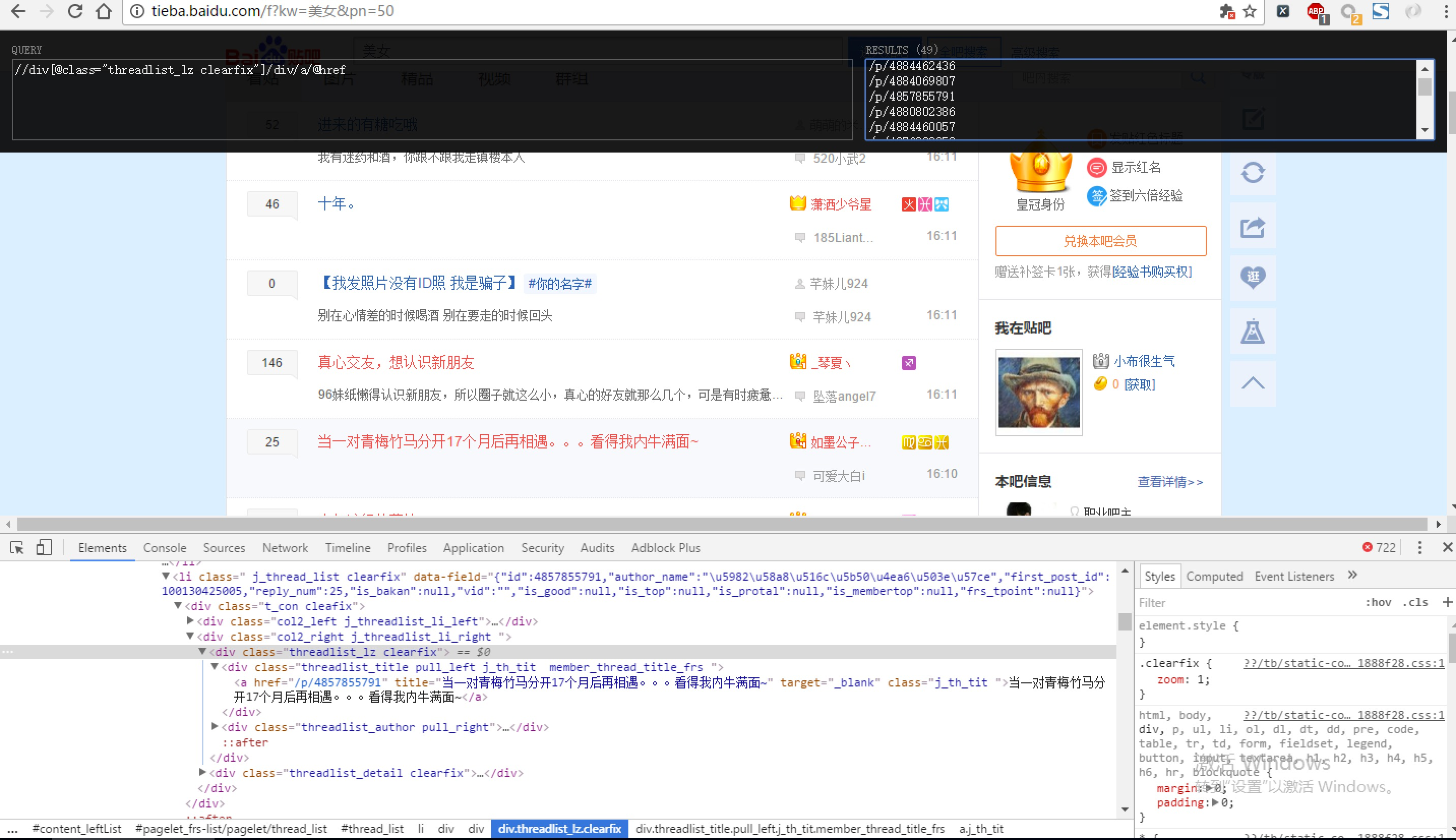
现在我们用XPath来做一个简单的爬虫,我们尝试爬取某个贴吧里的所有帖子,并且将该这个帖子里每个楼层发布的图片下载到本地。
# tieba_xpath.py
#!/usr/bin/env python
# -*- coding:utf-8 -*-
import os
import urllib
import urllib2
from lxml import etree
class Spider:
def __init__(self):
self.tiebaName = raw_input("请需要访问的贴吧:")
self.beginPage = int(raw_input("请输入起始页:"))
self.endPage = int(raw_input("请输入终止页:"))
self.url = 'http://tieba.baidu.com/f'
self.ua_header = {"User-Agent" : "Mozilla/5.0 (compatible; MSIE 9.0; Windows NT 6.1 Trident/5.0;"}
# 图片编号
self.userName = 1
def tiebaSpider(self):
for page in range(self.beginPage, self.endPage + 1):
pn = (page - 1) * 50 # page number
word = {'pn' : pn, 'kw': self.tiebaName}
word = urllib.urlencode(word) #转换成url编码格式(字符串)
myUrl = self.url + "?" + word
# 示例:http://tieba.baidu.com/f? kw=%E7%BE%8E%E5%A5%B3 & pn=50
# 调用 页面处理函数 load_Page
# 并且获取页面所有帖子链接,
links = self.loadPage(myUrl) # urllib2_test3.py
# 读取页面内容
def loadPage(self, url):
req = urllib2.Request(url, headers = self.ua_header)
html = urllib2.urlopen(req).read()
# 解析html 为 HTML 文档
selector=etree.HTML(html)
#抓取当前页面的所有帖子的url的后半部分,也就是帖子编号
# http://tieba.baidu.com/p/4884069807里的 “p/4884069807”
links = selector.xpath('//div[@class="threadlist_lz clearfix"]/div/a/@href')
# links 类型为 etreeElementString 列表
# 遍历列表,并且合并成一个帖子地址,调用 图片处理函数 loadImage
for link in links:
link = "http://tieba.baidu.com" + link
self.loadImages(link)
# 获取图片
def loadImages(self, link):
req = urllib2.Request(link, headers = self.ua_header)
html = urllib2.urlopen(req).read()
selector = etree.HTML(html)
# 获取这个帖子里所有图片的src路径
imagesLinks = selector.xpath('//img[@class="BDE_Image"]/@src')
# 依次取出图片路径,下载保存
for imagesLink in imagesLinks:
self.writeImages(imagesLink)
# 保存页面内容
def writeImages(self, imagesLink):
'''
将 images 里的二进制内容存入到 userNname 文件中
'''
print imagesLink
print "正在存储文件 %d ..." % self.userName
# 1. 打开文件,返回一个文件对象
file = open('./images/' + str(self.userName) + '.png', 'wb')
# 2. 获取图片里的内容
images = urllib2.urlopen(imagesLink).read()
# 3. 调用文件对象write() 方法,将page_html的内容写入到文件里
file.write(images)
# 4. 最后关闭文件
file.close()
# 计数器自增1
self.userName += 1
# 模拟 main 函数
if __name__ == "__main__":
# 首先创建爬虫对象
mySpider = Spider()
# 调用爬虫对象的方法,开始工作
mySpider.tiebaSpider()
爬虫之Xpath案例的更多相关文章
- Python爬虫之xpath语法及案例使用
Python爬虫之xpath语法及案例使用 ---- 钢铁侠的知识库 2022.08.15 我们在写Python爬虫时,经常需要对网页提取信息,如果用传统正则表达去写会增加很多工作量,此时需要一种对数 ...
- 爬虫常用Xpath和CSS3选择器对比
爬虫常用Xpath和CSS3选择器对比 1. 简介 CSS是来配合HTML工作的,和Xpath对比起来,CSS选择器通常都比较短小,但是功能不够强大.CSS中的空白符' '和Xpath的'//'都表示 ...
- 中国爬虫违法违规案例汇总github项目介绍
中国爬虫违法违规案例汇总github项目介绍 GitHub - 本项目用来整理所有中国大陆爬虫开发者涉诉与违规相关的新闻.资料与法律法规.致力于帮助在中国大陆工作的爬虫行业从业者了解我国相关法律,避免 ...
- python爬虫:XPath语法和使用示例
python爬虫:XPath语法和使用示例 XPath(XML Path Language)是一门在XML文档中查找信息的语言,可以用来在XML文档中对元素和属性进行遍历. 选取节点 XPath使用路 ...
- 非常全的一份Python爬虫的Xpath博文
非常全的一份Python爬虫的Xpath博文 Xpath 是 python 爬虫过程中非常重要的一个用来定位的一种语法. 一.开始使用 首先我们需要得到一个 HTML 源代码,用来模拟爬取网页中的源代 ...
- Python爬虫(十三)_案例:使用XPath的爬虫
本篇是使用XPath的案例,更多内容请参考:Python学习指南 案例:使用XPath的爬虫 现在我们用XPath来做一个简单的爬虫,我们尝试爬取某个贴吧里的所有帖子且将该帖子里每个楼层发布的图片下载 ...
- 爬虫神器xpath的用法(三)
xpath的多线程爬虫 #encoding=utf-8 ''' pool = Pool(4) cpu的核数为4核 results = pool.map(爬取函数,网址列表) ''' from mult ...
- 爬虫神器XPath,程序员带你免费获取周星驰等明星热门电影
本教程由"做全栈攻城狮"原创首发,本人大学生一枚平时还需要上课,但尽量每日更新文章教程.一方面把我所习得的知识分享出来,希望能对初学者有所帮助.另一方面总结自己所学,以备以后查看. ...
- 互联网金融爬虫怎么写-第一课 p2p网贷爬虫(XPath入门)
版权声明:本文为博主原创文章,未经博主允许不得转载. 相关教程: 手把手教你写电商爬虫-第一课 找个软柿子捏捏 手把手教你写电商爬虫-第二课 实战尚妆网分页商品采集爬虫 手把手教你写电商爬虫-第三课 ...
随机推荐
- [iOS微博项目 - 4.3] - 设置每条微博边框样式
github: https://github.com/hellovoidworld/HVWWeibo A.设置每条微博边框样式 1.需求 不需要分割线 每个微博之间留有一定的间隙 2.思路 直接设 ...
- 伪造堆块绕过unlink检查(ctf-QiangWangCup-2015-shellman)
目录 堆溢出点 伪造空闲堆块 释放时重写指向伪造堆块的指针 如何利用 参考资料 堆溢出点 图1 堆溢出点 在edit函数中,没有对输入的长度和原来的长度做判断. 伪造空闲堆块 正常 ...
- Storm-源码分析- Disruptor在storm中的使用
Disruptor 2.0, (http://ifeve.com/disruptor-2-change/) Disruptor为了更便于使用, 在2.0做了比较大的调整, 比较突出的是更换了几乎所有的 ...
- What’s wrong with virtual methods called through an interface
May 31, 2016 Calling a virtual method through an interface always was a lot slower than calling a st ...
- Android集成百度地图SDK
本Demo中所含功能 1:定位,显示当前位置 2:地图多覆盖物(地图描点.弹出该点的具体信息) 3:坐标地址互相换算 4:POI兴趣点检索 5:线路查询(步行,驾车,公交) 6:绘制线路(OpenGL ...
- Python-读入json文件并进行解析及json基本操作
import json def resolveJson(path): file = open(path, "rb") fileJson = json.load(file) fi ...
- (转)extern关键字两种场景的使用
第一种场景 -- extern extern关键字的作用是声明变量和函数为外部链接,即该变量或函数名在其它文件中可见.用其声明的变量或函数应该在别的文件或同一文件的其它地方定义. 例如语句:exter ...
- dubbo-admin 部署
上一章主要是谈到zookeeper的安装和部署 因为zookeeper只是一个黑框,我们无法看到是否存在了什么提供者或消费者,这时就要借助Dubbo-Admin管理平台来实时的查看,也可以通过这个平台 ...
- Lua 可控下标数组遍历
, , , , , , , , , , , } , , } local j = 1 while i <= #aaa do if bbb[j] == aaa[i] then -- 如果 b下标元素 ...
- shell 脚本中双引号 单引号 反引号 的区别
转自:http://blog.csdn.net/iamlaosong/article/details/54728393 最近要编个shell脚本处理数据,需要检测数据文件是否存在,文件名中包含日期,所 ...