Python第一个爬虫学习
在网上查看大神的关于Python爬虫的文章,代码如下:
#coding=utf-8
import urllib
import re def getHtml(url):
page = urllib.urlopen(url)
html = page.read()
return html def getImg(html):
reg = r'src="(.+?\.jpg)" pic_ext'
imgre = re.compile(reg)
imglist = re.findall(imgre,html)
x = 0
for imgurl in imglist:
urllib.urlretrieve(imgurl,'%s.jpg' % x)
x+=1 html = getHtml("http://tieba.baidu.com/p/2460150866")
print getImg(html)
以下则是在运行上述代码过程中遇到的相关问题,以及解决方式,虽然不怎么高级,但是也算是一种学习思路吧。
问题1:在Python3.2的环境下,未运行时,代码会报错:
解决1:将
print getImg(html)
修改为
print (getImg(html))
问题2:代码执行后,报如下错误:
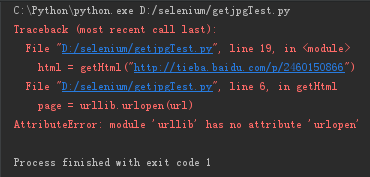
解决2:度娘进行搜索,才发现3.2不兼容2.0的,于是进入官方文档查找最新的调用方式,对这三行进行以下修改,修改前:
import urllib
page = urllib.urlopen(url)
urllib.urlretrieve(imgurl,'%s.jpg' % x)
修改后:
import urllib.request
page = urllib.request.urlopen(url)
urllib.request.urlretrieve(imgurl,'%s.jpg' % x)
问题3:运行代码,提示以下错误:
C:\Python\python.exe D:/selenium/getjpgTest.py
Traceback (most recent call last):
File "D:/selenium/getjpgTest.py", line 20, in <module>
print (getImg(html))
File "D:/selenium/getjpgTest.py", line 13, in getImg
imglist = re.findall(imgre,html)
File "C:\Python\lib\re.py", line 213, in findall
return _compile(pattern, flags).findall(string)
TypeError: cannot use a string pattern on a bytes-like object
Process finished with exit code 1
解决3:百度之后,很容易得到答案,加上下面一句代码即可解决:
html=html.decode('utf-8')
最终得到以下代码:
#coding=utf-8
import urllib.request
import re def getHtml(url):
page = urllib.request.urlopen(url)
html = page.read()
return html def getImg(html):
reg = r'src="(.+?\.jpg)" pic_ext'
imgre = re.compile(reg)
html = html.decode('utf-8')
imglist = re.findall(imgre,html)
x = 0
for imgurl in imglist:
urllib.request.urlretrieve(imgurl,'%s.jpg' % x)
x+=1 html = getHtml("http://tieba.baidu.com/p/2460150866")
print (getImg(html))
执行结果如下:
参考文章:1、http://www.cnblogs.com/fnng/p/3576154.html
2、http://blog.csdn.net/lxh199603/article/details/53192883
Python第一个爬虫学习的更多相关文章
- Python 简单网页爬虫学习
#coding=utf-8 # 参考文章: # 1. python实现简单爬虫功能 # http://www.cnblogs.com/fnng/p/3576154.html # 2. Python 2 ...
- python第一个爬虫的例子抓取数据到mysql,实测有数据
python3.5 先安装库或者扩展 1 requests第三方扩展库 pip3 install requests 2 pymysql pip3 install pymysql 3 lxml pip3 ...
- Python爬虫学习第一记 (翻译小助手)
1 # Python爬虫学习第一记 8.24 (代码有点小,请放大看吧) 2 3 #实现有道翻译,模块一: $fanyi.py 4 5 import urllib.request 6 import u ...
- python爬虫学习(1) —— 从urllib说起
0. 前言 如果你从来没有接触过爬虫,刚开始的时候可能会有些许吃力 因为我不会从头到尾把所有知识点都说一遍,很多文章主要是记录我自己写的一些爬虫 所以建议先学习一下cuiqingcai大神的 Pyth ...
- Python项目之我的第一个爬虫----爬取豆瓣图书网,统计图书数量
今天,花了一个晚上的时间边学边做,搞出了我的第一个爬虫.学习Python有两个月了,期间断断续续,但是始终放弃,今天搞了一个小项目,有种丰收的喜悦.废话不说了,直接附上我的全部代码. # -*- co ...
- python爬虫__第一个爬虫程序
前言 机缘巧合,最近在学习机器学习实战, 本来要用python来做实验和开发环境 得到一个需求,要爬取大众点评中的一些商户信息, 于是开启了我的第一个爬虫的编写,里面有好多心酸,主要是第一次. 我的文 ...
- Python爬虫学习:三、爬虫的基本操作流程
本文是博主原创随笔,转载时请注明出处Maple2cat|Python爬虫学习:三.爬虫的基本操作与流程 一般我们使用Python爬虫都是希望实现一套完整的功能,如下: 1.爬虫目标数据.信息: 2.将 ...
- Python爬虫学习:二、爬虫的初步尝试
我使用的编辑器是IDLE,版本为Python2.7.11,Windows平台. 本文是博主原创随笔,转载时请注明出处Maple2cat|Python爬虫学习:二.爬虫的初步尝试 1.尝试抓取指定网页 ...
- python网络爬虫学习笔记
python网络爬虫学习笔记 By 钟桓 9月 4 2014 更新日期:9月 4 2014 文章文件夹 1. 介绍: 2. 从简单语句中開始: 3. 传送数据给server 4. HTTP头-描写叙述 ...
随机推荐
- php if语句判定my查询是否为空
<?php header("Content-type: text/html; charset=utf-8"); $username=$_GET['username']; $p ...
- 什么是Mybatis
MyBatis 本是apache的一个开源项目iBatis, 2010年这个项目由apache software foundation 迁移到了google code,并且改名为MyBatis .iB ...
- 用 free 或 delete 释放了内存之后,立即将指针设置为 NULL,防止产 生“野指针”
用 free 或 delete 释放了内存之后,立即将指针设置为 NULL,防止产 生“野指针”. #include <iostream> using namespace std; /* ...
- 多媒体开发之rtp 打包发流--- 从h264中获取分辨率
http://blog.csdn.net/DiegoTJ/article/details/5541877 http://www.cnblogs.com/lidabo/p/4482684.html 分辨 ...
- 嵌入式开发之davinci--- 8148/8168/8127 中的图像处理算法优化库vlib
The Texas Instruments VLIB is an optimizedImage/Video Processing Functions Library for C programmers ...
- MFC通过button控制编辑框是否显示系统时间(动态显示)
1.在dlg.h中public bool flag; static UINT time(void *param); 2.在构造函数中 flag=false; 3.在button的生成函数中 if(fl ...
- Python 资料性网站。
伯乐在线:http://blog.jobbole.com/category/python/ http://blog.chinaunix.net/uid/22334392/cid-24327-list- ...
- hdu 1026:Ignatius and the Princess I(优先队列 + bfs广搜。ps:广搜AC,深搜超时,求助攻!)
Ignatius and the Princess I Time Limit: 2000/1000 MS (Java/Others) Memory Limit: 65536/32768 K (J ...
- MongoDB基本用法
MongoDB基本用法(增删改高级查询.mapreduce) 分享一下我经常用到的自己写的mongo用法示例 该示例基于当前最新的mongo驱动,版本为mongo-2.10.1.jar,用junit写 ...
- Eclipse & Visual Studio
VS中的解决方案 vs Eclipse中的workspace Maven包管理 vs Nuget类库管理 build path vs