Lucene.Net 2.3.1开发介绍 —— 三、索引(二)
原文:Lucene.Net 2.3.1开发介绍 —— 三、索引(二)
2、索引中用到的核心类
在Lucene.Net索引开发中,用到的类不多,这些类是索引过程的核心类。其中Analyzer是索引建立的基础,Directory是索引建立中或者建立好存储的介质,Document和Field类是逻辑结构的核心,IndexWriter是操作的核心。其他类的使用都被隐藏掉了,这也是为什么Lucene.Net使用这么方便的原因。
2.1 Analyzer
前面已经对Analyzer进行了很详细的讲解,Analyzer将会把一段文本分析称一个个Token。这些Token如何被IndexWriter使用,这里牵涉到一个很重要的类,那就是DocumentsWriter。这个类非常关键,可以说是索引部分最核心的类,IndexWriter只是它的一个包装。这里主要介绍应用,所以就不做太详细的介绍。Token在DocumentsWriter类中,通过DocumentsWriter的最重要的方法——InvertField——推送到了Field中。这样就完成了分词添加到逻辑结构的过程。
2.2 Directory
严格来说,Directory并不专属于索引,它代表的是Lucene.Net的存储介质,它表示了索引具体存放到什么地方。在前面的两个示例中似乎没有使用到它,那是因为你传入的路径,会自动转换成Directory。Directory有两个子类,分别是RAMDirectory——代表索引存放到内存中,和FSDirectory——代表索引存放到硬盘。在使用FSDirectory存放到硬盘的过程中,还是会调用RAMDirectory。IndexWriter会把建立的索引先放到RAMDirectory,然后到一定的条件,才将这些数据写入硬盘。
2.3 IndexWriter
IndexWriter是索引中负责操作的核心,它负责把索引文件写入存储介质,是控制逻辑存储转换为物理存储的纽带。
IndexWriter共有10个可以使用的构造函数,但是他们的参数类型比较少。一共有以下几种:
(1)、Directory d;
(2)、Analyzer a;
(3)、bool create;
(4)、FileInfo path;
(5)、string path;
(6)、bool autoCommit;
(7)、IndexDeletionPolicy deletionPolicy;
其中6,7不常用。而FileInfo path和string path最终都会构造成Directory,又因为这两种路径都是磁盘的路径,所以构造出来的Directory一定是FSDrectory。bool create表示是否是创建,否则是增量更新,默认状态是false。bool autoCommit不常用,是用来指定是否当索引在close状态下才更新的,如果是false,则需要在close状态下更新。IndexDeletionPolicy deletionPolicy则是指定是否对以前的更新进行移除,它能表示为两个值,KeepOnlyLastCommitDeletionPolicy和SnapshotDeletionPolicy,默认状态下是,KeepOnlyLastCommitDeletionPolicy。
2.4 Document
Document就是一条虚拟记录,可以理解为数据里的一行。正是有了它,才使我们可以很方便并且易于理解地操作索引文件。它一般记录了需要用到的一个文档的属性,当然,这需要和Field联合使用。
2.5 Field
Field类就是数据库里的一列。一个文档有标题,内容,作者,创建时间这四个属性的话,那么就需要四个Field保存这些属性,然后把四个Field加入到Document中,就有了一行记录。在查询的时候,无论查那个列,总能得到一整行记录,是不是和数据库很相似?
Field本身具有一些属性,就和数据库里的列一样。它的属性通过它的三个内嵌类设置,其实这个地方完全可以用枚举,但是很遗憾的是Java里面没有枚举,所以移植过来也没有转换为枚举。
Field的构造函数也比较多,有7个之多。其中Store,Index和TermVector是通过内部类指定的。
(1)、Store 有三个选项,Field.Store.COMPRESS表示被压缩存储;Field.Store.YES表示储存;Field.Store.NO表示不被存储。
(2)、Index的选项有四个,Field.Index.NO表示不建立索引;Field.Index.TOKENIZED表示分词后索引;Index.NO_NORMS表示值存储内容;Field.Index.UN_TOKENIZED表示不分词索引。
(3)、TermVector这个参数也不常用,它有五个选项。Field.TermVector.NO表示不索引Token的位置属性;Field.TermVector.WITH_OFFSETS表示额外索引Token的结束点;Field.TermVector.WITH_POSITIONS表示额外索引Token的当前位置;Field.TermVector.WITH_POSITIONS_OFFSETS表示额外索引Token的当前和结束位置;Field.TermVector.YES则表示存储向量。
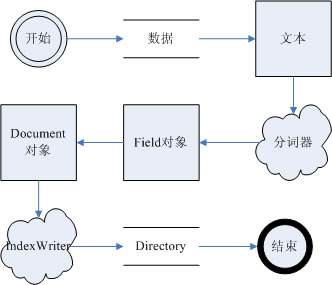
2.6 索引核心类工作流程
图 2.6.1
如图2.6.1表示了数据在Lucene.Net索引过程处理的整个流程。注意,这个流程图中,分词器并不直接产生Field对象,在实例中Analyzer是被赋予IndexWriter实例的,等等执行添加文档操作的时候,IndexWriter才会真正地调用分词器生成Field需要的数据(在DocumentWriter类中)。上图只是反映了数据是如何流动的,并不是真实的调用过程。
Lucene.Net 2.3.1开发介绍 —— 三、索引(二)的更多相关文章
- Lucene.Net 2.3.1开发介绍 —— 三、索引(七)
原文:Lucene.Net 2.3.1开发介绍 -- 三.索引(七) 5.IndexWriter 索引这部分最后讲的是IndexWriter.如果说前面提到的都是数据的结构,那么IndexWriter ...
- Lucene.Net 2.3.1开发介绍 —— 三、索引(六)
原文:Lucene.Net 2.3.1开发介绍 -- 三.索引(六) 2.2 Field的Boost 如果说Document的Boost是一条线,那么Field的Boost则是一个点.怎么理解这个点呢 ...
- Lucene.Net 2.3.1开发介绍 —— 三、索引(五)
原文:Lucene.Net 2.3.1开发介绍 -- 三.索引(五) 话接上篇,继续来说权重对排序的影响.从上面的4个测试,只能说是有个直观的理解了.“哦,是!调整权重是能影响排序了,但是好像没办法来 ...
- Lucene.Net 2.3.1开发介绍 —— 三、索引(四)
原文:Lucene.Net 2.3.1开发介绍 -- 三.索引(四) 4.索引对搜索排序的影响 搜索的时候,同一个搜索关键字和同一份索引,决定了一个结果,不但决定了结果的集合,也确定了结果的顺序.那个 ...
- Lucene.Net 2.3.1开发介绍 —— 三、索引(三)
原文:Lucene.Net 2.3.1开发介绍 -- 三.索引(三) 3.Field配置所产生的效果 索引数据,简单的代码,只要两个方法就搞定了,而在索引过程中用到的一些类里最简单,作用也不小的就是F ...
- Lucene.Net 2.3.1开发介绍 —— 三、索引(一)
原文:Lucene.Net 2.3.1开发介绍 -- 三.索引(一) 在说索引之前,先说说索引是什么?为什么要索引?怎么索引? 先想想看,假如现在有一个文本,我们会怎么去搜索.比如,有一个string ...
- Lucene.Net 2.3.1开发介绍 —— 四、搜索(三)
原文:Lucene.Net 2.3.1开发介绍 -- 四.搜索(三) Lucene有表达式就有运算符,而运算符使用起来确实很方便,但另外一个问题来了. 代码 4.3.4.1 Analyzer anal ...
- Lucene.Net 2.3.1开发介绍 —— 二、分词(三)
原文:Lucene.Net 2.3.1开发介绍 -- 二.分词(三) 1.3 分词器结构 1.3.1 分词器整体结构 从1.2节的分析,终于做到了管中窥豹,现在在Lucene.Net项目中添加一个类关 ...
- Lucene.Net 2.3.1开发介绍 —— 四、搜索(一)
原文:Lucene.Net 2.3.1开发介绍 -- 四.搜索(一) 既然是内容筛选,或者说是搜索引擎,有索引,必然要有搜索.搜索虽然与索引有关,那也只是与索引后的文件有关,和索引的程序是无关的,因此 ...
随机推荐
- Java中的位运算符、移位运算
一.位运算 Java中有4个位运算,它们的运算规则如下: (1)按位与 (&) :两位全为1,结果为1,否则为0: (2)按位或 (|) :两位有一个为1,结果为1,否则为0: (3) ...
- WCF技术剖析之二十七: 如何将一个服务发布成WSDL[基于WS-MEX的实现](提供模拟程序)
原文:WCF技术剖析之二十七: 如何将一个服务发布成WSDL[基于WS-MEX的实现](提供模拟程序) 通过<如何将一个服务发布成WSDL[编程篇]>的介绍我们知道了如何可以通过编程或者配 ...
- Web网页中内嵌Activex的Activex插件开发 .
转载自: http://blog.csdn.net/tttyd/article/details/5258096 源代码下载 http://files.cnblogs.com/tttyd/Activex ...
- Route@简单应用
路由的简单应用(生成URL) 这篇文章讲的核心问题是利用路由系统生成URL但是我们,但是我们不是仅仅生成URL,我们的超链接的href属性中,我们在跳转的时候,都需要URL,我们要将的就是在这些实际情 ...
- C#面向对象1 类 以及 类的继承(new、ovverride)
类 的典型代码============================== 包括 属性及其判断赋值 方法 构造函数及其重载 ) { ...
- asp.net导出Excel类库
using System; using System.Collections.Generic; using System.Reflection; using System.Web; using Exc ...
- DELPHI语法基础学习笔记-Windows 句柄、回调函数、函数重载等(Delphi中很少需要直接使用句柄,因为句柄藏在窗体、 位图及其他Delphi 对象的内部)
函数重载重载的思想很简单:编译器允许你用同一名字定义多个函数或过程,只要它们所带的参数不同.实际上,编译器是通过检测参数来确定需要调用的例程.下面是从VCL 的数学单元(Math Unit)中摘录的一 ...
- 如何捕获Wince下form程序的全局异常
前言 上两篇文章我们总结了在winform程序下如何捕获全局的异常.那么同样的问题,在wince下我们如何来处理呢?用相同的代码来处理可以吗? 答案是否定的,上面的方案1完全不能解决wince下的情况 ...
- boost中asio网络库多线程并发处理实现,以及asio在多线程模型中线程的调度情况和线程安全。
1.实现多线程方法: 其实就是多个线程同时调用io_service::run for (int i = 0; i != m_nThreads; ++i) { boo ...
- 高焕堂《android从程序员到架构师之路》 YY讲坛直面大师学习架构设计
<android从程序员到架构师之路>YY讲坛活动: sundy携手高焕堂老师全程YY答疑 与大师一起,分享android技术 时间:7月21日下午2:00 报名联系QQ:22243 ...