Lucene.Net 2.3.1开发介绍 —— 二、分词(三)
原文:Lucene.Net 2.3.1开发介绍 —— 二、分词(三)
1.3 分词器结构
1.3.1 分词器整体结构
从1.2节的分析,终于做到了管中窥豹,现在在Lucene.Net项目中添加一个类关系图,把TokenStream和他的儿孙们统统拉上去,就能比较好的把握他们之间的关系。
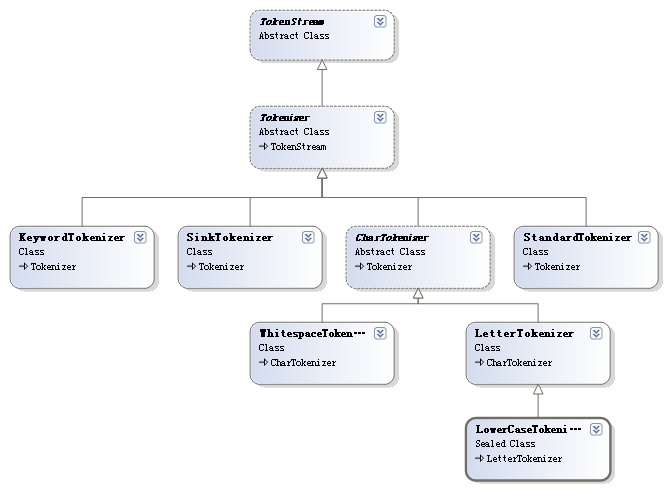
图 1.3.1.1
如图1.3.1.1 就是他们的类关系图。看出如果要做一个分词器,最短的路,就是继承第二代,成为第三代。然后再写一个Analyzer的子类,专门用来做新分词器的适配器就好了。转换器。 呵呵,写Analyzer的过程,就是实践适配器模式的过程。(这里是直接使用了Tokenizer的实例,不能算是适配器模式,更正,感谢老赵指正。 2008年9月1日 2:23:23)
1.3.2 分词器调用流程
光有整体结构还不行,还有了解方法和方法是如何被调用的。还是以最简单的KeywordTokenizer来作为分析对象。
入口毫无疑问,就是KeywordTokenizer的构造函数。然后就是调用Next方法,这是再简单不过的事情。而这里就是要让每次调用Next方法都可以出来一个分词。这个过程可以这么来描述:
(1)、分词,把一句话,一段话或者一篇文章按一个规则划分为N份;
(2)、把这N份片断存储到一个数组中,要同时记录这个片断的内容,还要记录它相对开始位置的偏移;

(3)、每次调用Next方法,就从上面的数组中取出一个片段;
(4)、片段取完就返回null值;
(5)、发现null值,分词过程结束。
明白以上流程,就可以开始自己写分词器了,嘿嘿。
2.1 自己动手写分词
自己写分词,光知道上面的还不够。自己写分词,首先,你要有个目标,目标是干嘛的呢?就是你这个分词到底是给什么用的,要做到什么程度。比方说,分词是给英文的还是中文的,还是中英文混合,还是还包含了日文。英文的写作规则,单词一空格划分,比较好区分,但是中文的怎么办?归结起来,现在将面临三个问题:
(1)、分词器要分什么东西,怎么才能达到目的,其实就是字符串怎么截取的问题;
(2)、分词器的准确度如何,分词速度如何,怎么做取舍,这是个算法的问题;
(3)、剩下的问题才是如何用Lucene.Net可以理解的方式写出来,这一步,上面讲了那么多小节,却是三个问题的最简单的一个。
2.1.1 最简单的分词方式
这里的最简单指的是用最少代码的方式。好,现在来个最简单的,写成代码2.1.1.1的方式总是最简单了吧?
代码 2.1.1.1
using System;using Lucene.Net.Analysis;namespace Test.Analysis{ public class
EsayTokenizer : Tokenizer { }}
太好了,终于写出来了,下面包装一下,写个Analyzer类。
代码 2.1.1.2
using Lucene.Net.Analysis;namespace Test.Analysis{ public class EsayAnalyzer : Analyzer { public override TokenStream TokenStream(string fieldName, System.IO.TextReader reader) { return new
EsayTokenizer(); } }}
立刻测试一下(测试方法见1.1.1节,具体测试则加入1.1.2节的AllAnalysisTest中,测试代码见 2.1.1.3)。
测试结果:
NUnit的gui崩溃了!!!
这个代码实在太强大了,让测试工具崩溃了!这个问题在1.2.1节讲过,Next方法和Next(Token)方法,在父类中是相互调用的,那会产生什么后果?这就像是个死循环,这个递归永远没办法结束,所以到一定次数以后,会堆栈溢出。所以我们写的分词器必须自己实现一个Next方法,哪怕什么都不做。而另外一个问题就是EsayAnalyzer类总是能拿到一个流,但是现在没办法传到分词器里来,所以,分词器必须有个能传入流的构造函数。对代码修正,如代码2.1.1.3。
代码 2.1.1.3
Code 1using System; 2using System.Collections.Generic; 3using System.Text; 4using Lucene.Net.Analysis; 5using System.IO; 6 7namespace Test.Analysis 8{ 9 public class EsayTokenizer : Tokenizer10 {11 private TextReader reader;1213 public EsayTokenizer(TextReader reader)14 {15 this.reader = reader;16 }1718 public override Token Next()19 {20 //千万不能调用父类的方法,要不又是死递归21 //return base.Next();22 return null;23 }24 }25}
同时把EsayAnalyzer 类对EsayTokenizer类的调用改成return new EsayTokenizer(reader)。OK,测试结果:
Test.Analysis.EsayAnalyzer结果:
--------------------------------
--------------------------------
什么也没有,这个在预料之中。和KeywordTokenizer分词器不同,KeywordTokenizer分词器是什么都有,而且没做任何处理。现在呢是什么都没了。还有一种写法是和这种不相上下的。如代码2.1.1.4。
代码 2.1.14
Code 1using Lucene.Net.Analysis; 2 3namespace Test.Analysis 4{ 5 public class EsayTooAnalyzer : Analyzer 6 { 7 public override TokenStream TokenStream(string fieldName, System.IO.TextReader reader) 8 { 9 return new EsayTooTokenizer(reader);10 }11 }12}1314using System.IO;15using Lucene.Net.Analysis;1617namespace Test.Analysis18{19 public class EsayTooTokenizer : CharTokenizer20 {21 public EsayTooTokenizer(TextReader reader)22 : base(reader)23 {24 }2526 protected override bool IsTokenChar(char c)27 {28 return c == ',' ? true : false;29 }30 }31}32
测试结果:
Test.Analysis.EsayTooAnalyzer结果:
--------------------------------
,
--------------------------------
有个逗号了!!!哈哈,总算进步了。而把IsTokenChar方法改一下,改成:
protected override bool IsTokenChar(char c)
{
return c == ',' ? false : true;
}
Test.Analysis.EsayTooAnalyzer结果:
--------------------------------
我是中国人,I'can speak chinese
hello world,沪江小Q!
--------------------------------
这下除了逗号,什么都有了。
改成:
protected override bool IsTokenChar(char c)
{
return c == ',' ? false : false;
}
就什么都没了,要是两个都是true,会得什么结果呢?
Lucene.Net 2.3.1开发介绍 —— 二、分词(三)的更多相关文章
- Lucene.Net 2.3.1开发介绍 —— 二、分词(六)
原文:Lucene.Net 2.3.1开发介绍 -- 二.分词(六) Lucene.Net的上一个版本是2.1,而在2.3.1版本中才引入了Next(Token)方法重载,而ReusableStrin ...
- Lucene.Net 2.3.1开发介绍 —— 二、分词(五)
原文:Lucene.Net 2.3.1开发介绍 -- 二.分词(五) 2.1.3 二元分词 上一节通过变换查询表达式满足了需求,但是在实际应用中,如果那样查询,会出现另外一个问题,因为,那样搜索,是只 ...
- Lucene.Net 2.3.1开发介绍 —— 二、分词(四)
原文:Lucene.Net 2.3.1开发介绍 -- 二.分词(四) 2.1.2 可以使用的内置分词 简单的分词方式并不能满足需求.前文说过Lucene.Net内置分词中StandardAnalyze ...
- Lucene.Net 2.3.1开发介绍 —— 二、分词(二)
原文:Lucene.Net 2.3.1开发介绍 -- 二.分词(二) 1.2.分词的过程 1.2.1.分词器工作的过程 内置的分词器效果都不好,那怎么办?只能自己写了!在写之前当然是要先看看内置的分词 ...
- Lucene.Net 2.3.1开发介绍 —— 二、分词(一)
原文:Lucene.Net 2.3.1开发介绍 -- 二.分词(一) Lucene.Net中,分词是核心库之一,当然,也可以将它独立出来.目前Lucene.Net的分词库很不完善,实际应用价值不高.唯 ...
- Lucene.Net 2.3.1开发介绍 —— 四、搜索(二)
原文:Lucene.Net 2.3.1开发介绍 -- 四.搜索(二) 4.3 表达式用户搜索,只会输入一个或几个词,也可能是一句话.输入的语句是如何变成搜索条件的上一篇已经略有提及. 4.3.1 观察 ...
- Lucene.Net 2.3.1开发介绍 —— 三、索引(二)
原文:Lucene.Net 2.3.1开发介绍 -- 三.索引(二) 2.索引中用到的核心类 在Lucene.Net索引开发中,用到的类不多,这些类是索引过程的核心类.其中Analyzer是索引建立的 ...
- Lucene.Net 2.3.1开发介绍 —— 三、索引(四)
原文:Lucene.Net 2.3.1开发介绍 -- 三.索引(四) 4.索引对搜索排序的影响 搜索的时候,同一个搜索关键字和同一份索引,决定了一个结果,不但决定了结果的集合,也确定了结果的顺序.那个 ...
- Lucene.Net 2.3.1开发介绍 —— 四、搜索(三)
原文:Lucene.Net 2.3.1开发介绍 -- 四.搜索(三) Lucene有表达式就有运算符,而运算符使用起来确实很方便,但另外一个问题来了. 代码 4.3.4.1 Analyzer anal ...
随机推荐
- SOA,不看你永远不知道的事
你买不来SOA,只能设计自己的SOA. SOA不是新东西 SOA没有引入新概念,它是个把现有概念和实践放到一起,用于特定需求集的范式.你甚至可以说SOA别的什么都 不是,就是将实用主义和头脑风暴运用到 ...
- Failed to retrieve procctx from ht. constr
给一个客户巡检时发生这样的少见的集群报错: [ OCRSRV][1220598112]th_select_handler: Failed to retrieve procctx from ht. c ...
- qq邮箱是怎么做到同一个浏览器让多个不用用户同时打开的? --session的控制
待解:..... 借鉴网址:http://www.zhihu.com/question/20235500 欢迎来讨论.....
- CF(435D - Special Grid)dp
题目链接:http://codeforces.com/problemset/problem/435/D 题意:求三角形个数,三个点必须的白点上,而且三条边必须是横线,竖线或对角线,三条边上不同意出现黑 ...
- QTP实践总结
QTP实践总结 查询数据库修改freq 1.Testcasetable创建查询select * from testcasetable order by fseq desc 2.设计表-选项-修改自动递 ...
- ACM第三次比赛UVA11877 The Coco-Cola Store
Once upon a time, there is a special coco-cola store. If you return three empty bottles to the sho ...
- windows 下mysql的安装于使用(启动、关闭)
1.下载Windows (x86, 64-bit), ZIP Archive解压: 2.双击在bin目录里的mysqld.exe dos窗体一闪就没了,这时netstat -an发现port3306已 ...
- C/C++迭代器使用具体解释
迭代器是一种检查容器内元素并遍历元素的数据类型.能够替代下标訪问vector对象的元素. 每种容器类型都定义了自己的迭代器类型,如 vector: vector<int>::iterato ...
- opencv视频播放
在一个界面上显示一张图片.是一件非常easy的事情,但说到要显示视频.刚開始学习的人可能不知道怎么处理,事实上,一般来说能够理解为视频就是图片以人眼察觉不到的速度高速更新. 曾经用摄像头採集视频显示在 ...
- C# - 委托_求定积分通用方法
代码: using System; using System.Collections.Generic; using System.Linq; using System.Text; using Syst ...