SQL Server中CURD语句的锁流程分析
DECLARE @DBName nvarchar(128), @sql nvarchar(max);
SET @DBName = DB_NAME();
SET @sql = 'ALTER DATABASE '+@DBName+' SET READ_COMMITTED_SNAPSHOT ON;'
EXEC(@sql); --查看设置结果
SELECT name,snapshot_isolation_state,IS_READ_COMMITTED_SNAPSHOT_ON
FROM sys.databases
WHERE name = @DBName
使用Apq_ID表进行研究
CREATE TABLE [dbo].[Apq_ID]
(
[ID] [bigint] NOT NULL IDENTITY(1, 1),
[Name] [nvarchar] (256) COLLATE Chinese_PRC_CI_AS NOT NULL,
[Crt] [bigint] NOT NULL CONSTRAINT [DF_Apq_ID_Crt] DEFAULT ((0)),
[Limit] [bigint] NOT NULL CONSTRAINT [DF_Apq_ID_Limit] DEFAULT ((0x7FFFFFFF7FFFFFFF)),
[Init] [bigint] NOT NULL CONSTRAINT [DF_Apq_ID_Init] DEFAULT ((0)),
[Inc] [bigint] NOT NULL CONSTRAINT [DF_Apq_ID_Inc] DEFAULT ((1)),
[State] [int] NOT NULL CONSTRAINT [DF_Apq_ID_State] DEFAULT ((0)),
[_Time] [datetime] NOT NULL CONSTRAINT [DF_Apq_ID__Time] DEFAULT (getdate()),
[_InTime] [datetime] NOT NULL CONSTRAINT [DF_Apq_ID__InTime] DEFAULT (getdate())
) ON [PRIMARY]
GO
ALTER TABLE [dbo].[Apq_ID] ADD CONSTRAINT [PK_Apq_ID] PRIMARY KEY NONCLUSTERED ([ID]) WITH (FILLFACTOR=80, PAD_INDEX=ON) ON [PRIMARY]
GO
SET IDENTITY_INSERT dbo.Apq_ID ON;
INSERT INTO dbo.Apq_ID(ID, Name) VALUES(1, 'ISOLATION');
-- 跳过了2,2用于后面观察INSERT
INSERT INTO dbo.Apq_ID(ID, Name) VALUES(3, '');
INSERT INTO dbo.Apq_ID(ID, Name) VALUES(4, '');
INSERT INTO dbo.Apq_ID(ID, Name) VALUES(5, '');
INSERT INTO dbo.Apq_ID(ID, Name) VALUES(6, '');
INSERT INTO dbo.Apq_ID(ID, Name) VALUES(7, '');
INSERT INTO dbo.Apq_ID(ID, Name) VALUES(8, '');
INSERT INTO dbo.Apq_ID(ID, Name) VALUES(9, '');
INSERT INTO dbo.Apq_ID(ID, Name) VALUES(10, '');
INSERT INTO dbo.Apq_ID(ID, Name) VALUES(11, '');
INSERT INTO dbo.Apq_ID(ID, Name) VALUES(12, '');
INSERT INTO dbo.Apq_ID(ID, Name) VALUES(13, '');
INSERT INTO dbo.Apq_ID(ID, Name) VALUES(14, '');
INSERT INTO dbo.Apq_ID(ID, Name) VALUES(15, '');
INSERT INTO dbo.Apq_ID(ID, Name) VALUES(16, '');
INSERT INTO dbo.Apq_ID(ID, Name) VALUES(17, '');
INSERT INTO dbo.Apq_ID(ID, Name) VALUES(18, '');
SET IDENTITY_INSERT dbo.Apq_ID OFF;

SET TRANSACTION ISOLATION LEVEL READ UNCOMMITTED; --未提交读
SET TRANSACTION ISOLATION LEVEL READ COMMITTED; --已提交读
SET TRANSACTION ISOLATION LEVEL REPEATABLE READ; --可重复读
SET TRANSACTION ISOLATION LEVEL SNAPSHOT; --快照(“行版本控制的已提交读”数据库中不支持)
SET TRANSACTION ISOLATION LEVEL SERIALIZABLE; --序列化 SET TRANSACTION ISOLATION LEVEL SERIALIZABLE;--依次改为上面支持的4种不同级别进行测试,下同
BEGIN TRAN DECLARE @name nvarchar(256)
SELECT @name = Name
FROM Apq_ID
WHERE ID = 1;--使用索引 -- 测试结束时回滚事务
--ROLLBACK TRAN
SELECT OBJECT_ID('dbo.Apq_ID');--记录下来,我这里是1829581556,只是为了方便在结果集中看到哪些是与该表相关的锁
-- 查看锁
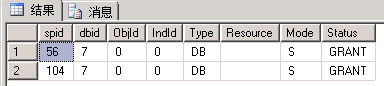
EXEC sp_lock 56, 104; --我这里分别是56和104
对比:
| READ UNCOMMITTED | READ COMMITTED READ_COMMITTED_SNAPSHOT为ON |
REPEATABLE READ | SERIALIZABLE |
  |
同左 |  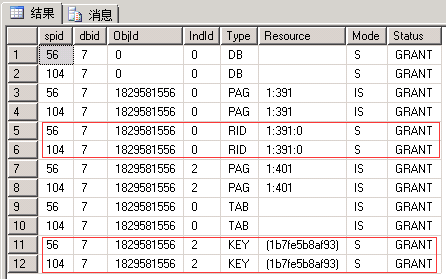 |
同左 |
| 申请:最小粒度为HBT级S锁(基本上可以理解为树型结构的根节点) 释放:语句结束释放(所以图上看不到) 定义级锁,“短”生命周期 |
同左 | 申请:最小粒度为行级S锁 释放:事务结束释放 行级锁,“长”生命周期 |
这个用例中同左。 如果是表扫描,则最小粒度将变为表级S锁 |
| 1.相同点:锁申请均是粒度从大到小。最小粒度的IS锁转换为S锁。(数据库级锁均为S锁) 释放锁时均是按粒度从小到大。 2.不同点:不同隔离级别下申请锁的最小粒度不同,锁的生命周期不同。 |
|||
SET TRANSACTION ISOLATION LEVEL SERIALIZABLE;
BEGIN TRAN DECLARE @Limit bigint, @Inc bigint, @End bigint, @Next bigint;
-- 尝试分配ID
UPDATE Apq_ID
SET _Time = getdate()
,@Limit = Limit
,@Inc = Inc
,@Next = Inc + Crt
,@End = Crt = Inc + Crt
WHERE ID = 1;--直接使用上面查到的1 SELECT @Limit, @Inc, @Next, @End; -- 测试结束时回滚事务
--ROLLBACK TRAN
-- 查看锁
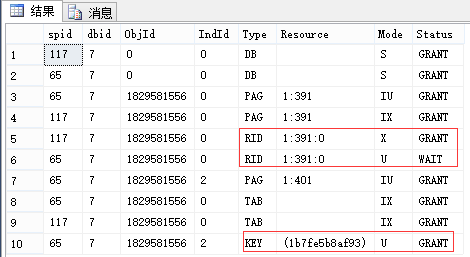
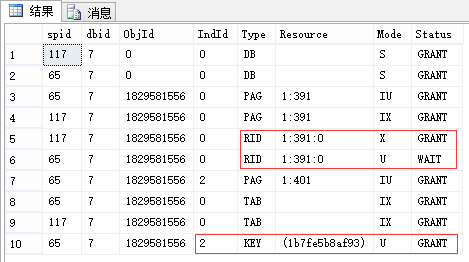
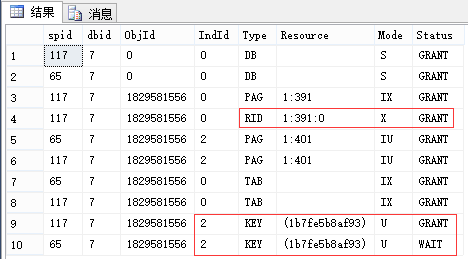
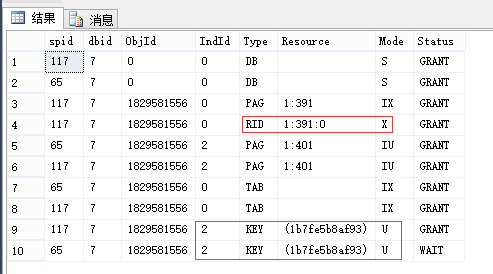
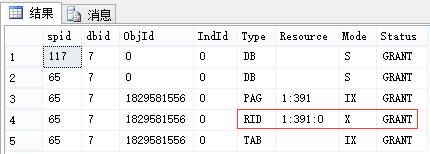
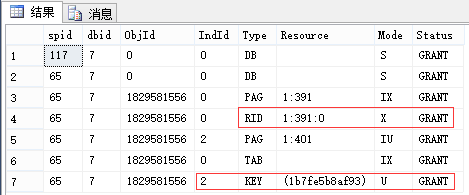
EXEC sp_lock 65, 117; --我这里分别是65和117
对比:
| READ UNCOMMITTED | READ COMMITTEDREAD_COMMITTED_SNAPSHOT为ON | REPEATABLE READ | SERIALIZABLE |
 |
 |
 |
 |
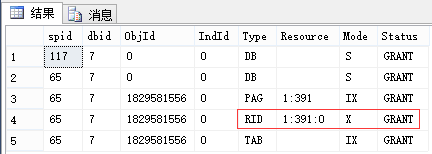
| 117回滚后再查看 | |||
 |
 |
 |
 |
| 申请:最小粒度为行级U锁,有实际写入的行变为X锁 (索引同理,RID对应于Key) 释放:语句结束释放U锁(可理解为因为[这里是索引的]行的临时版本已过期),事务结束释放X锁 |
申请:最小粒度为行级U锁,有实际写入的行变为X锁 (索引同理,RID对应于Key) 释放:事务结束释放U锁和X锁 |
||
| 1.相同点:锁申请均是粒度从大到小,最小粒度锁为行级U锁,其余为IU锁。(数据库级锁均为S锁) 语句执行时实际写入的行才变为X锁,其所在的更大粒度则是变为IX锁。(索引同理) 释放锁时均是按粒度从小到大,X锁都是事务结束释放。 注意:如果是表扫描,则对将要扫描的行都是先加U锁,再判断是否满足条件,不满足时会立即释放。 2.不同点:U锁的生命周期不同。 3.与SELECT对比:没有看到不同的最小粒度。 |
|||
SELECT与UPDATE小结:
S锁的最小粒度:前两个相同,后两个稍有不同。
SET TRANSACTION ISOLATION LEVEL SERIALIZABLE;
BEGIN TRAN -- 使用固定ID,让其冲突
SET IDENTITY_INSERT dbo.Apq_ID ON;
INSERT INTO dbo.Apq_ID(ID, Name) VALUES(2, 'ISOLATION_INSERT');
SET IDENTITY_INSERT dbo.Apq_ID OFF; -- 测试结束时回滚事务
--ROLLBACK TRAN
-- 查看锁
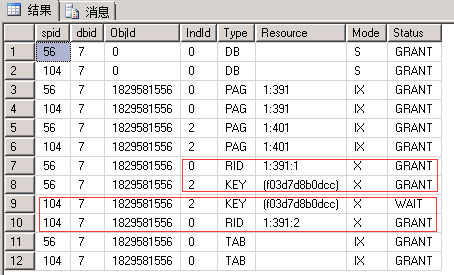
EXEC sp_lock 56, 104; --我这里分别是56和104
结果:
| 都一样 |
 |
| 56回滚后再查看 |
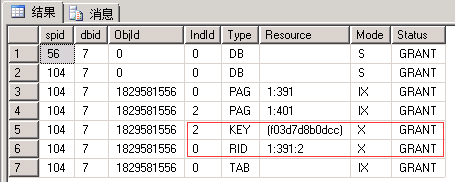 |
| 申请:最小粒度为行级X锁,先行RID后索引Key。 释放:事务结束释放X锁 |
| 可以看出INSERT语句是先写入行数据并加X锁(此时并没有考虑重复),然后写入索引数据(此时才会冲突而无法获取到X锁) |
SET TRANSACTION ISOLATION LEVEL SERIALIZABLE;
BEGIN TRAN -- 使用固定ID,让其冲突
DELETE dbo.Apq_ID WHERE ID = 1; -- 测试结束时回滚事务
--ROLLBACK TRAN
-- 查看锁
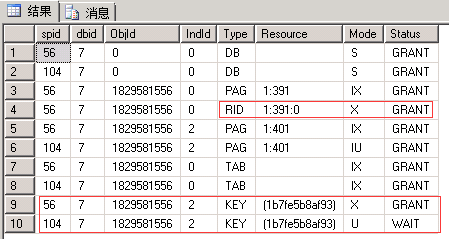
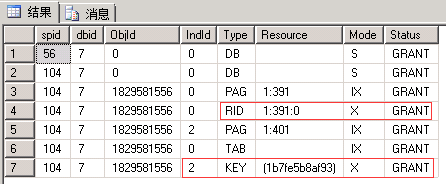
EXEC sp_lock 56, 104; --我这里分别是56和104
对比:
| READ UNCOMMITTED | READ COMMITTED READ_COMMITTED_SNAPSHOT为ON |
REPEATABLE READ | SERIALIZABLE |
  |
同左 |  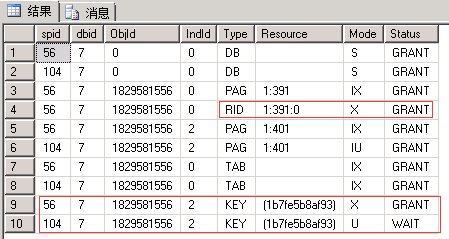 |
同左 |
| 117回滚后再查看 | |||
  |
同左 |  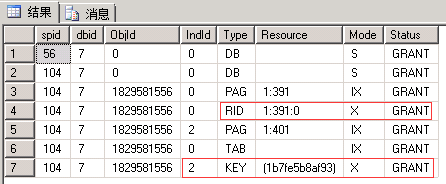 |
同在 |
| 申请:最小粒度为行级U锁,先索引Key后行RID。 语句:有实际删除的行变为X锁 (索引同理,RID对应于Key) 释放:语句结束释放U锁,事务结束释放X锁(这一点没有想到如何证明,因为没有想到让U和X同时存在的办法) |
同左 | 申请:最小粒度为行级U锁,先索引Key后行RID。 语句:有实际删除的行变为X锁 (索引同理,RID对应于Key) 释放:事务结束释放U锁和X锁 |
同左 |
| 1.相同点:基本一样。 2.不同点:U锁的生命周期不同。(未能观察到) |
|||
| 级别 | READ UNCOMMITTED | READ COMMITTED READ_COMMITTED_SNAPSHOT为ON |
REPEATABLE READ | SERIALIZABLE | ||||
| 锁模式 | 最小粒度 | 生命周期 | 最小粒度 | 生命周期 | 最小粒度 | 生命周期 | 最小粒度 | 生命周期 |
| S | HBT | 语句结束 | HBT(未开启行版本则是RID/Key?) 括号中的内容是猜的,懒得测了 |
语句结束 | RID/Key | 事务结束 | RID/Key [表扫描时为TAB] |
事务结束 |
| 读取行数据(可能是修改后尚未提交的) | 读取最后一次已提交的行(可能是“版本化”数据) | |||||||
| HBT级S锁不被数据锁阻塞 | ||||||||
| U | RID/Key | 语句结束 | RID/Key | 语句结束 | RID/Key | 事务结束 | RID/Key [表扫描时为TAB] |
事务结束 |
| X | RID/Key | 事务结束 | RID/Key | 事务结束 | RID/Key | 事务结束 | RID/Key [表扫描时为TAB] |
事务结束 |
| 因为开启了“行版本”,所以对产生实际修改的行,修改前的值会存到tempdb中“版本化”。 事务中多次修改只会保存修改开始时的那个版本(修改前)。 版本化数据由后台线程维护,自动在可以删除时删除。 |
||||||||
|
A:锁分类
按锁关联的数据类型:索引锁,数据锁。
按锁模式分:S、U、X、BU(本文未测试)
按锁类型分:意向锁、真实锁
锁粒度大致量化:
B:锁流程分析
通过以上观察,结合锁升级考虑,可以看出SQL Server锁的申请释放流程大致可分申请阶段、执行阶段与释放阶段:
1.申请阶段:
所有锁申请中,遇到冲突则等待
流程:根据粒度大小,从大到小申请:数据库S锁,架构IS锁(CURD操作总是IS锁,因为并不更改架构),......(各中间粒度的意向锁),直至最小粒度时转换为申请真实锁。
这是一个向下递归过程,非意向锁即为出口(即最小粒度)。相同粒度级别的不同数据类型锁,URD是先索引后数据且深度优先,C(INSERT)则是反过来,因此是取决于执行计划是先读写索引还是先读写表。
这里可能发生锁升级,即当该语句申请的锁数量达到一定程度,锁的最小锁粒度会变成表级。
触发锁升级时,实际上相当于不再申请页级锁和行级锁,而是直接把表级锁当最小粒度进行转换,成功后再释放所有比表级更小粒度的锁。
这也就形成了“数据库引擎不会将行锁或键范围锁升级到页锁,直接升级到表锁”的现象。
2.执行阶段:
执行语句操作,这里有实际更改的最小粒度U锁会转换为X锁。若最小粒度为行级,则其所在的页级IU锁转换为IX锁。
同时行版本开启与否还会影响这里的行为。
3.释放阶段:
根据该锁在当前隔离级别定义的生命周期,按与申请相反的顺序,粒度从小到大,逐级释放。(主要是S锁和U锁的释放不同,有的是语句结束时,有的是事务结束时;X锁的释放一定是最外层事务结束时)
特别地,对于意向锁,当其下面更小粒度的锁全部释放时,该意向锁也被释放。这可以看作是一个向上的递归过程,非意向锁是递归出口(即数据库级),这也是为什么数据库级锁只会是实际锁的原因。
C:表提示
关于查询中的表提示(UPDLOCK、XLOCK等):实际上只是改变了申请阶段的真实锁模式(或锁的最小粒度),并不改变整个锁流程及所申请的锁在各隔离级别下的生命周期。
|
| 锁类型 | 粒度 | 粒度级别(个人看法) |
| RID = 表中单个行的锁,由行标识符 (RID) 标识。 | 数据行 RID | 1 |
| KEY = 索引内保护可串行事务中一系列键的锁。 | 索引键 Key | 1 |
| PAG = 数据页或索引页的锁。 | 页 PAG | 2 |
| EXT = 对某区的锁。 | 区 EXT (max类的列) | 1 |
| TAB = 整个表(包括所有数据和索引)的锁。 | 表 TAB | 3 |
| 上面的锁按锁模式定义可能阻塞其它连接的CURD操作。 CURD操作产生的下面这些锁,则不会阻塞其它连接的CURD操作,因为它们只是(意向)共享锁,但仍有可能阻塞CURD以外的其它操作,如更改架构,表结构,索引定义等。 |
||
| DB = 数据库的锁。 | 库 DB | 6 |
| FIL = 数据库文件的锁。 | 文件 FIL | 5 |
| APP = 指定的应用程序资源的锁。 | 5 | |
| MD = 元数据或目录信息的锁。 | 4 | |
| HBT = 堆或 B 树索引的锁。在 SQL Server 中此信息不完整。 | 4 | |
| AU = 分配单元的锁。在 SQL Server 中此信息不完整。 | ||
RID:格式为 fileid:pagenumber:rid 的标识符,其中 fileid 标识包含页的文件,pagenumber 标识包含行的页,rid 标识页上的特定行。 fileid 与 sys.database_files 目录视图中的 file_id 列相匹配。KEY:数据库引擎内部使用的十六进制数。
U = 更新。 指示对最终可能更新的资源获取的更新锁。 用于防止一种常见的死锁,这种死锁在多个会话锁定资源以便稍后对资源进行更新时发生。X = 排他。 授予持有锁的会话对资源的独占访问权限。
GRANT:已获取锁。
WAIT:锁被另一个持有锁(模式相冲突)的进程阻塞。
SQL Server中CURD语句的锁流程分析的更多相关文章
- 【转】SQL Server中的事务与锁
SQL Server中的事务与锁 了解事务和锁 事务:保持逻辑数据一致性与可恢复性,必不可少的利器. 锁:多用户访问同一数据库资源时,对访问的先后次序权限管理的一种机制,没有他事务或许将会一塌糊涂 ...
- 如何识别和解决SQL Server中的热闩锁(PAGELATCH_EX)
描述 在SQL Server中,内部闩锁体系结构可在SQL操作期间保护内存.通过页面上的读写操作,可以确保内存结构的一致性.从根本上讲,它具有两个类:缓冲区锁存器和非缓冲区锁存器,它们在SQL Eng ...
- SQL Server中的事务与锁
了解事务和锁 事务:保持逻辑数据一致性与可恢复性,必不可少的利器. 锁:多用户访问同一数据库资源时,对访问的先后次序权限管理的一种机制,没有他事务或许将会一塌糊涂,不能保证数据的安全正确读写. 死锁: ...
- [转载]SQL Server中的事务与锁
了解事务和锁 事务:保持逻辑数据一致性与可恢复性,必不可少的利器. 锁:多用户访问同一数据库资源时,对访问的先后次序权限管理的一种机制,没有他事务或许将会一塌糊涂,不能保证数据的安全正确读写. 死锁: ...
- T-SQL查询进阶--SQL Server中的事务与锁
为什么需要锁 在任何多用户的数据库中,必须有一套用于数据修改的一致的规则,当两个不同的进程试图同时修改同一份数据时,数据库管理系统(DBMS)负责解决它们之间潜在的冲突.任何关系数据库必须支持事务的A ...
- 十五、SQL Server中的事务与锁
(转载别人的内容,值得Mark) 了解事务和锁 事务:保持逻辑数据一致性与可恢复性,必不可少的利器. 锁:多用户访问同一数据库资源时,对访问的先后次序权限管理的一种机制,没有他事务或许将会一塌糊涂,不 ...
- SQL Server 中 ROWLOCK 行级锁
一.ROWLOCK的使用 1.ROWLOCK行级锁确保,在用户取得被更新的行,到该行进行更新,这段时间内不被其它用户所修改.因而行级锁即可保证数据的一致性,又能提高数据操作的并发性. 2.ROWLOC ...
- SQL Server中DML语句要申请的锁
对于select语句: 1.当採用表扫描时,会直接锁定page,而不是锁定详细的某条记录,所以会有这些锁: A.数据库S锁 B.表的IS锁 C.页的S锁 2.当採用索引来查找数据时,会锁定详细的记录, ...
- (转)SQL Server 中的事务和锁(三)-Range S-U,X-X 以及死锁
在上一篇中忘记了一个细节.Range T-K 到底代表了什么?Range T-K Lock 代表了在 SERIALIZABLE 隔离级别中,为了保护范围内的数据不被并发的事务影响而使用的一类锁模式(避 ...
随机推荐
- MongoDB的timezone问题
MongoDB是以UTC格式来存储所有时间的,查询的时候也是返回UTC时间,不提供在数据库连接级别的timezone支持,这就带来一个问题:无法使用groupby对日期进行聚合,因为你所在的timez ...
- Transaction的理解
Transaction的理解 待完善......
- 图片裁切插件jCrop的使用心得(一)
之前,项目经理为了提升用户体验让我在之前图片上传功能的基础上实现图片的裁切功能,作为一个前端小白来说听了这个需求心里一紧,毕竟没有做过,于是跟项目经理商量要先做下调研.在一上午的调研中发现了jCrop ...
- CentOS6.4 安装JDK
1.下载JDK,这里用的是jdk-7u65-linux-x64.tar.gz,请到官网上下载. 2.清除默认的JDK,yum remove java 3.解压文件 tar -xzf jdk-7u65- ...
- java根据url获取json对象
package test; import java.io.BufferedReader; import java.io.IOException; import java.io.InputStream; ...
- struts2,登录功能模块实现
功能: ·UserLogin作为控制登录的Action,校验密码成功后记录session,可以选择记住登陆状态,登陆成功后自动跳转到登陆前的URL: ·UserLogout作为控制登录推出的Actio ...
- JDK和Jython安装
下载JAVA SE,下载地址请到oracle官方网站下载. JDK下载地址: http://www.oracle.com/technetwork/java/javase/downloads/jdk8- ...
- Authentication for the REST APIs
HTTP基本认证原理 在HTTP协议进行通信的过程中,HTTP协议定义了基本认证过程以允许HTTP服务器对WEB浏览器进行用户身份认证的方法,当一个客户端向HTTP服务器进行数据请求时,如果客户端未被 ...
- cocos2dx3.4 分割plist图片
如果想要修改一个plist文件新打包成plist,而此刻原来的小图都找不到了,那只能把plist分解了,代码如下: void UiManage::DecodePlist(string imgPath, ...
- 解决Ubuntu14.04下Clementine音乐播放器不能播放wma文件的问题
参考:Ubuntu 14.04 安装深度音乐的方法 问题描述:播放wma文件时提示"GStreamer插件未安装". 解决方法:安装gstreamer-ffmpeg插件即可解决问题 ...