python爬取快手视频 多线程下载
直接开始!
环境: python 2.7 + win10
工具:fiddler postman 安卓模拟器
首先,打开fiddler,fiddler作为http/https 抓包神器,这里就不多介绍。
配置允许https
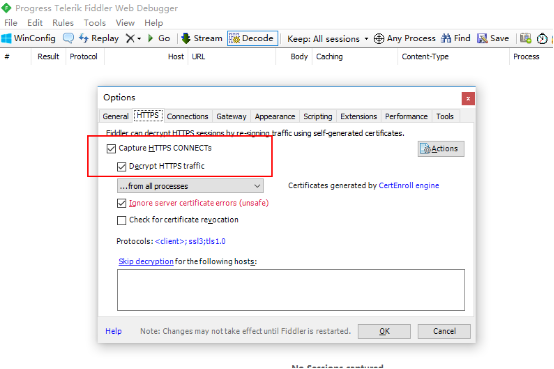
配置允许远程连接 也就是打开http代理

电脑ip: 192.168.1.110
然后 确保手机和电脑是在一个局域网下,可以通信。由于我这边没有安卓手机,就用了安卓模拟器代替,效果一样的。
打开手机浏览器,输入192.168.1.110:8888 也就是设置的代理地址,安装证书之后才能抓包
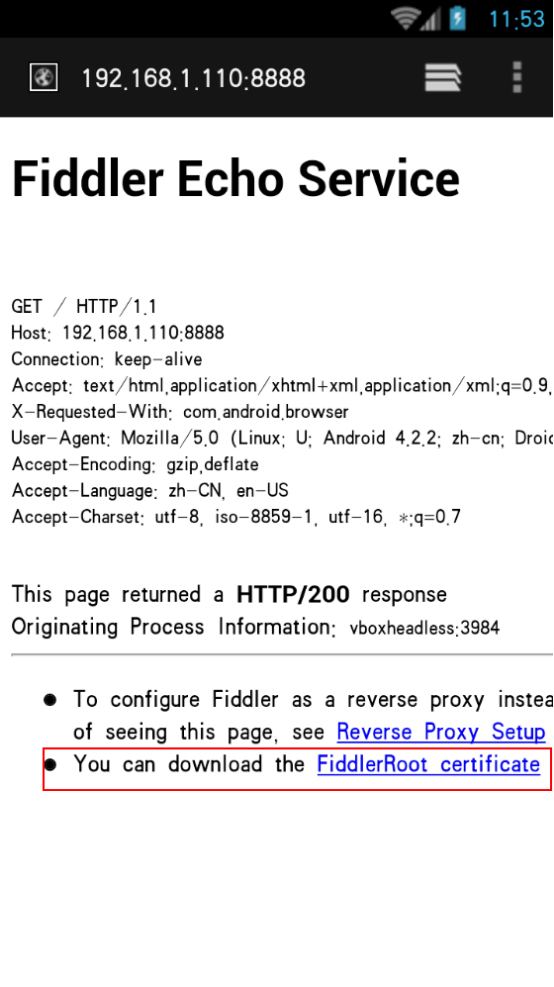
安装证书之后,在WiFi设置 修改网络 手动指定http代理
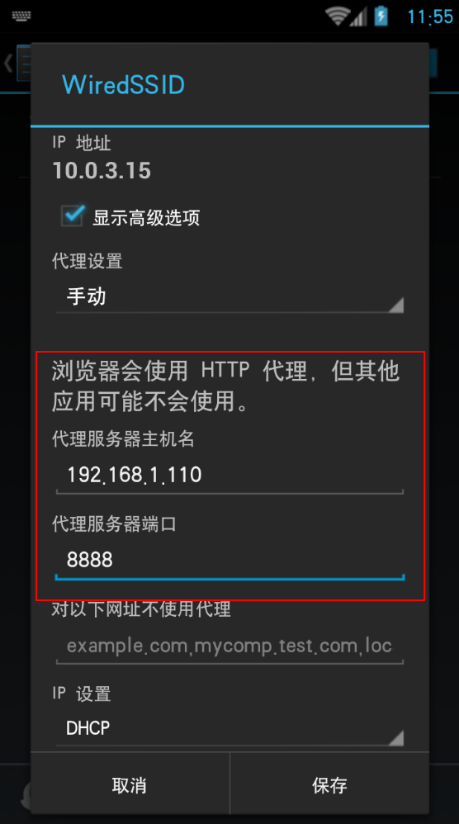
保存后就可以了,fiddler就可以抓到app的数据了,打开快手 刷新,可以 看到有很多http请求进来,一般接口地址之类的很明显的,可以看到 是json类型的
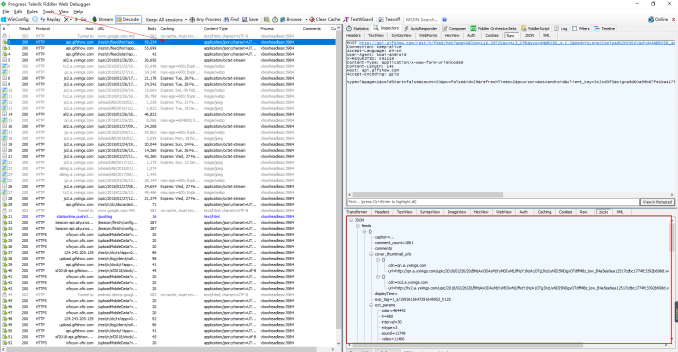
http post请求,返回数据是json ,展开后发现一共是20条视频信息,先确保是否正确,找一个视频链接看下。
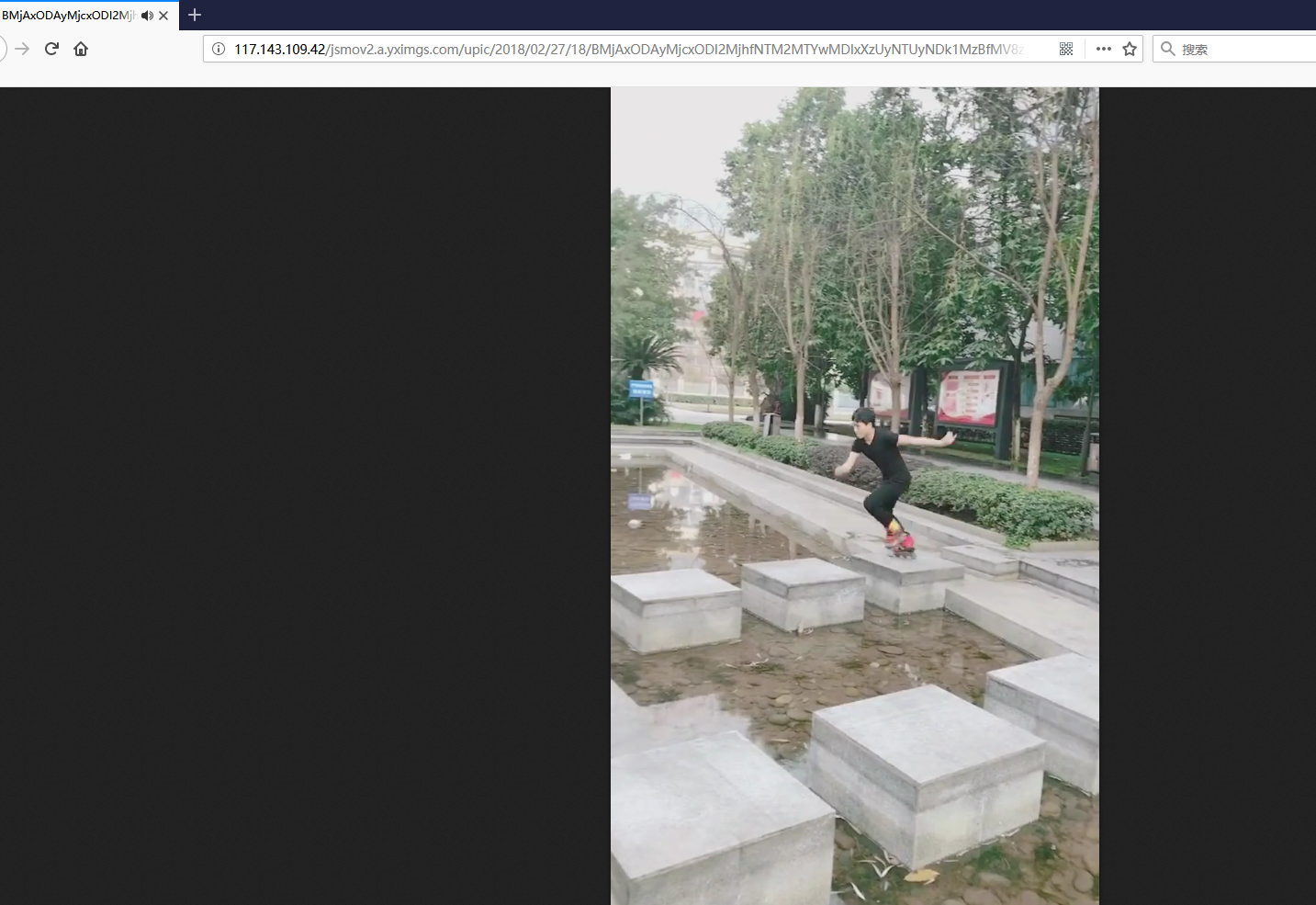
ok 是可以播放的 很干净也没有水印。
那就打开postman 来测试,form-data 方式提交则报错

那换raw 这种
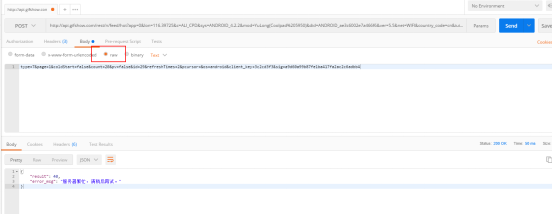
报错信息不一样了,试试加上headers

nice 成功返回数据,我又多试几次,发现每次返回结果不一样,都是20个视频,刚才其中post参数中 有个page=1 这样一直都是第一页 就像一直在手机上不往下翻了 就开始一直刷新那样,反正 也无所谓,只要返回数据 不重复就好。
下面就开始上代码
# -*-coding:utf--*-
# author : Corleone
import urllib2,urllib
import json,os,re,socket,time,sys
import Queue
import threading
import logging # 日志模块
logger = logging.getLogger("AppName")
formatter = logging.Formatter('%(asctime)s %(levelname)-5s: %(message)s')
console_handler = logging.StreamHandler(sys.stdout)
console_handler.formatter = formatter
logger.addHandler(console_handler)
logger.setLevel(logging.INFO) video_q = Queue.Queue() # 视频队列 def get_video():
url = "http://101.251.217.210/rest/n/feed/hot?app=0&lon=121.372027&c=BOYA_BAIDU_PINZHUAN&sys=ANDROID_4.1.2&mod=HUAWEI(HUAWEI%20C8813Q)&did=ANDROID_e0e0ef947bbbc243&ver=5.4&net=WIFI&country_code=cn&iuid=&appver=5.4.7.5559&max_memory=128&oc=BOYA_BAIDU_PINZHUAN&ftt=&ud=0&language=zh-cn&lat=31.319303 "
data = {
'type': ,
'page': ,
'coldStart': 'false',
'count': ,
'pv': 'false',
'id': ,
'refreshTimes': ,
'pcursor': ,
'os': 'android',
'client_key': '3c2cd3f3',
'sig': '22769f2f5c0045381203fc57d1b5ad9b'
}
req = urllib2.Request(url)
req.add_header("User-Agent", "kwai-android")
req.add_header("Content-Type", "application/x-www-form-urlencoded")
params = urllib.urlencode(data)
try:
html = urllib2.urlopen(req, params).read()
except urllib2.URLError:
logger.warning(u"网络不稳定 正在重试访问")
html = urllib2.urlopen(req, params).read()
result = json.loads(html)
reg = re.compile(u"[\u4e00-\u9fa5]+") # 只匹配中文
for x in result['feeds']:
try:
title = x['caption'].replace("\n","")
name = " ".join(reg.findall(title))
video_q.put([name, x['photo_id'], x['main_mv_urls'][]['url']])
except KeyError:
pass def download(video_q):
path = u"D:\快手"
while True:
data = video_q.get()
name = data[].replace("\n","")
id = data[]
url = data[]
file = os.path.join(path, name + ".mp4")
logger.info(u"正在下载:%s" %name)
try:
urllib.urlretrieve(url,file)
except IOError:
file = os.path.join(path, u"神经病呀"+ '%s.mp4') %id
try:
urllib.urlretrieve(url, file)
except (socket.error,urllib.ContentTooShortError):
logger.warning(u"请求被断开,休眠2秒")
time.sleep()
urllib.urlretrieve(url, file) logger.info(u"下载完成:%s" % name)
video_q.task_done() def main():
# 使用帮助
try:
threads = int(sys.argv[])
except (IndexError, ValueError):
print u"\n用法: " + sys.argv[] + u" [线程数:10] \n"
print u"例如:" + sys.argv[] + "" + u" 爬取视频 开启10个线程 每天爬取一次 一次2000个视频左右(空格隔开)"
return False
# 判断目录
if os.path.exists(u'D:\快手') == False:
os.makedirs(u'D:\快手')
# 解析网页
logger.info(u"正在爬取网页")
for x in range(,):
logger.info(u"第 %s 次请求" % x)
get_video()
num = video_q.qsize()
logger.info(u"共 %s 视频" %num)
# 多线程下载
for y in range(threads):
t = threading.Thread(target=download,args=(video_q,))
t.setDaemon(True)
t.start() video_q.join()
logger.info(u"-----------全部已经爬取完成---------------") main()
下面测试

多线程下载 每次下载2000 个视频左右 默认下载到D:\快手

总结:其实我这次爬的快手有点投机取巧了,因为post过去的参数 sign 是签名 的确是有加密的,只所以还能返回数据 那是因为我每次都是请求的一样的链接 page=1 都是第一页的 当我改成2的时候,就验签失败了。然而,它刚好这样也能返回不同的数据,虽然达到了效果,但却没有能破解他的加密算法。。。前两天 爬抖音的时候 也是这样。加密的。。。哎 。技术有限。。逆向不了他的app。。。等以后 有能力搞定了 在来分享吧。。
最后放上我的github地址 : https://github.com/binglansky/spider 也是刚注册的,之前都没提交过代码,也有几个其他的小爬虫,后期找到好玩的 有意思的都会提交上去 。 欢迎学习交流 玩耍 : ) 嘿嘿嘿~
python爬取快手视频 多线程下载的更多相关文章
- python爬取youtube视频 多线程 非中文自动翻译
声明:我写的所有文章都是发在博客园的,我看到其他复制粘贴过去的 连个出处也不写,直接打上自己的水印...真是没的说了. 前言:前段时间搞了一些爬视频的项目,代码都写好了,这里写文章那就在来重新分析一遍 ...
- python爬取豆瓣视频信息代码
目录 一:代码 二:结果如下(部分例子) 这里是爬取豆瓣视频信息,用pyquery库(jquery的python库). 一:代码 from urllib.request import quote ...
- python爬取快手ios端首页热门视频
最近快手这种小视频app,特别的火,中午吃过午饭,闲来无聊,想搞下快手的短视频,看能不能搞到. 于是乎, 打开了fiddler,开始准备抓包, 设置代理,重启,下一步,查看本机ip 手机打开网络设置 ...
- python爬取快手小姐姐视频
流程分析 一.导入需要的三方库 import re #正则表表达式文字匹配 import requests #指定url,获取网页数据 import json #转化json格式 import os ...
- python爬取百思不得姐视频
# _*_ coding:utf-8 _*_ from Tkinter import * from ScrolledText import ScrolledText import urllib #im ...
- python 爬取bilibili 视频信息
抓包时发现子菜单请求数据时一般需要rid,但的确存在一些如游戏->游戏赛事不使用rid,对于这种未进行处理,此外rid一般在主菜单的响应中,但有的如番剧这种,rid在子菜单的url中,此外返回的 ...
- python 爬取bilibili 视频弹幕
# -*- coding: utf-8 -*- # @author: Tele # @Time : 2019/04/09 下午 4:50 # 爬取弹幕 import requests import j ...
- python爬取网站视频保存到本地
前言 文的文字及图片来源于网络,仅供学习.交流使用,不具有任何商业用途,版权归原作者所有,如有问题请及时联系我们以作处理. 作者: Woo_home PS:如有需要Python学习资料的小伙伴可以加点 ...
- 2019-02-09 python爬取mooc视频项目初级简单版
今天花了一下午时间来做这东西,之前没有自己写过代码,50几行的代码还是查了很多东西啊,果然学起来和自己动起手来完全是两码事. 方案:requests库+正则表达式提取视频下载链接+urlretriev ...
随机推荐
- J.U.C ThreadPoolExecutor解析
Java里面线程池顶级接口是Executor,但严格意义上讲Executor并不是一个线程池,而是一个线程执行工具,真正的线程池接口是ExecutorService.关系类图如下: 首先Executo ...
- ASPNET 5 和 dnx commands
DNX项目是用来创建和运行.net应用程序适用于windows,mac 和linux 的,dnx提供了一个宿主进程(a host process),CLR托管逻辑( CLR hosting logic ...
- linux 动态库的符号冲突问题
最近,给同事定位了一个符号表的冲突问题,简单记录一下. A代码作为静态链接库,被包含进了B代码,然后编译成了动态链接库,B.so A代码同时作为静态链接库,被编译进入了main的主代码. main函数 ...
- DataTable转泛型List
在.net项目研发过程中,有时候需要将从数据库中获取的DataTable数据类型,转换为泛型集合,然后运用LINQ对集合进行操作,我将此总结一下,方便你我他. 核心类: public class Da ...
- 2017-07-05 (whereis which find)
whereis whereis 命令名 作用 搜索命令所在的路径以及帮助文档所在的位置 选项 -b 搜索命令所在的位置 -m 搜索帮助文档所在的位置 例子 whereis ls 查看ls命令所在的位 ...
- 针对php脚本文件执行锁定的代码,避免脚本在同一时间重复运行
<?php//针对php脚本文件执行锁定的代码,避免脚本在同一时间重复运行,http://ken.01h.net/define('PHP_LOCK_FILE', dirname(__FILE__ ...
- python3 第二十一章 - 函数式编程之return函数和闭包
我们来实现一个可变参数的求和.通常情况下,求和的函数是这样定义的: def calc_sum(*args): ax = 0 for n in args: ax = ax + n return ax 但 ...
- python3 第一章 - 简介
1.什么是python 引用官方的话:Python是一种易于学习,强大的编程语言.它具有高效的高级数据结构,并通过简单而有效的方法来进行面向对象编程.Python的优雅语法和动态类型,以及其解释性质, ...
- BFC(块级格式上下文)
BFC的生成 满足下列css声明之一的元素便会生成BFC 根元素 float的值不为none overflow的值不为visible display的值为inline-block.table-cell ...
- elasticsearch java和_head插件对索引文档的增删改查
利用head插件: 1,创建索引并添加一条数据(yananindex:索引名称,yanantype:索引类型,1:索引id) 2.修改索引数据(索引id1不变,_version是对该索引数据执行了几次 ...