[DeeplearningAI笔记]02_3.1-3.2超参数搜索技巧与对数标尺
Hyperparameter search
超参数搜索
觉得有用的话,欢迎一起讨论相互学习~Follow Me
3.1 调试处理
需要调节的参数
- 级别一:\(\alpha\)学习率是最重要的需要调节的参数
- 级别二:
- Momentum参数 \(\beta\) 0.9是个很好的默认值
- mini-batch size,以确保最优算法运行有效
- 隐藏单元数量
- 级别三:
- 层数 , 层数有时会产生很大的影响.
- learning rate decay 学习率衰减
- 级别四:
- NG在使用Adam算法时几乎不会调整\(\beta_{1},\beta_{2},\epsilon 的大小\)一般会使用默认的选定值,即\(\beta_{1}=0.9 , \beta_{2}=0.999 , \epsilon=10^{-8}\)
如何选择参数
solution1随机取值
- 在早期的机器学习算法中,如果你有两个需要选择的超参数--超参一和超参二,常见的做法是在网格中取样点,然后系统的研究这些数值.

- 在参数较少的时候,此方法的确很实用,但是对于参数较多的深度学习领域,我们常做的是随机选择点.这个方法是因为对于你要解决的问题而言,你很难提前知道那个超参数最重要.

- 这个问题,我们可以这样来理解.
- 假设超参数一指的是学习率\(\alpha\),超参数二是Adam算法中的\(\epsilon\),在这种情况下,我们知道\(\alpha\)很重要,但是\(\epsilon\)的取值却无关紧要,如果你在网格中取点,接着你试验了\(\alpha\)的5个取值,那你会发现无论\(\epsilon\)如何取值,结果基本上都是一样的.所以即使你考虑了25个值,但进行实验的\(\alpha\)值只有5个
对比而言,如果你随机取值,你会试验25个独立的\(\alpha\)值,所以你似乎会更可能发现效果更好的取值.
- 对于高维参数
例如如果你有三个参数,你搜索的不是一个平面,而是一个立方体.超参数三代表第三维,接着在这个三维空间中取值,你会试验大量的更多的值.

- 实际中,你会在一个更高维的空间中寻找超参数,随机取值,代表了你探究了更多超参数的潜在值.
solution2粗糙到精确取值
- 另一个惯例是采用有粗糙到精细的策略
- 比如你在二维的例子中,你进行了取值,也许你会发现效果更好的某个点,也许这个点周围的其他一些点效果也很好,那么接下来你需要放大这块小区域,然后在其中更密集的随机取值,聚集更多的资源,在这个红色的方格中进行搜索,然后逐渐缩小范围,直到到达一个满意的取值

3.2 为超参数选择合适的范围
用对数标尺搜索超参数空间
- 在超参数范围中,随机取值可以提升你的搜索效率,但是随机取值并不是在有效值的范围内的随机均匀取值,而是选择合适的标尺,这对于探究这些超参数很重要
整数范围
- 假设你要选取的隐藏单元的数量的值的数值范围是50 ~ 100中的某点,或者是层数20 ~ 40,只需要平均的随机从20 ~ 40的范围中选取数字即可.
超参数学习率\(\alpha\)
假设你要搜索的学习率的范围在0.0001 ~ 1的范围中
- 如果使用随机均匀取值(即数字出现在0.0001 ~ 1的范围内的概率相等,出现概率均匀)
- 那么使用上述方法,90%的数值会落在0.1 ~ 1之间,结果就是0.1 ~ 1之间,应用了90% 的资源,而在0.0001到1之间,只有10%的搜索资源
- 使用对数标尺搜索超参数的空间更加合理
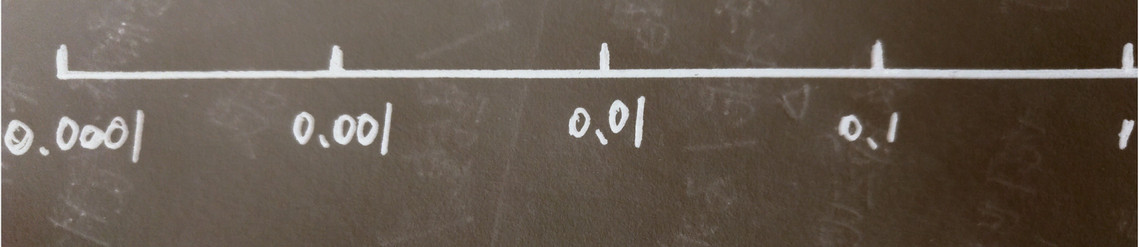
在对数轴上均匀随机取点,这样在0.0001到0.001之间,会有更多的搜索资源可以使用.
- 在python中,你可以这样实现.
- 使r=-4*np.random.rand()[np.random.rand()创建一个给定类型和形状的数组,将其填充到一个均匀分布的随机样本[0,1)中]
- \(\alpha\)随机取值\(\alpha = 10^{r}\),从第一行可以得出\(r\epsilon[-4,0]\),那么\(\alpha在10^{-4}到10^{0}之间\)
更常见的是取值范围是\(10^{a} - 10^{b}\)的一个区间,你可以通过\(log_{10}0.0001\)算出a的值即-4.在右边的值是\(10^{b}\),\(log_{10}1=0\)得到b的值是0.
在[a,b]区间随机均匀的给r取值,将超参数设置为\(10^{r}\),这就是在对数轴上取值的过程.
\(\beta\)计算指数加权平均值
- 假设\(\beta = 0.9-0.999\),对于指数加权平均值,若\(\beta\)=0.9即是取10天中的平均值,若\(\beta\)取0.999即是在1000个值中取指数加权平均值.
- 对于\(\beta= 0.9-0.999\)考虑\((1-\beta)即0.001 - 0.1\),所以去\(r\epsilon[-3,-1]\)则这是超参数的随机取值.
- 对于公式\(\frac{1}{1-\beta}\),当\(\beta\)接近于1时,\(\beta\)就会会对细微的变化十分敏感
- \(\beta_{1}=0.9000\rightarrow0.9005,无论\beta_{1}=0.9000还是0.9005对于\frac{1}{1-\beta_{1}}都没有很大影响.\)
- 但是当\(\beta的取值十分接近于1的时候,例如\beta_{2}=0.999\rightarrow0.9995\),\(\frac{1}{1-0.999}=1000\)表示在1000个数据中取平均\(\frac{1}{1-0.9995}=2000\)表示在2000个数据中取平均,很接近1时看似微小的改动都会带来巨大的差异!
[DeeplearningAI笔记]02_3.1-3.2超参数搜索技巧与对数标尺的更多相关文章
- Coursera Deep Learning笔记 改善深层神经网络:超参数调试 正则化以及梯度相关
笔记:Andrew Ng's Deeping Learning视频 参考:https://xienaoban.github.io/posts/41302.html 参考:https://blog.cs ...
- Coursera Deep Learning笔记 改善深层神经网络:超参数调试 Batch归一化 Softmax
摘抄:https://xienaoban.github.io/posts/2106.html 1. 调试(Tuning) 超参数 取值 #学习速率:\(\alpha\) Momentum:\(\bet ...
- [DeeplearningAI笔记]ML strategy_1_3可避免误差与改善模型方法
机器学习策略 ML strategy 觉得有用的话,欢迎一起讨论相互学习~Follow Me 1.8 为什么是人的表现 今天,机器学习算法可以与人类水平的表现性能竞争,因为它们在很多应用程序中更有生产 ...
- DeepMind提出新型超参数最优化方法:性能超越手动调参和贝叶斯优化
DeepMind提出新型超参数最优化方法:性能超越手动调参和贝叶斯优化 2017年11月29日 06:40:37 机器之心V 阅读数 2183 版权声明:本文为博主原创文章,遵循CC 4.0 BY ...
- DeepLearning.ai学习笔记(二)改善深层神经网络:超参数调试、正则化以及优化--Week2优化算法
1. Mini-batch梯度下降法 介绍 假设我们的数据量非常多,达到了500万以上,那么此时如果按照传统的梯度下降算法,那么训练模型所花费的时间将非常巨大,所以我们对数据做如下处理: 如图所示,我 ...
- 【笔记】KNN之网格搜索与k近邻算法中更多超参数
网格搜索与k近邻算法中更多超参数 网格搜索与k近邻算法中更多超参数 网络搜索 前笔记中使用的for循环进行的网格搜索的方式,我们可以发现不同的超参数之间是存在一种依赖关系的,像是p这个超参数,只有在 ...
- deeplearning.ai 改善深层神经网络 week3 超参数调试、Batch正则化和程序框架 听课笔记
这一周的主体是调参. 1. 超参数:No. 1最重要,No. 2其次,No. 3其次次. No. 1学习率α:最重要的参数.在log取值空间随机采样.例如取值范围是[0.001, 1],r = -4* ...
- Deep Learning.ai学习笔记_第二门课_改善深层神经网络:超参数调试、正则化以及优化
目录 第一周(深度学习的实践层面) 第二周(优化算法) 第三周(超参数调试.Batch正则化和程序框架) 目标: 如何有效运作神经网络,内容涉及超参数调优,如何构建数据,以及如何确保优化算法快速运行, ...
- ng-深度学习-课程笔记-8: 超参数调试,Batch正则(Week3)
1 调试处理( tuning process ) 如下图所示,ng认为学习速率α是需要调试的最重要的超参数. 其次重要的是momentum算法的β参数(一般设为0.9),隐藏单元数和mini-batc ...
随机推荐
- Java反射-中级知识掌握
PS:本文就Java反射常用的中级知识做下汇总和分析/cnxieyang@163.com/xieyang@e6yun.com
- Xtrabackup实现数据的备份与恢复
Xtrabackup介绍 Xtrabackup是由percona开源的免费数据库热备份软件,它能对InnoDB数据库和XtraDB存储引擎的数据库非阻塞地备份(对于MyISAM的备份同样需要加表锁): ...
- Django App(三) View+Template
接着上一节(二)的内容,首先启动站点,通过界面添加Question和Choice两张表的数据,因为接下来,要向polls app里面添加views. 1.添加数据如下(这里是通过界面操作添加的数据) ...
- [学习OpenCV攻略][010][写入AVI文件]
cvSize(文件宽度,文件高度) 通过图片或视频文件的宽高得到尺寸信息,返回值是CvSize cvCreateVideoWriter(输出文件名,编码格式,帧率,图像大小) 通过设置输出视频的格式信 ...
- js动态添加-表格逐行添加、删除、遍历取值
关于js对表格进行逐行添加,今天抽空整理了一下:新建一个html文件(没有编辑器的可以新建一个demo.txt文件,然后改后缀名为demo.html),把下面代码全部贴进去即可.功能包括:表格添加一行 ...
- Spark算子--groupByKey
转载请标明出处http://www.cnblogs.com/haozhengfei/p/0e90fe79f9f2e4b91a5d8e659ee68eaf.html groupByKey--Transf ...
- 学习JVM-GC收集器
1. 前言 在上一篇文章中,介绍了JVM中垃圾回收的原理和算法.介绍了通过引用计数和对象可达性分析的算法来筛选出已经没有使用的对象,然后介绍了垃圾收集器中使用的三种收集算法:标记-清除.标记-整理.标 ...
- nginx重启几种方法
http://blog.csdn.net/zqinghai/article/details/71125045 ps -ef|grep nginx 平滑重启命令: kill -HUP 住进称号或进程号文 ...
- mysql中OPTIMIZE TABLE的作用
转载▼ 1.先来看看多次删除插入操作后的表索引情况 mysql> SHOW INDEX FROM `tbl_name`; +----------+------------+----------- ...
- plist涉及到沙盒的一个问题
http://blog.csdn.net/wowxavi1/article/details/8557271