Hadoop之HDFS优缺点、设计原理、框架
如需大数据开发整套视频(hadoop\hive\hbase\flume\sqoop\kafka\zookeeper\presto\spark):请联系QQ:1974983704
Hadoop的前世今生网上有太多的文章介绍,这儿就不啰嗦了,直接介绍Hadoop的4大主要构成及HDFS的原理、特性
Hadoop运行模式
1.本地模式:一个节点,不会启动任何服务
2.伪分布式模式:一个节点,所有服务均运行在该节点上
3.分布式模式:多个节点
1、Hadoop构成:HDFS(分布式存储系统)
HDFS特性:
1.良好的扩展性
2.高容错性(多备份性,保持数据不丢失)
3.适合PB级以上海量数据的存储
基本原理:
1.将文件切分成等大的数据块,存储到多台机器上
2.将数据切分、容错、负载均衡等功能透明化
3.可将HDFS看成一个容量巨大、具有高容错性的磁盘
2、Hadoop构成:YARN(资源管理系统)
Yarn是什么:
1.负责集群的资源管理和调度
2.使多种计算框架可以运行在一个集群中
Yarn特点:
1.良好的扩展性、高可用性(任何一个组件出现问题都不影响集群运行)
2.对多种类型的应用程序进行统一管理和调度
3.自带了多种用户调度器、适合共享集群环境
3.Hadoop构成:MapReduce(分布式计算框架)
源于Google的MapReduce论文
MapReduce特点:
1.良好的扩展性(加的机器越多计算越快)
2.高容错性
3.适合PB级以上海量数据的离线处理
如何执行:
分为Map和Reduce两个阶段,先经过Map阶段很多任务并行处理,再经过Reduce阶段合并,先拆分再合并,分而治之
4、Hadoop构成:Hive(基于MR的数据仓库)
1.构建在Hadoop之上的数据仓库,数据计算使用MapReduce,存储使用HDFS
2.Hive定义了一种类SQL查询语言--HQL,类似sql但不完全相同(大部分相同)
3.通常用于进行离线数据处理(采用MapReduce)
4.可认为是一个HQL-MR的语言翻译器
HDFS原理、特性与基本架构
Hadoop Distributed File System(HDFS)
- 易于扩展的分布式文件系统
- 运行在大量普通廉价机器上,提供容错机制
- 为大量用户提供性能不错的文件存取服务
HDFS优点
1.高容错性:
数据自动保存多个副本(默认为3份)
副本丢失后,自动恢复
2.适合批处理
移动计算而非数据
数据位置暴漏给计算框架
3.适合大数据数量
TB、PB级别数据
百万规模以上的文件数量
4.流式文件访问
一次性写入,多次读取
保证数据一致性
5.可构建在廉价的机器上
通过多副本提高可靠性
提供了容错和恢复机制
HDFS缺点
1.小文件存储
小文件占用NameNode大量内存
寻道时间超过读取时间
2.并发写入、文件随机修改
一个文件只能有一个写者(不能支持多线程写入)
仅支持append(追加),不支持修改(如果修改会生成新的文件,删除旧文件)
3.低延迟数据访问
比如毫秒级(用MapReduce计算达不到毫秒级)
低延迟与高吞吐率
HDFS基本框架与原理
1、HDFS设计思想
HDFS是将一个文件分割成多个128M的block数据块(当文件小于128M的时候,存储block为文件大小,并非128M),按流式分发到多个节点,有个元数据存储block的顺序及分发到的节点

2.HDFS架构
主从架构(Master-Slave)
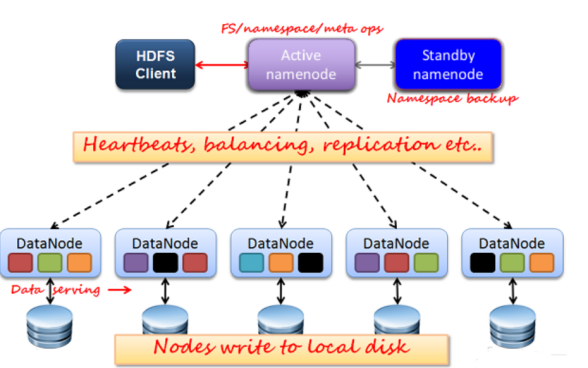
- 主服务为namenode,从服务为datanode,主服务Active namenode容易存在单点故障,所以一般需要一个Standby namenode(在Active namendoe出现故障时即使恢复)
- namenode与datanode直接的连接是通过“心跳机制”,datanode长时间未向namenode报告状态,视为该datanode故障
- Active Namenode:主Master只有一个,管理HDFS的名称空间、管理数据库block映射信息、配置副本策略、处理客户端读写请求
- Standby Namenode:NameNode的热备、定期合并fsimage和fsedits,推送给Namenode、当Active Namenode出现故障时,快速切换为新的Active Namenode
- Datanode:Slave(有多个)、存储实际的数据块、执行数据块读写
- Client:文件切分、与NameNode交互,获取文件位置信息、与DataNode交互读写数据、管理HDFS、访问HDFS
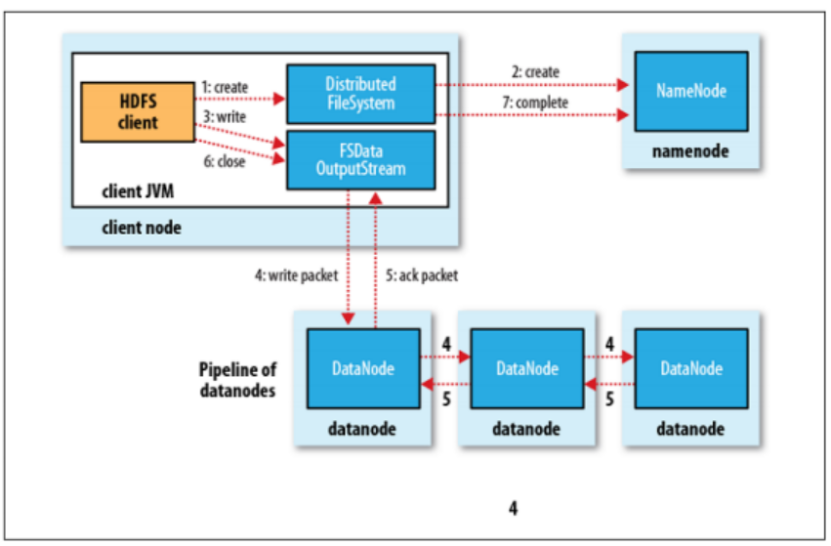
3、HDFS内部机制-写流程
比如将1个block写入到datanode1、datanode2、datanode3,流式过程为:先将block发送到datanode1上,等datanode1写完该block,再由datanode1将block写到datanode2上,datanode2写入到datanode3
4、HDFS数据块(block)
1.文件被切分成固定大小的数据库
默认为128M,可配置
若文件大小不到128M,则单独存成一个block
2.为何数据块(128M)如此之大
数据传输时间超过寻道时间(高吞吐率)
3.一个文件存储方式
按大小切分成若干个block,存在不同节点上
默认一个block有3个副本
Hadoop之HDFS优缺点、设计原理、框架的更多相关文章
- hadoop之hdfs及其工作原理
hadoop之hdfs及其工作原理 (一)hdfs产生的背景 随着数据量的不断增大和增长速度的不断加快,一台机器上已经容纳不下,因此就需要放到更多的机器中,但这样做不方便维护和管理,因此需要一种文件系 ...
- hadoop中HDFS的NameNode原理
1. hadoop中HDFS的NameNode原理 1.1. 组成 包括HDFS(分布式文件系统),YARN(分布式资源调度系统),MapReduce(分布式计算系统),等等. 1.2. HDFS架构 ...
- 大数据:Hadoop(HDFS 的设计思路、设计目标、架构、副本机制、副本存放策略)
一.HDFS 的设计思路 1)思路 切分数据,并进行多副本存储: 2)如果文件只以多副本进行存储,而不进行切分,会有什么问题 缺点 不管文件多大,都存储在一个节点上,在进行数据处理的时候很难进行并行处 ...
- 【Hadoop】HDFS的运行原理
博文已转移,请借一步说话http://www.weixuehao.com/archives/596 简介 HDFS(Hadoop Distributed File System )Hadoop分布式文 ...
- 2本Hadoop技术内幕电子书百度网盘下载:深入理解MapReduce架构设计与实现原理、深入解析Hadoop Common和HDFS架构设计与实现原理
这是我收集的两本关于Hadoop的书,高清PDF版,在此和大家分享: 1.<Hadoop技术内幕:深入理解MapReduce架构设计与实现原理>董西成 著 机械工业出版社2013年5月出 ...
- Hadoop分布式文件系统(HDFS)设计
Hadoop分布式文件系统是设计初衷是可靠的存储大数据集,并且使应用程序高带宽的流式处理存储的大数据集.在一个成千个server的大集群中,每个server不仅要管理存储的这些数据,而且可以执行应用程 ...
- Hadoop(六)之HDFS的存储原理(运行原理)
前言 其实说到HDFS的存储原理,无非就是读操作和写操作,那接下来我们详细的看一下HDFS是怎么实现读写操作的! 一.HDFS读取过程 1)客户端通过调用FileSystem对象的open()来读取希 ...
- 【转载】Hadoop分布式文件系统HDFS的工作原理详述
转载请注明来自36大数据(36dsj.com):36大数据 » Hadoop分布式文件系统HDFS的工作原理详述 转注:读了这篇文章以后,觉得内容比较易懂,所以分享过来支持一下. Hadoop分布式文 ...
- Hadoop之HDFS原理及文件上传下载源码分析(下)
上篇Hadoop之HDFS原理及文件上传下载源码分析(上)楼主主要介绍了hdfs原理及FileSystem的初始化源码解析, Client如何与NameNode建立RPC通信.本篇将继续介绍hdfs文 ...
- Hadoop基础-Hdfs各个组件的运行原理介绍
Hadoop基础-Hdfs各个组件的运行原理介绍 作者:尹正杰 版权声明:原创作品,谢绝转载!否则将追究法律责任. 一.NameNode工作原理(默认端口号:50070) 1>.什么是NameN ...
随机推荐
- Kato's inequality and subharmonic function
If $\Delta u=0$ in $\Omega\subset\mathbb{R}^n (n\geq2)$, then for $p>\frac{n-2}{n-1}$, $|Du|^p$ ...
- GuzzleHttp示例
一般请求 $httpClient = new Client([ 'timeout' => 5 ]); $request = $httpClient->post("http://l ...
- 我和Java这些年的故事(三)
J2EE让Java在服务端找到了用武之地,之前一直处于鄙视链末端的Java,也终于有了向VB/VC叫板的资本.EJB更是J2EE的代名词,是解决企业级组件复用的法宝. 有了JSP/Servlet,Ja ...
- 【基础】为何odd negative scaling会导致Unity动态合批失败?
https://blog.csdn.net/weixin_41885426/article/details/109817466
- 92、kkfile打印当前页
使用kkfile预览pdf时,有肯能需要打印其中的某一张.如果pdf中有几百张,那么打印加载就会很慢.打印当前页就不会出现这个问题. 这个是我编译后的,有需要的请联系QQ: 1842988062
- NOIP2022 游记
无论结局如何,我都曾经来过. Day -1 zak 模拟赛,被殴打了. Day 0 上午 补模拟赛题. 下午 补模拟赛题. 徐老师过来分配了第二天下午造数据名单. 我造 T2.希望不会太难.(flag ...
- imputation-综述文章:关于网络推理的scRNA序列插补工具基准突出了高稀疏性水平下的性能缺陷
文章题目: Benchmarking scRNA-seq imputation tools with respect to network inference highlights 中文题目: 关于网 ...
- Mysql数据库基础第二章:(十)联合查询
Mysql数据库基础系列 软件下载地址 提取码:7v7u 数据下载地址 提取码:e6p9 mysql数据库基础第一章:(一)数据库基本概念 mysql数据库基础第一章:(二)mysql环境搭建 mys ...
- ABAP 报表的两种下钻功能
在报表开发中往往会由需求要求跳转,SAP中提供了一些下钻的方式. 这里主要介绍两种 submit 和 call transaction submit 引用的是报表名称,以自开发报表居多 call tr ...
- iOS 15 UI适配
1. UINavigationBar 在iOS 15中,UINavigationBar默认为透明.在滑动时会有模糊效果.如果想要一直就是模糊效果,可以通过改变scrollEdgeAppearance属 ...