MySQL中读页缓冲区buffer pool
Buffer pool
我们都知道我们读取页面是需要将其从磁盘中读到内存中,然后等待CPU对数据进行处理。我们直到从磁盘中读取数据到内存的过程是十分慢的,所以我们读取的页面需要将其缓存起来,所以MySQL有这个buffer pool对页面进行缓存。
首先MySQL在启动时会向操作系统申请一段连续的内存空间,这一段空间就是作为buffer pool所用。将缓存的页放入buffer pool中管理起来。
mysql> show variables like 'innodb_buffer_pool_size';
+-------------------------+-----------+
| Variable_name | Value |
+-------------------------+-----------+
| innodb_buffer_pool_size | 134217728 |
+-------------------------+-----------+
1 row in set, 1 warning (0.00 sec)
我们可以看到默认是134217728字节,即128MB。一个页面是16KB,我们申请16KB倍数的缓存区大小就不会产生碎片。
buffer pool组成
同时呢,在buffer pool中还有包含每个页面的控制信息,即控制块。每个控制块对应管理每一个页面 (我们使用地址引用每一个页面) ,控制块用来存储页面的一些信息,控制块的占用大小不包括在innodb_buffer_pool_size中。由MySQL在启动时自己额外申请空间。
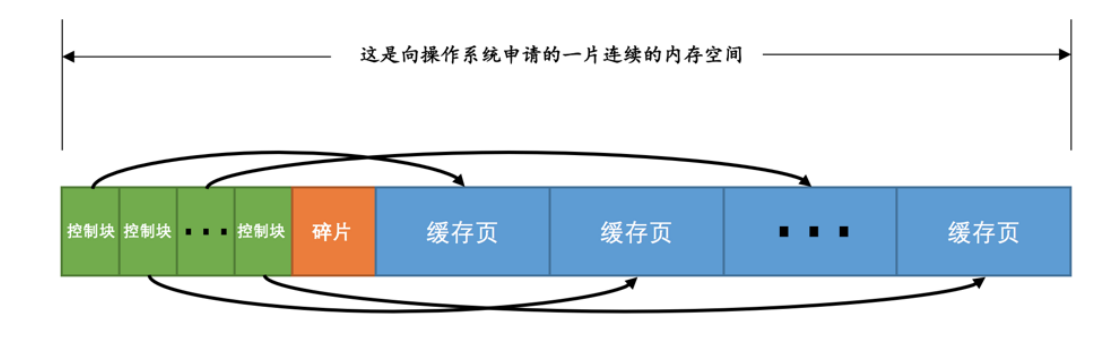
在控制块和缓存页中间会有部分碎片,就是空间无法全部利用的产生的碎片。因为MySQL向操作系统申请的内存空间需要申请一定大小的控制块空间,不能确定具体的大小,难免回有无法利用的空间。
free链表
free链表顾名思义,就是管理空闲的缓存页的链表,如果缓存页没有被使用,其控制块就会连接到free链表上。
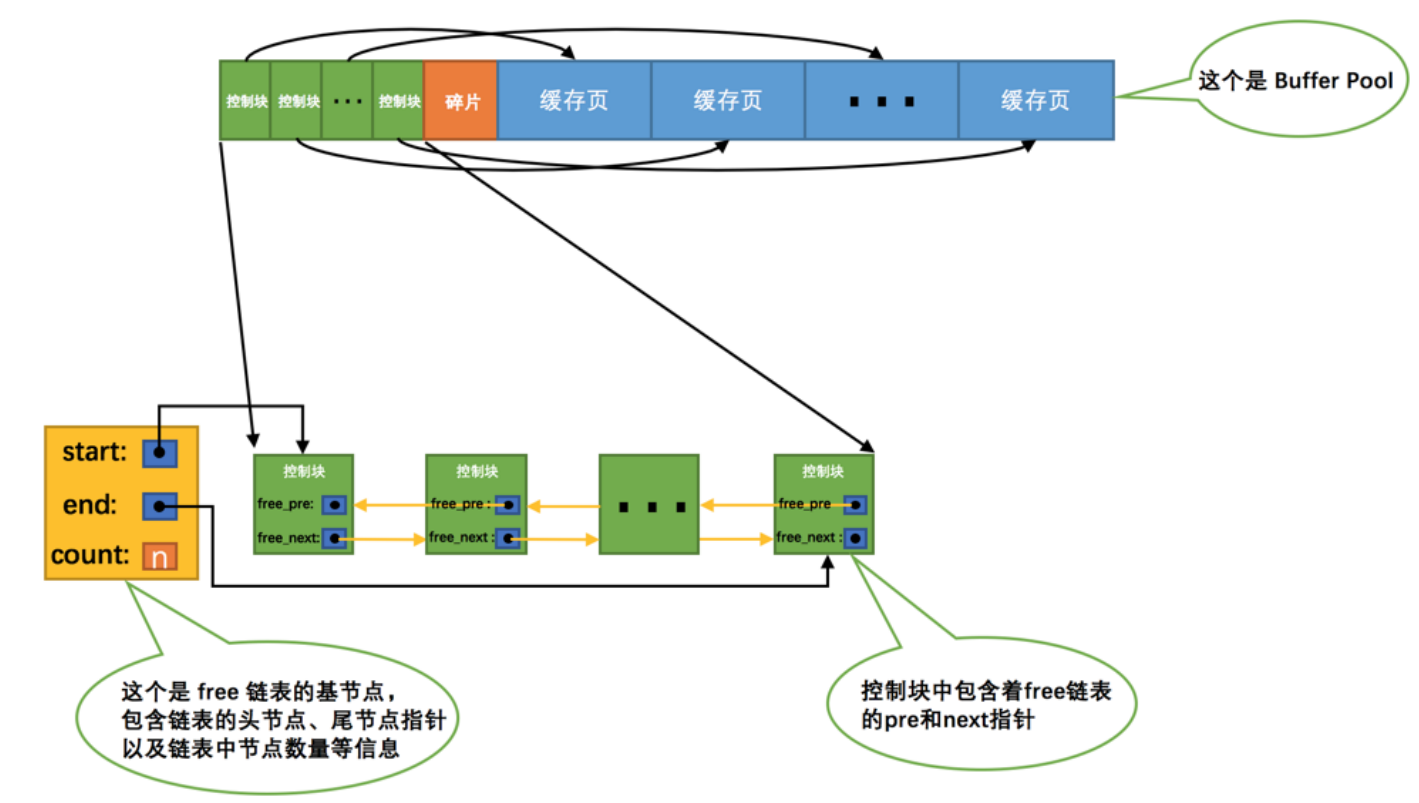
通过一个基节点连接控制块形成一个free链表,并存储空闲页的数量等基本信息。
当我们从磁盘读取一个页到buffer pool中,就会取一个空闲的控制块填上对应缓存页的基本信息。
缓存页的哈希处理
MySQL在buffer pool中怎么快速存取一个页,以及查看对应页有没有被缓存到buffer pool中呢?
这就是用到哈希表,在Java中就是hashmap,通过表空间+页号做处理形成一个hash的key值,然后value值就是缓存页在buffer pool中的地址。
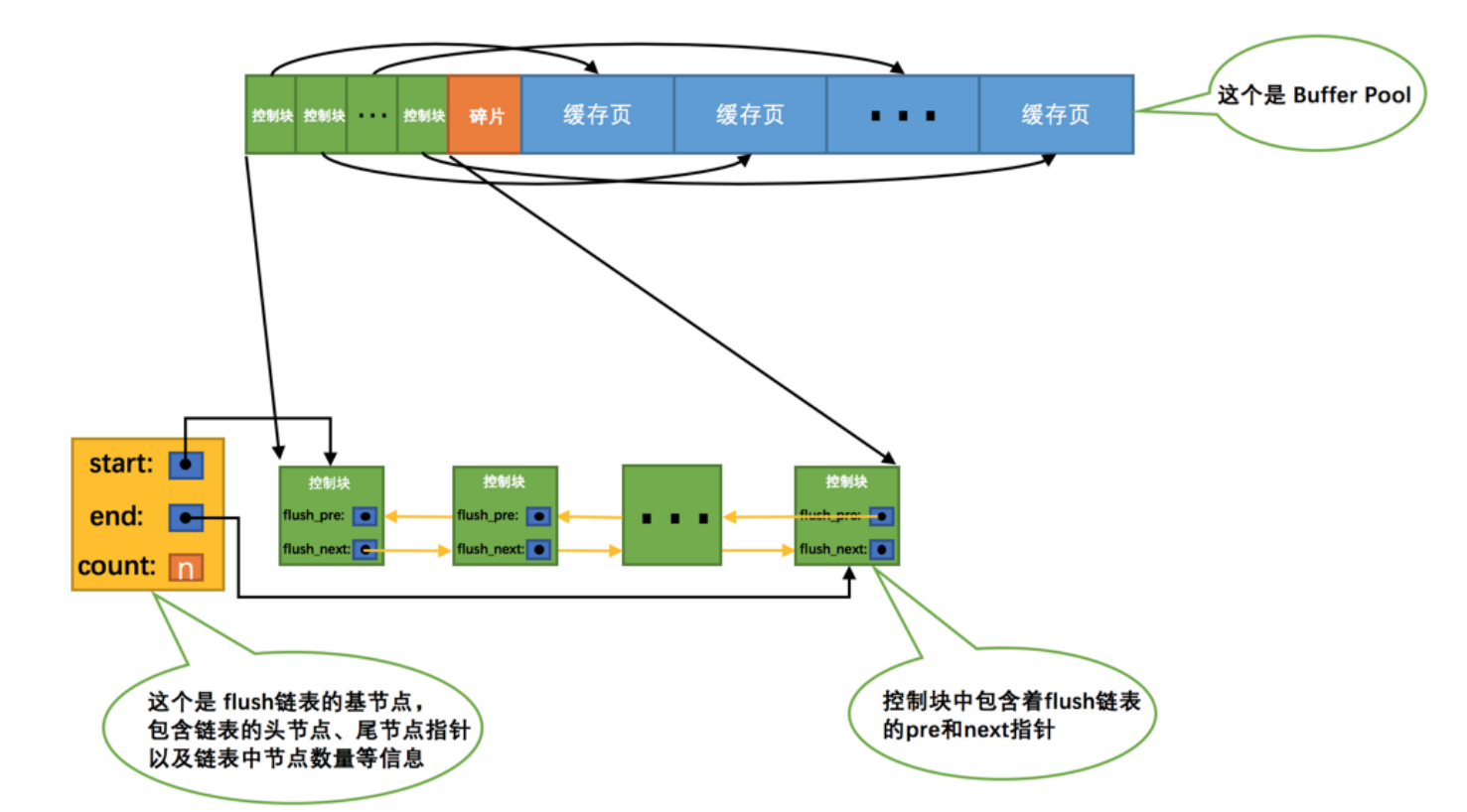
flush链表的管理
学习到这一章节的时候我震惊了,首先确实和我的理解是不一样的,以及到后面的MVCC确实让我大开眼界,这是我学习一遍后回头做的总结,所以比较言简意赅哈。
我们使用SQL语句对某条记录进行修改的时候,就会修改某个页面或者多个页面,我们对于页面的修改呢,并不会直接对磁盘进行对应的修改,因为对于磁盘IO实在是太慢了,我们首先会将修改的页面(简称脏页)链起来,就和free链表差不多,就是一个基节点将对应脏页的控制块连接在一起。
这个flush链表就代表我们即将还没有将页面更新到磁盘的链表。
LRU链表
因为buffer pool的大小是有限的,所以我们对于缓存页的大小是有限的,所以我们需要将不用的页面进行一个淘汰。MySQL采用的就是LRU的方式进行淘汰。
LRU就是最久未使用淘汰的策略,我们使用一个链表将缓存页面链起来,最近访问的出现在最前面,最久未访问的在链表末尾,当LRU满了新页面都进来机会淘汰链表尾部页面。
我们直接使用LRU,当MySQL进行预读或者全表扫描出现大量低频页面被读进LRU链表,会导致高频的页面直接被淘汰掉了,取而代之的是一些不经常用的页面。
预读就是MySQL优化器认为当前请求可能会读取的页面,预先将其加载到内存的buffer pool中。可以分为两种:
线性预读
当读取一个区的页面超过系统变量innodb_read_ahead_threshold的值默认为56,也就是说当我们读取一个区的页面超过56页,MySQL就会异步的读取下一个区的所有页面到内存中。
随机预读
如果buffer pool已经缓存了某个区的13个页面,不管是不是顺序的,只要有13页缓存了,就会触发MySQL异步读取本区的所有页面到MySQL中。我们可以控制关闭随机预读,也就是系统变量innodb_random_read_ahead。默认是OFF。
所以出现了改进基于分区的LRU链表,将链表分为两份。
一个是使用频率非常高的young区域,一个是使用频率不是很高的old区。
正常来说old区占比是37%,所以young区就占63%,我们可以通过innodb_old_blocks_pct来修改,默认就是37。
我们来讲讲这个基于分区的LRU链表。
- 首先buffer pool初始化,会将读取的页面直接放进old区。
- 但是如果我们对于同一个页面的多条记录进行访问的话,我们就会多次访问同一页多次。但是如果我们是全表扫描的话,是可能会将所有页面缓存进缓存池中的,所以MySQL对于其进行优化。
- 所以MySQL对于当页面第一次读入old区并在一定时间间隔(innodb_old_blocks_pct)内的多次访问来说是不会将其放入young区进行缓存的。innodb_old_blocks_pct的值默认为1000,就是刚来的来一秒内的多次访问是不会将其转移到young区的。
- 如果多次访问就会将old区的页升级到young区。当young区的页面被访问,只有young链表后1/4的页面被访问时才会将其转置到young区链表头,不然就不会改动,减少一些调整链表的性能损失。
刷新脏页
MySQL会启动后台线程进行脏页,也就是修改的页面进行刷新到磁盘。
以下有两种方式刷新脏页:
- 从LRU的尾部扫描一些页面,刷新其中的脏页到磁盘中。
- 后台线程会从LRU链表中old区域尾部,即不经常使用的页面中查找有没有脏页,有就更新到磁盘。可以更改系统变量innodb_lru_scan_depth来控制扫描区域尾部的数量。
- 从flush链表中更新到磁盘。
- 我们上面说了flush连接这脏页的控制块,我们就可以将连接这flush链表的脏页进行更新。
疑问:为什么要两种方式更新呢?我刚开始不懂这是我回过头来看的时候就懂了
首先我们脏页是缓存在buffer pool中的,但是我们buffer pool空间是有限的,又因为我们使用的是LRU的方式,又因为从flush链表将脏页同步到磁盘效率实在不高,所以不会很经常去更新脏页。如果我们不更新直接将其从LRU的链表抛弃也就是从缓存池中直接扔了,但是它是脏页就无法同步到磁盘了,同时flush链表链接的也会出现问题。
所以在LRU淘汰很久未使用的页有个前提就是它不是一个脏页。所以我们会去检测LRU链表尾部有没有脏页,然后更新它,我们才能去淘汰掉这些页。
flush链表更新那就是它的本职工作了,它存这个也是干这个的,应该没有什么问题。
当系统十分繁忙,buffer pool使用量不足的时候,因为磁盘IO太慢了,所以会出现一种情况,就是大量的用户线程也在进行这个同步脏页的活。不同步脏页然后淘汰buffer pool的页面,没法读取页面啊。
多个buffer pool实例
我们可以设置多个buffer pool来实现多实例提高性能。
mysql> show variables like 'innodb_buffer_pool_instances';
+------------------------------+-------+
| Variable_name | Value |
+------------------------------+-------+
| innodb_buffer_pool_instances | 1 |
+------------------------------+-------+
1 row in set, 1 warning (0.00 sec)
我们可以设置innodb_buffer_pool_instances系统变量来控制实例变量。
但是当buffer pool的大小小于1G的时候,设置2个实例也是没有用的(会被恢复成1个),多实例的情况是建立在大内存的情况下的。
动态调整buffer pool大小
在MySQL5.7.5后,MySQL中的buffer pool的大小是以chunk来分配了,如下图。
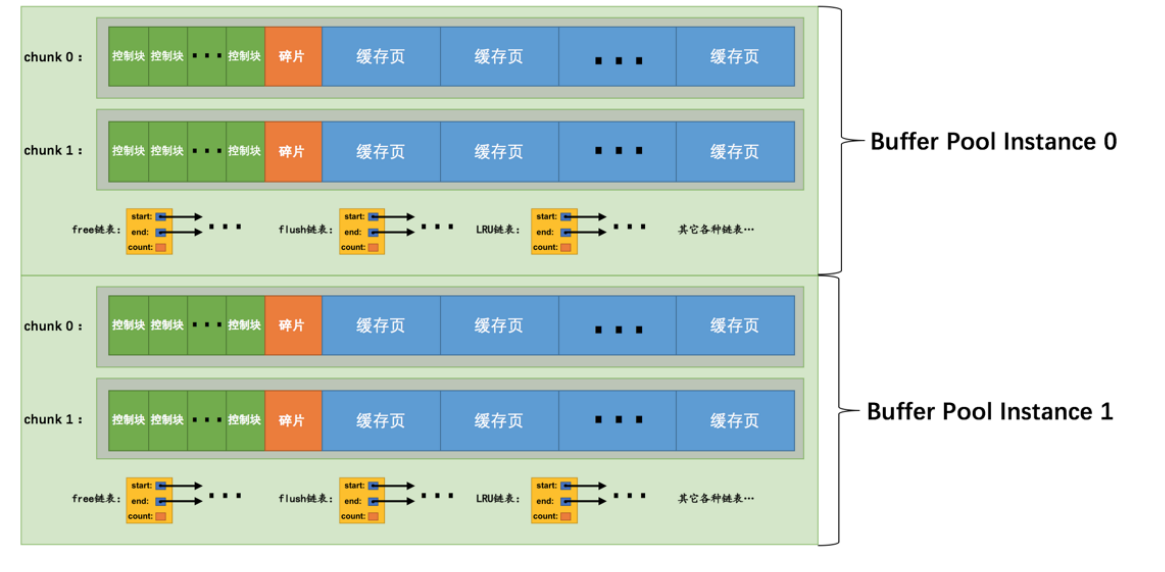
一个buffer pool是由多个chunk组成的,所以MySQL向操作系统申请连续的内存空间,就是以chunk的方式来申请的,这样我们可以在MySQL运行时调整buffer pool的大小。但是chunk的大小是不能在运行时更改的,这样是很耗费性能的。?
innodb_buffer_pool_size / innodb_buffer_pool_instances = 每个实例buffer pool的大小。
每个实例的大小 / innodb_buffer_pool_chunk_size = 每个实例由多少个chunk构成。
不是弄很明白,怎么动态调整大小,我调整了但是mysqld占用内存大小还是只能重启才能生效,我不会。
查看buffer pool具体的信息
show engine innodb status;
MySQL中读页缓冲区buffer pool的更多相关文章
- MySQL缓存之Qcache与buffer pool对比
Q:innodb buffer pool和Qcache的缓存区别? A: 1.Qcacche缓存的是SQL语句及对应的结果集,缓存在内存,最简单的情况是SQL一直不重复,那Qcache的命令率肯定是0 ...
- 【大白话系统】MySQL 学习总结 之 缓冲池(Buffer Pool) 的设计原理和管理机制
一.缓冲池(Buffer Pool)的地位 在<MySQL 学习总结 之 InnoDB 存储引擎的架构设计>中,我们就讲到,缓冲池是 InnoDB 存储引擎中最重要的组件.因为为了提高 M ...
- 【大白话系统】MySQL 学习总结 之 缓冲池(Buffer Pool) 如何支撑高并发和动态调整
如果大家对我的 [大白话系列]MySQL 学习总结系列 感兴趣的话,可以点击关注一波. 一.上节回顾 在上节< 缓冲池(Buffer Pool) 的设计原理和管理机制>中,介绍了缓冲池整体 ...
- mysql 中翻页
万变不离其中 select * from tableName where 条件 limit 当前页码*页面容量-1 , 页面容量
- MySQL · 性能优化· InnoDB buffer pool flush策略漫谈
MySQL · 性能优化· InnoDB buffer pool flush策略漫谈 背景 我们知道InnoDB使用buffer pool来缓存从磁盘读取到内存的数据页.buffer pool通常由数 ...
- MySQL · 引擎特性 · InnoDB Buffer Pool
前言 用户对数据库的最基本要求就是能高效的读取和存储数据,但是读写数据都涉及到与低速的设备交互,为了弥补两者之间的速度差异,所有数据库都有缓存池,用来管理相应的数据页,提高数据库的效率,当然也因为引入 ...
- 020:Buffer Pool 、压缩页、CheckPoint、Double Write、Change Buffer
一. 缓冲池(Buffer Pool) 1.1 缓冲池介绍 每次读写数据都是通过 Buffer Pool : 当Buffer Pool 中没有用户所需要的数据时,才去硬盘中获取: 通过 innodb_ ...
- 一文了解MySQL的Buffer Pool
摘要:Innodb 存储引擎设计了一个缓冲池(Buffer Pool),来提高数据库的读写性能. 本文分享自华为云社区<MySQL 的 Buffer Pool,终于被我搞懂了>,作者:小林 ...
- Mysql InnoDB Buffer Pool
参考书籍<mysql是怎样运行的> 系列文章目录和关于我 一丶为什么需要Buffer Pool 对于InnoDB存储引擎的表来说,无论是用于存储用户数据的索引,还是各种系统数据,都是以页的 ...
随机推荐
- java堆排序
直接贴源代码: package com.java.fmd; import java.util.Scanner; public class HeapSort { int[] arr; public st ...
- 【Android开发】毛玻璃效果
使用一:静态控件上使用 先附上自定义view-BlurringView public class BlurringView extends View { private int mDownsample ...
- 华为交换机Stelnet ssh/rsa验证模式下16进制公钥生成方法
1.生成秘钥 需要在你自己电脑上生成 执行下面命令,默认生成位置是~/.ssh ssh-keygen -t rsa -b 1024 -f yourkeyname -C "备注" 参 ...
- 01 | 堆、栈、RAII:C++里该如何管理资源?(极客时间笔记)
基本概念 堆,英文是 heap,在内存管理的语境下,指的是动态分配内存的区域.这个堆跟数据结构里的堆不是一回事.这里的内存,被分配之后需要手工释放,否则,就会造成内存泄漏. C++ 标准里一个相关概念 ...
- Zabbix-Proxy 部署和运行
Zabbix-Proxy 部署&运行 前提 版本: zabbix-server 5.4 任务: 通过SNMP监控网络设备,需要需通过zabbix-proxy 发送到zabbix-server. ...
- 一篇文章带你搞懂InnoDB的索引|结合样例
关注公众号[程序员白泽],带你走进一个不一样的程序员/学生党 前言 前阵子面试的时候,在第三面问到了MySQL索引相关的知识点,并且给出了一些SQL语句分析索引的执行情况.所以今天这篇文章给大家讲讲索 ...
- 2021.12.08 [SHOI2009]会场预约(平衡树游码表)
2021.12.08 [SHOI2009]会场预约(平衡树游码表) https://www.luogu.com.cn/problem/P2161 题意: 你需要维护一个 在数轴上的线段 的集合 \(S ...
- 2021.07.26 P1010 幂次方(数论)
2021.07.26 P1010 幂次方(数论) [P1010 NOIP1998 普及组] 幂次方 - 洛谷 | 计算机科学教育新生态 (luogu.com.cn) 重点: 1.二进制 题意: 用20 ...
- ElasticSearch7.3学习(二十一)----Filter与Query对比、使用explain关键字分析语法
1.数据准备 首先创建book索引 PUT /book/ { "settings": { "number_of_shards": 1, "number ...
- 通过 SingleFlight 模式学习 Go 并发编程
最近接触到微服务框架go-zero,翻看了整个框架代码,发现结构清晰.代码简洁,所以决定阅读源码学习下,本次阅读的源码位于core/syncx/singleflight.go. 在go-zero中Si ...