jdk1.8中hashmap的扩容resize
1 final Node<K,V>[] resize() {
2 Node<K,V>[] oldTab = table;
3 int oldCap = (oldTab == null) ? 0 : oldTab.length;
4 int oldThr = threshold;
5 int newCap, newThr = 0;
6 if (oldCap > 0) {
7 if (oldCap >= MAXIMUM_CAPACITY) {
8 threshold = Integer.MAX_VALUE;
9 return oldTab;
10 }
11 else if ((newCap = oldCap << 1) < MAXIMUM_CAPACITY &&
12 oldCap >= DEFAULT_INITIAL_CAPACITY) //注释1
13 newThr = oldThr << 1; // double threshold
14 }
15 else if (oldThr > 0) // initial capacity was placed in threshold
16 newCap = oldThr;
17 else { // zero initial threshold signifies using defaults
18 newCap = DEFAULT_INITIAL_CAPACITY;
19 newThr = (int)(DEFAULT_LOAD_FACTOR * DEFAULT_INITIAL_CAPACITY);
20 }
21 if (newThr == 0) {
22 float ft = (float)newCap * loadFactor;
23 newThr = (newCap < MAXIMUM_CAPACITY && ft < (float)MAXIMUM_CAPACITY ?
24 (int)ft : Integer.MAX_VALUE);
25 }
26 threshold = newThr;
27 @SuppressWarnings({"rawtypes","unchecked"})
28 Node<K,V>[] newTab = (Node<K,V>[])new Node[newCap];
29 table = newTab;
30 if (oldTab != null) {
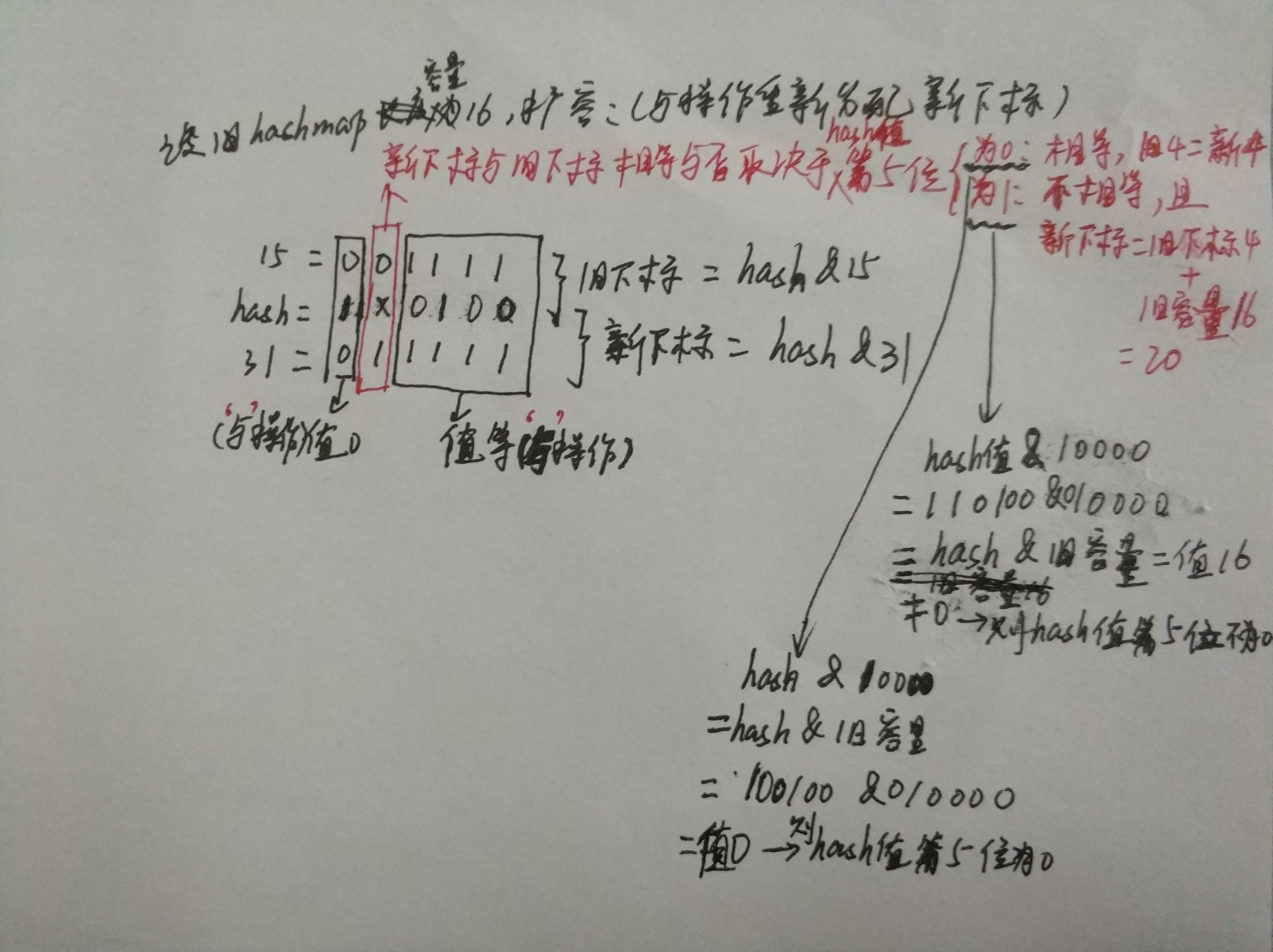
31 for (int j = 0; j < oldCap; ++j) { //注释2
32 Node<K,V> e;
33 if ((e = oldTab[j]) != null) {//注释3
34 oldTab[j] = null;
35 if (e.next == null) //注释4
36 newTab[e.hash & (newCap - 1)] = e;
37 else if (e instanceof TreeNode) //注释5
38 ((TreeNode<K,V>)e).split(this, newTab, j, oldCap);
39 else { // preserve order //注释6
40 Node<K,V> loHead = null, loTail = null; //注释7
41 Node<K,V> hiHead = null, hiTail = null;//注释8
42 Node<K,V> next;
43 do {
44 next = e.next;
45 if ((e.hash & oldCap) == 0) { //注释9
46 if (loTail == null) //注释10
47 loHead = e;
48 else
49 loTail.next = e;
50 loTail = e;
51 }
52 else {
53 if (hiTail == null)//注释11
54 hiHead = e;
55 else
56 hiTail.next = e;
57 hiTail = e;
58 }
59 } while ((e = next) != null);
60 if (loTail != null) { //注释12
61 loTail.next = null;
62 newTab[j] = loHead;
63 }
64 if (hiTail != null) {//注释13
65 hiTail.next = null;
66 newTab[j + oldCap] = hiHead;
67 }
68 }
69 }
70 }
71 }
72 return newTab;
73 }
jdk1.8中hashmap的扩容resize的更多相关文章
- JDK1.7中HashMap死环问题及JDK1.8中对HashMap的优化源码详解
一.JDK1.7中HashMap扩容死锁问题 我们首先来看一下JDK1.7中put方法的源码 我们打开addEntry方法如下,它会判断数组当前容量是否已经超过的阈值,例如假设当前的数组容量是16,加 ...
- JDK1.8中HashMap实现
JDK1.8中的HashMap实现跟JDK1.7中的实现有很大差别.下面分析JDK1.8中的实现,主要看put和get方法. 构造方法的时候并没有初始化,而是在第一次put的时候初始化 putVal方 ...
- JDK1.7中HashMap底层实现原理
一.数据结构 HashMap中的数据结构是数组+单链表的组合,以键值对(key-value)的形式存储元素的,通过put()和get()方法储存和获取对象. (方块表示Entry对象,横排表示数组ta ...
- JDK1.8中HashMap的hash算法和寻址算法
JDK 1.8 中 HashMap 的 hash 算法和寻址算法 HashMap 源码 hash() 方法 static final int hash(Object key) { int h; ret ...
- jdk1.8 HashMap的扩容resize()方法详解
/** * Initializes or doubles table size. If null, allocates in * accord with initial capacity target ...
- jdk1.7中hashmap扩容时不会产生死循环
在扩容时 transfer( ) 方法中 newTable 新数组 局部变量 table 旧数组 全局变量 当第一个链表进行while循环时 执行到 e.next = newTable[i]; 时 n ...
- 关于JDK1.7+中HashMap对红黑树场景的思考
背景 在1.7之前的版本,当数组元素较多(几百.几千,或者更多)的时候,在这种前提扩容,涉及全量元素的遍历和坐标的重新定位,这个耗时会比较长.这是之前存在的一个弊端吧.那么引入红黑树之后就解决了问题, ...
- hashMap在jdk1.7与jdk1.8中的原理及不同
在分析jdk1.7中HashMap的hash冲突时,不知大家是否有个疑问就是万一发生碰撞的节点非常多怎么版?如果说成百上千个节点在hash时发生碰撞,存储一个链表中,那么如果要查找其中一个节点,那就不 ...
- JDK1.8 中的HashMap
HashMap本质上Java中的一种数据结构,他是由数组+链表的形式组织而成的,当然了在jdk1.8后,当链表长度大于8的时候为了快速寻址,将链表修改成了红黑树. 既然本质上是一个数组,那我们 ...
随机推荐
- overflow原理?
overflow: hidden能清除块内子元素的浮动影响. 因为该属性进行超出隐藏时需要计算盒子内所有元素的高度, 所以会隐式清除浮动 创建BFC条件(满足一个): float的值不为none: o ...
- 是否可以继承String类?
String 类是final类,不可以被继承. 补充:继承String本身就是一个错误的行为,对String类型最好的重用方式是关联关系(Has-A)和依赖关系(Use-A)而不是继承关系(Is-A) ...
- Redis的Jedis操作(五)
需要把jedis依赖的jar包添加到工程中.Maven工程中需要把jedis的坐标添加到依赖. 推荐添加到服务层. 1.连接单机版 第一步:创建一个Jedis对象.需要指定服务端的ip及端口. 第二步 ...
- 学习saltstack (七)
一.SaltStack概述 Salt,,一种全新的基础设施管理方式,部署轻松,在几分钟内可运行起来,扩展性好,很容易管理上万台服务器,速度够快,服务器之间秒级通讯. salt底层采用动态的连接总线, ...
- java后端使用token处理表单重复提交
保证接口幂等性,表单重复提交 前台解决方案:提交后按钮禁用.置灰.页面出现遮罩后台解决方案: 使用token,每个token只能使用一次1.在调用接口之前生成对应的Token,存放至redis 2 ...
- 图灵机器人 V1 和 V2 接入方法
API1.0使用方法: import requests import json import yuyinhecheng as hc def Tuling(words): Tuling_API_ ...
- Python - 字符串基础知识
- 深入理解FIFO(包含有FIFO深度的解释)
FIFO: 一.先入先出队列(First Input First Output,FIFO)这是一种传统的按序执行方法,先进入的指令先完成并引退,跟着才执行第二条指令. 1.什么是FIFO? FIFO是 ...
- Logistic 回归模型的参数估计为什么不能采用最小二乘法?
logistic回归模型的参数估计问题,是可以用最小二乘方法的思想进行求解的,但和经典的(或者说用在经典线性回归的参数估计问题)最小二乘法不同,是用的是"迭代重加权最小二乘法"(I ...
- java中接口和抽象类有什么区别,举例!
2)接口和抽象类有什么区别?答:马克-to-win:抽象类里可以有实现的方法,接口里不能有,所以相对来讲各方面实现都简单(尤其动态方法调度).另外:类可以实现多个接口.反过来说,也正是抽象类一个致命伤 ...