hashMap在jdk1.7与jdk1.8中的原理及不同
在分析jdk1.7中HashMap的hash冲突时,不知大家是否有个疑问就是万一发生碰撞的节点非常多怎么版?如果说成百上千个节点在hash时发生碰撞,存储一个链表中,那么如果要查找其中一个节点,那就不可避免的花费O(N)的查找时间,这将是多么大的性能损失。这个问题终于在JDK1.8中得到了解决,在最坏的情况下,链表查找的时间复杂度为O(n),而红黑树一直是O(logn),这样会提高HashMap的效率。
jdk1.7中HashMap采用的是位桶+链表的方式,即我们常说的散列链表的方式,而jdk1.8中采用的是位桶+链表/红黑树的方式,也是非线程安全的。当某个位桶的链表的长度达到某个阀值的时候,这个链表就将转换成红黑树。
jdk1.8中,当同一个hash值的节点数不小于8时,将不再以单链表的形式存储了,会被调整成一颗红黑树(上图中null节点没画)。这就是jdk1.7与jdk1.8中HashMap实现的最大区别。
hashMap为何采用hash表存数据。如果不用hash表,集合中数据是无序的,当我们向集合中添加一个数据时需要同集合中所有的数据进行equals比较,当集合数据比较大时效率是非常的低。因此用hash表存储数据效率非常高。hash表的底层是数组,数组中存的是entry对象,默认长度是16.
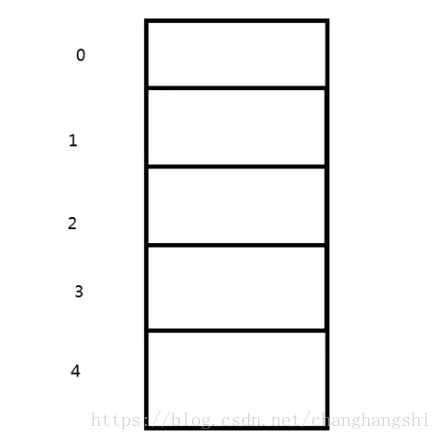
当我们往hash表中添加一个对象时,会调用对象的hash code方法,根据hash算法算出对应的数组的索引值,再根据索引值查找数组,数组中是否存在对象,如果不存在对象直接存进去。
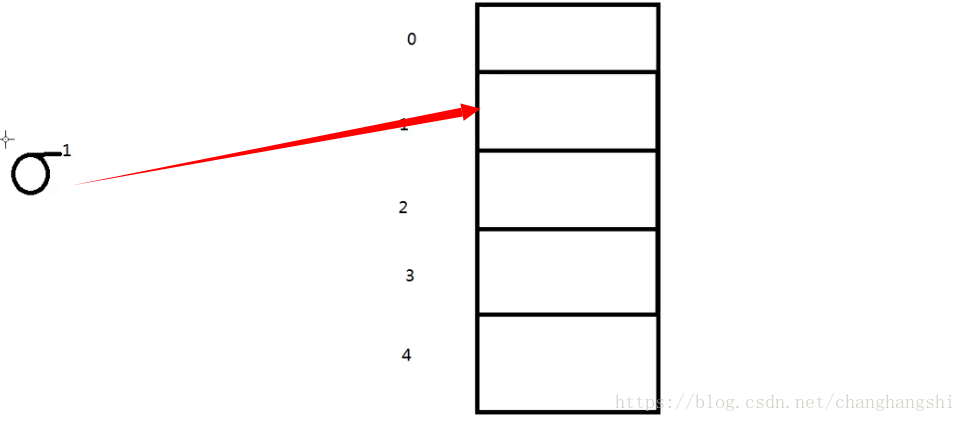
如果存在对象,则通过equals比较两个对象的key值是否相等,如果相等则覆盖value值。
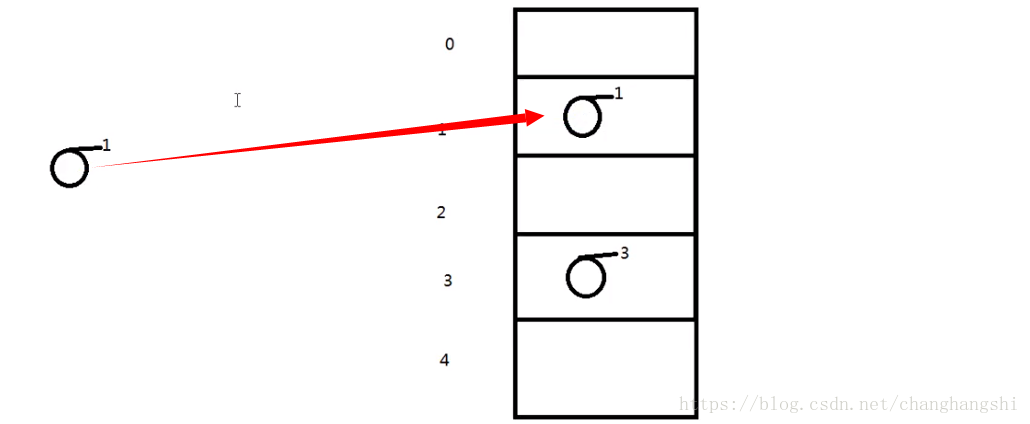
如果不相等则形成链表结构,jdk1.7后加的在前面,先加的移下,这种情况叫碰撞。这种碰撞的情况应尽量避免,否存一个索引中链表的数据大量时,该索引当再次插入一个对象时equals比较全部影响效率。这时我们将equals和hashcode方法重写的严谨点,这种还是避免不了,因为数组的索引值有限。因此hashMap提供了加载因子避免碰撞,默认0.75,当元素到达现有的hash表的75%时扩容。一旦扩充就会重新排序hash表,减少碰撞概率。
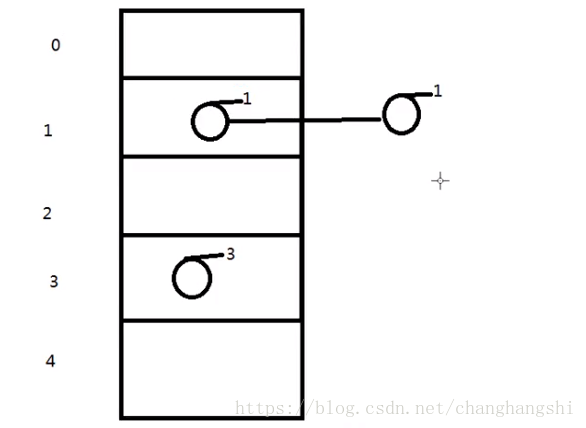
但是这两种方法还是避免不了这种碰撞的情况,就会出现查询一个对象可能出现极端情况查询链表的最后一个数据返回,影响查询效率。
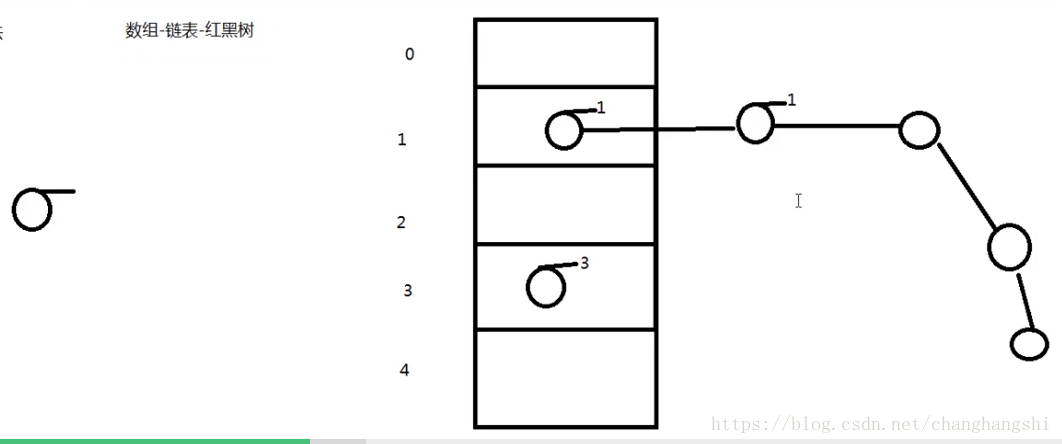
因此jdk1.8改善这种碰撞情况的出现,jdk1.8中的HashMap存储结构是由数组、链表、红黑树这三种数据结构形成,红黑树查询删除快新增慢。存储结构下图所示,根据key的hash与table长度确定table位置,同一个位置的key以链表形式存储,超过一定限制链表转为树。数组的具体存取规则是tab[(n-1) & hash],其中tab为node数组,n为数组的长度,hash为key的hash值。
1)表中数据的临界值,如果达到8,就进行resize扩展,如果数组大于64则转换为树.
static final int TREEIFY_THRESHOLD = 8;
2)如果数组的size大于64,则把链表进行转化为树
static final int MIN_TREEIFY_CAPACITY = 64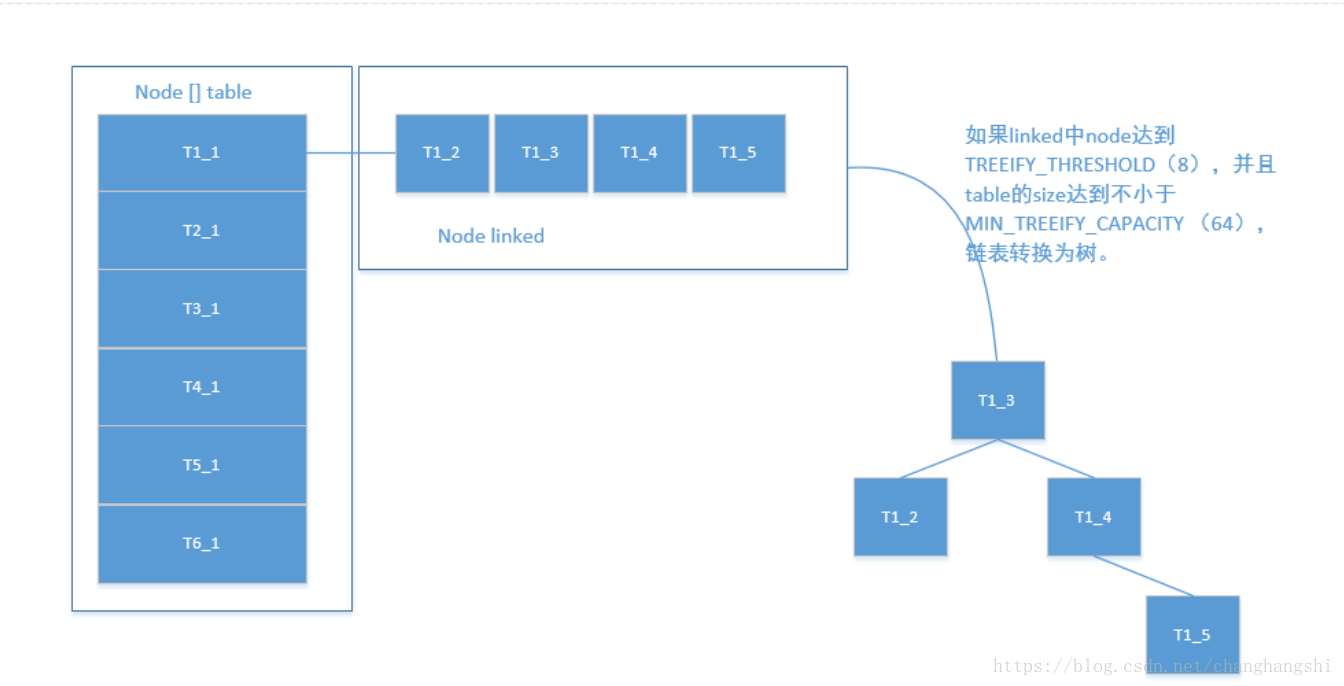
hashMap在jdk1.7与jdk1.8中的原理及不同的更多相关文章
- 【不做标题党,只做纯干货】HashMap在jdk1.7和1.8中的实现
同步首发:http://www.yuanrengu.com/index.php/20181106.html Java集合类的源码是深入学习Java非常好的素材,源码里很多优雅的写法和思路,会让人叹为 ...
- JDK1.7中HashMap死环问题及JDK1.8中对HashMap的优化源码详解
一.JDK1.7中HashMap扩容死锁问题 我们首先来看一下JDK1.7中put方法的源码 我们打开addEntry方法如下,它会判断数组当前容量是否已经超过的阈值,例如假设当前的数组容量是16,加 ...
- 牛客网Java刷题知识点之HashMap的实现原理、HashMap的存储结构、HashMap在JDK1.6、JDK1.7、JDK1.8之间的差异以及带来的性能影响
不多说,直接上干货! 福利 => 每天都推送 欢迎大家,关注微信扫码并加入我的4个微信公众号: 大数据躺过的坑 Java从入门到架构师 人工智能躺过的坑 ...
- HashMap 源码分析 基于jdk1.8分析
HashMap 源码分析 基于jdk1.8分析 1:数据结构: transient Node<K,V>[] table; //这里维护了一个 Node的数组结构: 下面看看Node的数 ...
- HashMap实现详解 基于JDK1.8
HashMap实现详解 基于JDK1.8 1.数据结构 散列表:是一种根据关键码值(Key value)而直接进行访问的数据结构.采用链地址法处理冲突. HashMap采用Node<K,V> ...
- Openfire3.9.1+jdk1.7导入到eclipse中
Openfire3.9.1+jdk1.7导入到eclipse中 写这篇文章,也是记录一下自己几晚上的辛苦,因为作为新手在网上看了很多的资料,但是按照他们的我总是出不来,跟他们描述的不一致,可能是环境问 ...
- 记一次诡异的bug调试——————关于JDK1.7和JDK1.8中HashSet的hash(key)算法的区别
现象: 测试提了一个bug,我完全复现不了,但是最吊诡的是在其他人的机器上都可以复现.起初以为是SVN合并后出现的冲突,后来经过对比法排查: step 1: 我本地开两个jetty,一个跑合并之前的版 ...
- HashMap 在 Java1.7 与 1.8 中的区别
hashMap 数据结构 如上图所示,JDK7之前hashmap又叫散列链表:基于一个数组以及多个链表的实现,hash值冲突的时候,就将对应节点以链表的形式存储. JDK8中,当同一个hash值(Ta ...
- HashMap在Java1.7与1.8中的区别
基于JDK1.7.0_80与JDK1.8.0_66做的分析 JDK1.7中 使用一个Entry数组来存储数据,用key的hashcode取模来决定key会被放到数组里的位置,如果hashcode相同, ...
随机推荐
- 萌新计划 PartⅠ
Part Ⅰ web1-7 题目总体代码框架如下,其中过滤内容不同,大体上通过构造出id=1000类似的语句进行绕过,得到flag <?php # 包含数据库连接文件 include(" ...
- 微服务架构中的BFF到底是啥?
在<技术中台与业务中台都是啥玩意>一文中留下一个问题:BFF是啥?为啥在API网关和业务中台之间加入了一层BFF?考虑到在实际工作中,我的大部分同事都问过这个问题,这里我也总结一下进行答复 ...
- 数据可视化之powerBI基础(十一)Power BI中的数据如何导出到Excel中?
https://zhuanlan.zhihu.com/p/64415543 把Excel中数据加载到PowerBI中我们都已经熟悉了,但是怎么把在PowerBI中处理好的数据导出到Excel中呢?毕竟 ...
- 机器学习实战基础(十九):sklearn中数据集
sklearn提供的自带的数据集 sklearn 的数据集有好多个种 自带的小数据集(packaged dataset):sklearn.datasets.load_<name> 可在 ...
- 访问控制列表与SSH结合使用,为网络设备保驾护航,提高安全性
通过之前的文章简单介绍了华为交换机如何配置SSH远程登录,在一些工作场景,需要特定的IP地址段能够SSH远程访问和管理网络设备,这样又需要怎么配置呢?下面通过一个简单的案例带着大家去了解一下. 要实现 ...
- scratch编程我的世界3D史蒂夫
这个程序我们只能制作出一个3D模型而已,并不是真正的我的世界整个游戏: 效果很炫酷吧!现在我们就来看看是怎样编程的吧! 首先,这个模型是有无数个平面克隆体摞在一起,旋转后会产生一种立体的错觉,是不是有 ...
- 图灵学院笔记-java虚拟机底层原理
Table of Contents generated with DocToc 一.java虚拟机概述 二.栈内存解析 2.1 概述 2.2 栈帧内部结构 2.2.1 我们来解析一下compute() ...
- 字符编码笔记:ASCII,Unicode 和 UTF-8个人理解
一.ASCII 码 我们知道,计算机内部,所有信息最终都是一个二进制值.每一个二进制位(bit)有0和1两种状态,因此八个二进制位(字节(Byte )是计算机信息技术用于计量存储容量的一种计量单位,作 ...
- java实现单链表的增删改以及排序
使用java代码模拟单链表的增删改以及排序功能 代码如下: package com.seizedays.linked_list; public class SingleLinkedListDemo { ...
- 06 . ELK Stack + kafka集群
简介 Filebeat用于收集本地文件的日志数据. 它作为服务器上的代理安装,Filebeat监视日志目录或特定的日志文件,尾部文件,并将它们转发到Elasticsearch或Logstash进行索引 ...