Clickhouse中的预聚合引擎
作者: LemonNan
原文地址: https://mp.weixin.qq.com/s/qXlmGTr4C1NjodXeM4V9pA
注: 转载需注明作者及原文地址
介绍
本文将介绍 Clickhouse 中的 SummingMergeTree 以及 AggregatingMergeTree 预聚合引擎,它们均继承自 MergeTree ,属于 MergeTree 引擎家族,关于 MergeTree 还没有看过的朋友可以先看一下之前的文章:[MergeTree 索引原理],这里就只讨论这两个引擎的使用。
SummingMergeTree
SummingMergeTree 引擎会在数据插入后,定期进行合并,Clickhouse 会将同一个分区内相同主键的数据会合并成一行,如果同时存在多个分区,则非常可能存在多行相同主键的数据,所以在进行查询的时候,需要使用 sum() 以及 group by 进行聚合。一个主键如果对应非常多的数据行,使用 SummingMergeTree 能 非常有效的减少数据存储所占用的空间(仅有预聚合引擎表的情况)以及加快聚合查询。
合并规则
- 默认为除主键外所有的数值类型字段合并求和,列的集合参数由表定义时
SummingMergeTree([columns])的column 决定,column 字段不允许出现在主键中以及必须为数值类型,如果建表时没有指定 column ,则默认为除主键外所有的数值类型字段 - 如果合并时所有列中的数据都为0,该主键行数据将会被删除
- 如果列不在主键中,且不在汇总字段中,则从现有的列中随机选一个值
- 不会合并位于主键中的字段
举个
这里拿一个用户的购买记录作为例子,包含字段有:时间、用户id、价格、物品id
数据建表
# 建表sql
create database if not exists test;
create table if not exists test.shopping_record(
`shop_time` DateTime64(3, 'UTC') COMMENT '购买时间',
`user_id` String COMMENT '用户id',
`price` Decimal(6,2) COMMENT '购买价格',
`product_id` String COMMENT '物品id'
) ENGINE = SummingMergeTree(price)
partition by toYYYYMM(shop_time)
order by (toYYYYMMDD(shop_time), user_id)
插入数据
# 用户1购买记录
insert into shopping_record values ('2022-02-23 16:43:33.000','user_1',70,'product_1'),('2022-02-23 16:43:22.000','user_1',20.33,'product_1'),('2022-02-23 17:43:44.000','user_1',433.99,'product_1'),('2022-03-10 18:43:55.000','user_1',76.23,'product_1'),('2022-03-11 19:43:15.000','user_1',99,'product_1'),('2022-03-10 20:43:32.000','user_1',37,'product_1');
这里查看数据,可以看到引擎已经预先聚合了一部分数据
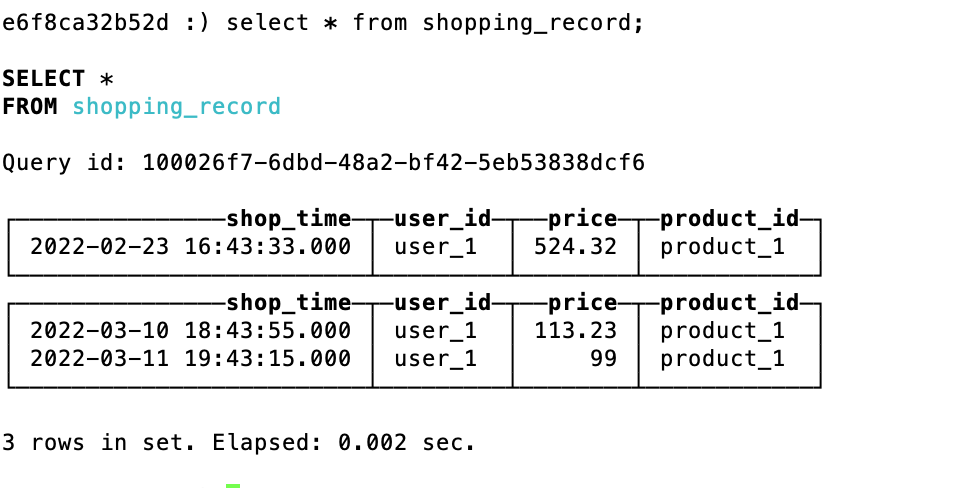
手动合并
执行完手动合并后,再次进行数据的查询,如果数据有合并的话,相同主键的数据会合并进行price求和,由于数据量过小导致查询时结果已经聚合,所以这里多次插入上面的 user_1 的数据
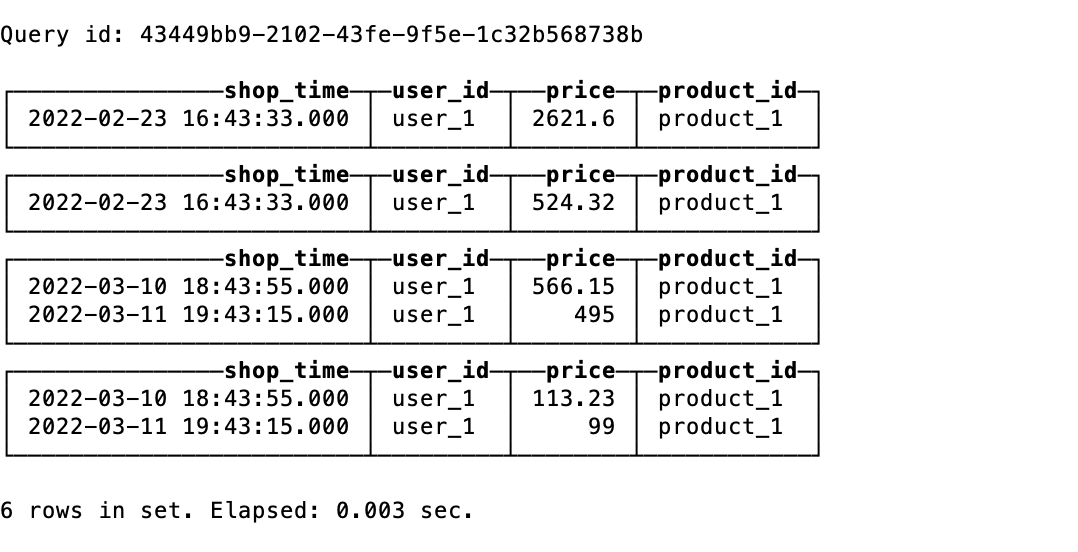
手动合并数据
# 手动合并数据
optimize table shopping_record final;
合并后查询结果

这里展示的是该引擎的自动聚合效果,但是在实际查询的时候,还需要对查询进行 sum 以及 group by,一部分原因是由于数据可能还没来得及聚合,还有一部分原因是数据可能于多个分区中,此时需要对多个分区进行聚合
-- 由于建表时主键为 toYYYYMMDD(shopping_time),所以这里根据日期来统计
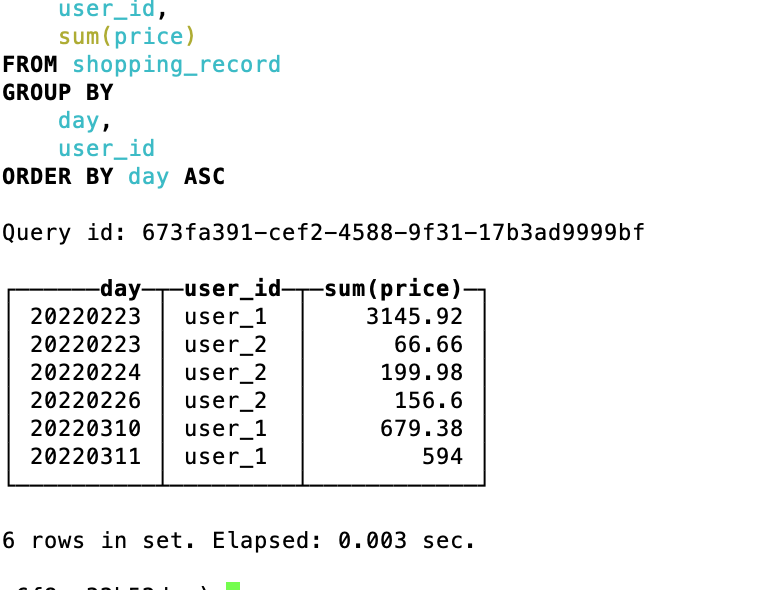
select toYYYYMMDD(shop_time) as day, user_id, sum(price) from shopping_record group by day, user_id order by day
下面是查询结果
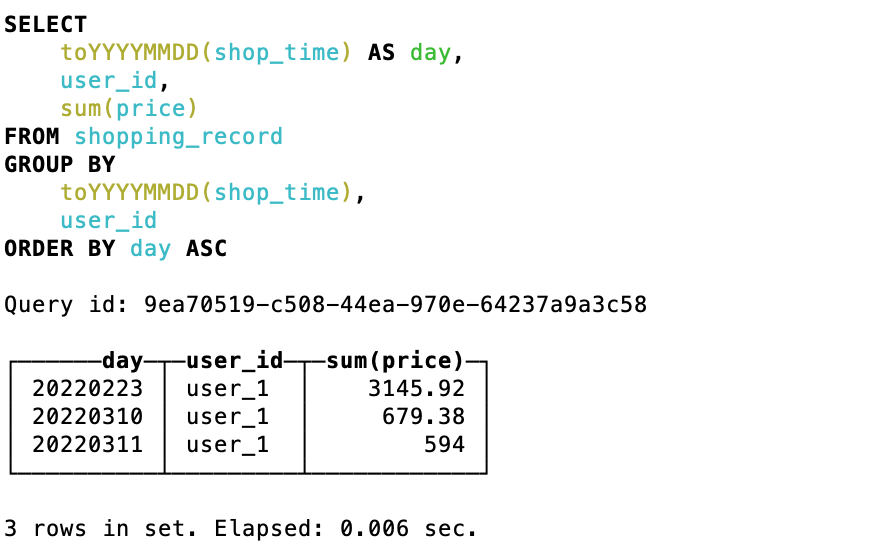
新数据插入
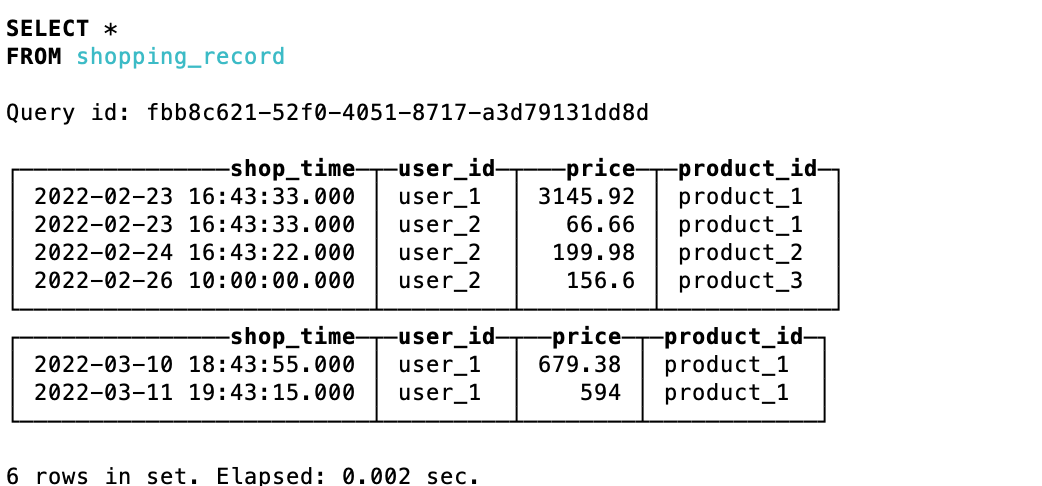
这里再增加用户2的购买记录
# 用户2购买记录,这里模拟的时候插入了2次
insert into shopping_record values ('2022-02-23 16:43:33.000','user_2',33.33,'product_1'),('2022-02-24 16:43:22.000','user_2',99.99,'product_2'),('2022-02-26 10:00:00.000','user_2',78.3,'product_3');
执行手动合并sql后进行查询
可以看到数据根据日期以及用户进行了预聚合
AggregatingMergeTree
AggregatingMergeTree 也是预聚合引擎的一种,跟 SummingMergeTree 不同的是 AggregatingMergeTree 可以指定各种聚合函数,而 SummingMergeTree 只能处理数值求和 的情况。
在使用 AggregatingMergeTree 存储的时候需要使用 state 结尾函数 存储中间状态值
查询的时候使用 merge 结尾函数处理 state 的中间状态值
照样举个
这里拿 “电商平台的书本访问次数以及访问时长” 作为例子
数据建表
# 书本的查看记录
create table if not exists test.book(
`user_id` String COMMENT '用户id',
`book_id` String COMMENT '书本id',
`view_time` Int32 COMMENT '页面查看时间,单位秒',
`create_time` DateTime64(3, 'UTC') COMMENT '创建时间'
) ENGINE = MergeTree()
partition by toYYYYMM(create_time)
order by (create_time, book_id)
# 书本浏览记录的预聚合 AggregatingMergeTree, 这里使用的是物化视图,物化视图很多操作跟普通表相同
CREATE MATERIALIZED VIEW IF NOT EXISTS test.book_mv
engine = AggregatingMergeTree()
partition by day
order by (day, book_id)
as select toYYYYMMDD(create_time) as day,
book_id as book_id,
count() as visit,
sumState(view_time) as sum_view_time
from test.book
group by day, book_id
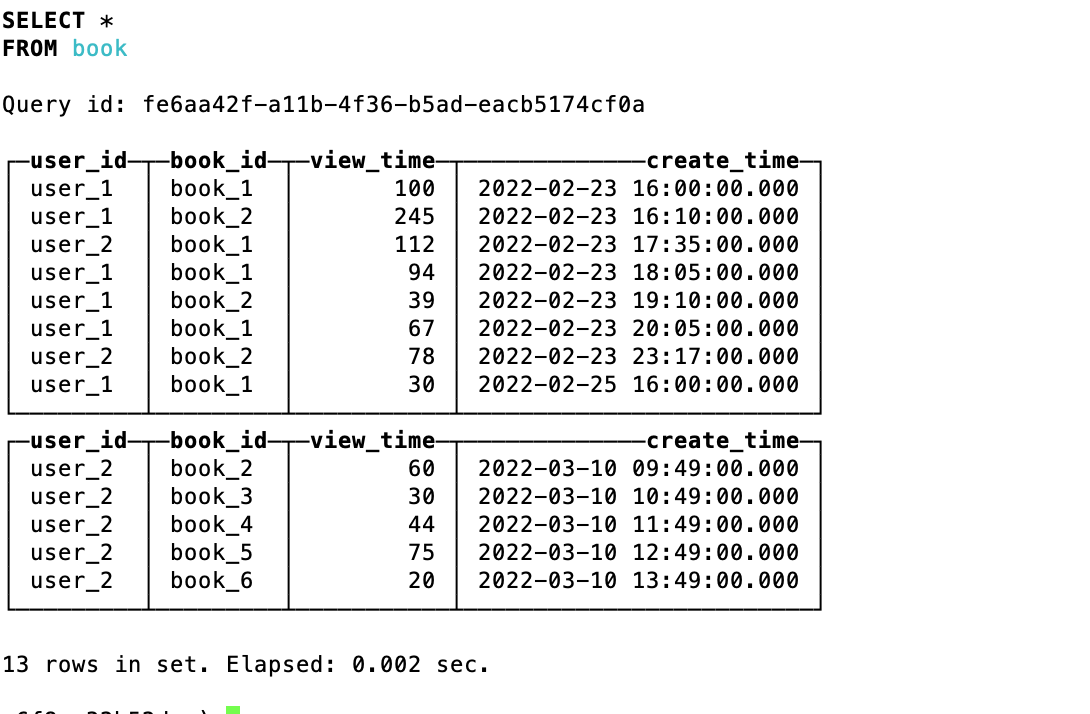
插入数据
insert into test.book values
('user_1', 'book_1', 100, '2022-02-23 16:00:00'),
('user_2', 'book_1', 112, '2022-02-23 17:35:00'),
('user_1', 'book_1', 94, '2022-02-23 18:05:00'),
('user_1', 'book_1', 67, '2022-02-23 20:05:00'),
('user_1', 'book_1', 30, '2022-02-25 16:00:00'),
('user_1', 'book_2', 245, '2022-02-23 16:10:00'),
('user_1', 'book_2', 39, '2022-02-23 19:10:00'),
('user_2', 'book_2', 78, '2022-02-23 23:17:00'),
('user_2', 'book_2', 60, '2022-03-10 09:49:00'),
('user_2', 'book_3', 30, '2022-03-10 10:49:00'),
('user_2', 'book_4', 44, '2022-03-10 11:49:00'),
('user_2', 'book_5', 75, '2022-03-10 12:49:00'),
('user_2', 'book_6', 20, '2022-03-10 13:49:00');
结果查询
查询原始数据表
# 因为这里是物化视图使用的预聚合引擎,所以查预询预聚合结果的话要查物化视图
select day, book_id, sum(visit), sumMerge(sum_view_time) as view_time from book_mv group by day, book_id order by day, book_id;
预聚合结果如下图

从图里可以看到,预聚合引擎将原始浏览记录聚合成了所需信息,每天每本书的浏览次数、每天每本书总的页面浏览时间
总结
使用聚合引擎在某些统计的情况下,可以很好的节省存储空间(单预聚合引擎表情况下)以及加快数据聚合查找,但是通常会包含两张表, MergeTree 的原始数据表以及包含预聚合引擎的数据表,两张表的情况下是需要 拿空间换时间,上面的话就是物化视图持久化预聚合结果,除原始表外占用额外空间,但是查询预聚合引擎表可以加快聚合查询。
最后
欢迎扫描下方二维码或搜索公众号 LemonCode , 一起交流学习!

Clickhouse中的预聚合引擎的更多相关文章
- 转!!MySQL中的存储引擎讲解(InnoDB,MyISAM,Memory等各存储引擎对比)
MySQL中的存储引擎: 1.存储引擎的概念 2.查看MySQL所支持的存储引擎 3.MySQL中几种常用存储引擎的特点 4.存储引擎之间的相互转化 一.存储引擎: 1.存储引擎其实就是如何实现存储数 ...
- 实例介绍Cocos2d-x中Box2D物理引擎:HelloBox2D
我们通过一个实例介绍一下,在Cocos2d-x 3.x中使用Box2D物理引擎的开发过程,熟悉这些API的使用.这个实例运行后的场景如图所示,当场景启动后,玩家可以触摸点击屏幕,每次触摸时候,就会在触 ...
- 在QT中使用Irrlicht引擎的方法与步骤
Ø 相关库,插件安装部分 本篇文档介绍在Qt5.2.0下面使用lrrlicht引擎在Qt窗口中输出(开发环境:vs2012) 1. 首先安装好Qt5.2.0,下载地址: http://downlo ...
- Express ( MiddleWare/中间件 路由 在 Express 中使用模板引擎 常用API
A fast, un-opinionated, minimalist web framework for Node.js applications. In general, prefer simply ...
- MySql中innodb存储引擎事务日志详解
分析下MySql中innodb存储引擎是如何通过日志来实现事务的? Mysql会最大程度的使用缓存机制来提高数据库的访问效率,但是万一数据库发生断电,因为缓存的数据没有写入磁盘,导致缓存在内存中的数据 ...
- Gtk-WARNING**:无法在模块路径中找到主题引擎:“pixmap”的解决
Gtk-WARNING**:无法在模块路径中找到主题引擎:“pixmap”的解决 解决以上问题, 只需要安装 gnome-themes-standard 即可 如果终端中提示: (gvim:23 ...
- docker swarm英文文档学习-5-在swarm模式中运行Docker引擎
Run Docker Engine in swarm mode在swarm模式中运行Docker引擎 当你第一次安装并开始使用Docker引擎时,默认情况下禁用swarm模式.在启用集群模式时,需要处 ...
- MYSQL中的BlackHole引擎
MYSQL中的BlackHole引擎 http://blog.csdn.net/ylspirit/article/details/7234021 http://blog.chinaunix.net/u ...
- 纸壳CMS3.0中的规则引擎,表达式计算
纸壳CMS3.0中的规则引擎,用于计算通用表达试结果.通常业务逻辑总是复杂多变的,使用这个规则引擎可以灵活的修改计算表达式. IRuleManager IRuleManager,是使用规则引擎的主要接 ...
随机推荐
- js中全局变量和局部变量以及变量声明提升
javascript中全局变量和局部变量的区别 转载前端小99 发布于2018-04-23 15:31:35 阅读数 2102 收藏 展开 [javascript] view plain copy ...
- IntelliJ IDEA 官方网站 http://www.jetbrains.com/idea/
IntelliJ IDEA 官方网站 http://www.jetbrains.com/idea/
- IDEA:修改JAVA文件自动引入import.*包
感谢大佬:https://blog.csdn.net/fly910905/article/details/90208744 问题描述 Intellij Idea工具在java文件中,经常会自动导入im ...
- iOS,蓝牙开发!!--By帮雷
iOS的蓝牙开发大致有以下几种方式. 1 GameKit.framework [只能存在于iOS设备之间,多用于游戏 能搜索到的demo比较多,不确切说名字了,code4app里面就有] 2 Core ...
- [翻译]Introduction to JSON Web Tokens
JWT: Json Web Tokens JWT是一种开放标准(RFC 7519),它定义了一种紧凑且独立的方式,用于将各方之间的信息安全地传输为JSON对象.因为它是经过数字签名的,所以该信息可以进 ...
- requests实现接口测试
python+requests实现接口测试 - get与post请求基本使用方法 http://www.cnblogs.com/nizhihong/p/6567928.html Requests ...
- 多图|一文详解Nacos参数!
Nacos 中的参数有很多,如:命名空间.分组名.服务名.保护阈值.服务路由类型.临时实例等,那这些参数都是什么意思?又该如何设置?接下来我们一起来盘它. 1.命名空间 在 Nacos 中通过命名空间 ...
- C#控制树莓派入门
何为树莓派 许久没有写博客了,十二月份西安疫情的影响,居家隔离了一个多月,在其期间,学习了一下树莓派,觉得硬件还是挺有意思的,刚好也看到了巨硬有提供使用c#用来开发树莓派应用的解决方案叫Net Iot ...
- Web渗透测试入门之SQL注入(上篇)
题记: 本来今天想把白天刷的攻防世界Web进阶的做个总结,结果估计服务器抽疯环境老报错,然后想了下今天用到了SQL注入,文件上传等等,写写心得.相信很多朋友都一直想学好渗透,然后看到各种入门视频,入门 ...
- css文字超出指定行数显示省略号
display: -webkit-box; overflow: hidden; word-break: break-all; /* break-all(允许在单词内换行.) */ text-overf ...