【学习笔记】注意力机制(Attention)
前言
这一章看啥视频都不好使,啃书就完事儿了,当然了我也没有感觉自己学的特别扎实,不过好歹是有一定的了解了
注意力机制
由于之前的卷积之类的神经网络,选取卷积中最大的那个数,实际上这种行为是没有目的的,因为你不知道那个最大的数是不是你需要的,也许在哪一块你偏偏就需要一个最小的数呢?所以就有了注意了机制。
用X来表示N组输入信息,D是X的维度,Xn表示一组输入信息。为了节省计算资源不需要把所有信息都输入神经网络,只需要从X中选择一些和任务相关的信息。注意力机制的计算可以分为两步:一是在所有输入信息上计算注意力分布,二是根据注意力分布来计算输入信息的加权平均
注意力分布 为了从N个向量里面选出某个特定任务相关的信息,我们需要引入一个和任务相关的表示,称为查询向量,并通过一个打分函数来计算每个输入向量和查询向量之间的相关性
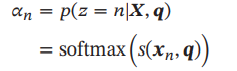
这里的q就是查询向量,X是输入,α称为注意力分布,S则是注意力打分函数,打分函数可以用以下方法计算
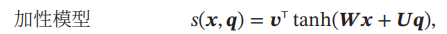
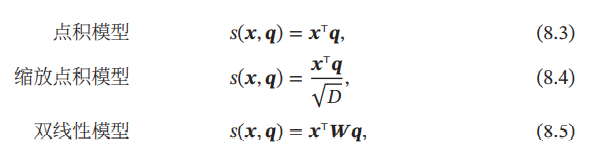
其中, , 为可学习的参数, 为输入向量的维度
- 软性注意力
加权平均:注意力分布 可以解释为在给定任务相关的查询 时,第 个输入向量受关注的程度.我们采用一种“软性”的信息选择机制对输入信息进行汇总
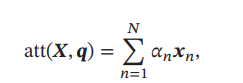
- 硬性注意力
而与软性注意力对应则有硬性注意力,本来在下一节出现,但是为了笔记连贯性,我就直接在这里记了。
软性注意力其选择的信息是所有输入向量在注意力分布下的期望.此外,还有一种注意力是只关注某一个输入向量,叫作硬性注意力,硬性注意力有两种实现方式:一种是选取最高概率的一个输入向量,另一种硬性注意力可以通过在注意力分布式上随机采样的方式实现,硬性注意力的一个缺点是基于最大采样或随机采样的方式来选择信息,使得最终的损失函数与注意力分布之间的函数关系不可导,无法使用反向传播算法进行训练.因此,硬性注意力通常需要使用强化学习来进行训练.为了使用反向传播算法,一般使用软性注意力来代替硬性注意力。
注意力机制的变体
键值对注意力我们可以用键值对(key-value pair)格式来表示输入信息,其中“键”用来计算注意力分布,“值”用来计算聚合信息
可以将注意力机制看做是一种软寻址操作:把输入信息X看做是存储器中存储的内容,元素由地址Key(键)和值Value组成,当前有个Key=Query的查询,目标是取出存储器中对应的Value值,即Attention值。而在软寻址中,并非需要硬性满足Key=Query的条件来取出存储信息,而是通过计算Query与存储器内元素的地址Key的相似度来决定,从对应的元素Value中取出多少内容。每个地址Key对应的Value值都会被抽取内容出来,然后求和,这就相当于由Query与Key的相似性来计算每个Value值的权重,然后对Value值进行加权求和。加权求和得到最终的Value值,也就是Attention值。
这里的理解感谢CSDN的博客: https://blog.csdn.net/weixin_42398658/article/details/90804173
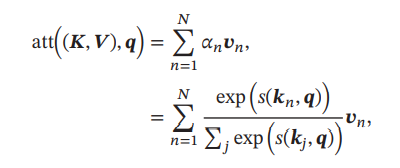
这里V指的就是值
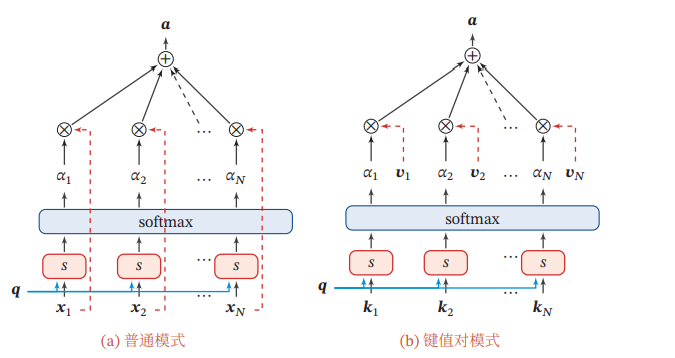
这里两张图可以看出区别,普通的机制就是把x和q一起算s再输出α作为注意力分布,在计算x应该输入多少,而键值对是原来的输入x使用键值对格式,包含一个k和一个v,计算得时候把K和q作为输入来计算s,再把求出的α和数据里面的v进行输出
多头注意力
多头注意力(Multi-Head Attention)是利用多个查询 = [1, ⋯ , ],来并行地从输入信息中选取多组信息.每个注意力关注输入信息的不同部分.
结构化注意力
在之前介绍中,我们假设所有的输入信息是同等重要的,是一种扁平(Flat)结构,注意力分布实际上是在所有输入信息上的多项分布.但如果输入信息本身具有层次(Hierarchical)结构,比如文本可以分为词、句子、段落、篇章等不同粒度的层次,我们可以使用层次化的注意力来进行更好的信息选择 .此外,还可以假设注意力为上下文相关的二项分布,用一种图模型来构建更复杂的结构化注意力分布
指针网络
注意力机制主要是用来做信息筛选,从输入信息中选取相关的信息.注意力机制可以分为两步:一是计算注意力分布 ,二是根据 来计算输入信息的加权平均.我们可以只利用注意力机制中的第一步,将注意力分布作为一个软性的指针(pointer)来指出相关信息的位置.
自注意力模型
上文中出现的键值对注意力,其实就是为了自注意力模型的学习做准备,看到这里才算有了一个系统的了解。
感谢CSDN这篇文章对我的理解帮助 https://blog.csdn.net/qq_38890412/article/details/120601834
以利用注意力机制来“动态”地生成不同连接的权重,这就是自注意力模型
加入一个注意力机制和自注意力机制的区别来帮助理解:简单的讲就是Attention机制中的权重的计算需要Target来参与的,即在Encoder-Decoder model中Attention权值的计算不仅需要Encoder中的隐状态而且还需要Decoder 中的隐状态。而Self Attention顾名思义,指的不是Target和Source之间的Attention机制,而是Source内部元素之间或者Target内部元素之间发生的Attention机制,也可以理解为Target=Source这种特殊情况下的注意力计算机制。
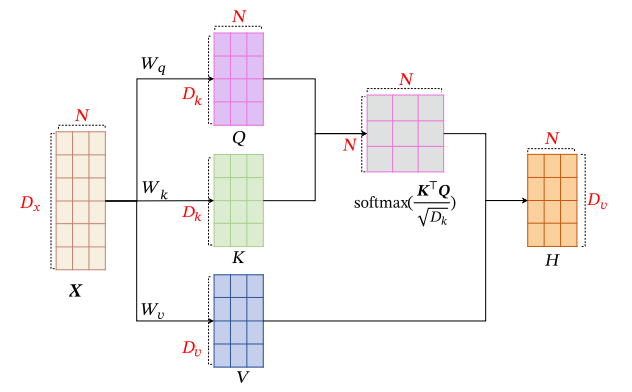
原本计算相关度只需要X和X的转置做内积即可,但是为了提高拟合度,对X做了一些变换,这些QKV矩阵就是对于X的线性变化用来增高拟合性,而QKV的内容都可以学习训练得出
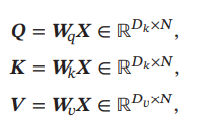
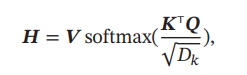
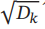 的作用是让梯度值保持稳定
的作用是让梯度值保持稳定
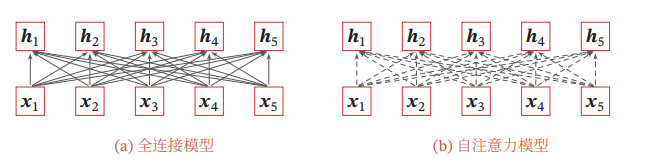
给出全连接模型和自注意力模型的对比,其中实线表示可学习的权重,虚线表示动态生成的权重.由于自注意力模型的权重是动态生成的,因此可以处理变长的信息序列.
小结
这一章学完有一个很深的感悟,也不知道对不对
所谓的神经网络,无外乎就是通过权重筛选数据,只不过权重的计算方式和筛选策略不同,就起了不同的名字,也不知道这样理解对不对
【学习笔记】注意力机制(Attention)的更多相关文章
- 深度学习之注意力机制(Attention Mechanism)和Seq2Seq
这篇文章整理有关注意力机制(Attention Mechanism )的知识,主要涉及以下几点内容: 1.注意力机制是为了解决什么问题而提出来的? 2.软性注意力机制的数学原理: 3.软性注意力机制. ...
- 注意力机制---Attention、local Attention、self Attention、Hierarchical attention
一.编码-解码架构 目的:解决语音识别.机器翻译.知识问答等输出输入序列长度不相等的任务. C是输入的一个表达(representation),包含了输入序列的有效信息. 它可能是一个向量,也可能是一 ...
- 自然语言处理中注意力机制---Attention
使用Multi-head Self-Attention进行自动特征学习的CTR模型 https://blog.csdn.net/u012151283/article/details/85310370 ...
- 0032 Java学习笔记-类加载机制-初步
JVM虚拟机 Java虚拟机有自己完善的硬件架构(处理器.堆栈.寄存器等)和指令系统 Java虚拟机是一种能运行Java bytecode的虚拟机 JVM并非专属于Java语言,只要生成的编译文件能匹 ...
- springmvc学习笔记--Interceptor机制和实践
前言: Spring的AOP理念, 以及j2ee中责任链(过滤器链)的设计模式, 确实深入人心, 处处可以看到它的身影. 这次借项目空闲, 来总结一下SpringMVC的Interceptor机制, ...
- IOS开发学习笔记014-ARC机制
ARC 1.ARC机制 2.ARC 判断准则 3.注意事项 4.ARC和非ARC混合使用 ARC机制 ARC 是编译器特性,而不是 iOS 运行时特性,它也不是类似于其它语言中的垃圾收集器.因此 AR ...
- JAVA 学习笔记 - 反射机制
1. JAVA反射机制的概念 2. 怎样实例化一个 Class对象 Class.forName(包名.类名); 对象.getClass(); 类.class; ================== ...
- Java学习笔记-反射机制
Java反射机制实在运行状态时,对于任意一个类,都能够知道这个类的属性和方法,对于任意一个对象,都能够调用他的任意一个属性和方法 获取Class对象的三种方式 Object类中的getClass()方 ...
- Java学习笔记--异常机制
简介 在实际的程序运行过程中,用户并不一定完全按照程序员的所写的逻辑去执行程序,例如写的某个模块,要求输入数字,而用户却在键盘上输入字符串:要求打开某个文件,但是文件不存在或者格式不对:或者程序运行时 ...
- 12.swoole学习笔记--锁机制
<?php //创建锁对象 $lock=new swoole_lock(SWOOLE_MUTEX);//互斥锁 echo "创建互斥锁\n"; //开始锁定 主进程 $loc ...
随机推荐
- Detecting Rumors from Microblogs with Recurrent Neural Networks(IJCAI-16)
记录一下,很久之前看的论文-基于RNN来从微博中检测谣言及其代码复现. 1 引言 现有传统谣言检测模型使用经典的机器学习算法,这些算法利用了根据帖子的内容.用户特征和扩散模式手工制作的各种特征,或者简 ...
- 匿名对象作为方法的参数和返回值与Random概念和基本使用
应用场景 1. 创建匿名对象直接调用方法,没有变量名. new Scanner(System.in).nextInt(); 2. 一旦调用两次方法,就是创建了两个对象,造成浪费,请看如下代码. new ...
- Redis 渐进集群介绍
redis 凭借着强大的功能和可靠的稳定性,应用场景越来越广.逐渐成为软件开发工程师必备的技能之一. 本篇文章,暂不做基本功能的介绍.直接教大家如何部署redis集群. 集群演进主要分为2部分. 一. ...
- 01 开发App真机调试问题
逍遥安卓模拟器 :https://juejin.cn/post/7062922018710093831 HBuilderX真机调试插上手机却提示"未检测到手机或浏览器"的问题:ht ...
- element多重校验报please transfer a valid prop path to form item
- springmvc源码笔记-HandlerMapping注入
在springmvc中,如何根据url找到controller以及对应方法,依赖的是HandlerMapping接口的getHandler方法 在spring容器中默认注册的HandlerMappin ...
- 题解【AtCoder - CODE FESTIVAL 2017 qual B - D - 101 to 010】
题目:https://atcoder.jp/contests/code-festival-2017-qualb/tasks/code_festival_2017_qualb_d 题意:给一个 01 串 ...
- 设计模式(一)----设计模式概述及UML图解析
1.设计模式概述 1.1 软件设计模式的产生背景 "设计模式"最初并不是出现在软件设计中,而是被用于建筑领域的设计中. 1977年美国著名建筑大师.加利福尼亚大学伯克利分校环境结构 ...
- 【Go实战基础】GO语言是什么,有哪些优势
一.简介 2007年,为了提高在多核.网络机器(networked machines).大型代码库(codebases)的业务场景下的开发效率,Google 首席软件工程师决定创造一种语言那就是 Go ...
- poi生成表格自动合并单元格
直接复制这个工具类即可使用: /** * 合并单元格 * @author tongyao * @param sheet sheet页 * @param titleColumn 标题占用行 * @par ...