【原创】Python 二手车之家车辆档案数据爬虫
| 本文仅供学习交流使用,如侵立删! |
二手车之家车辆档案数据爬虫
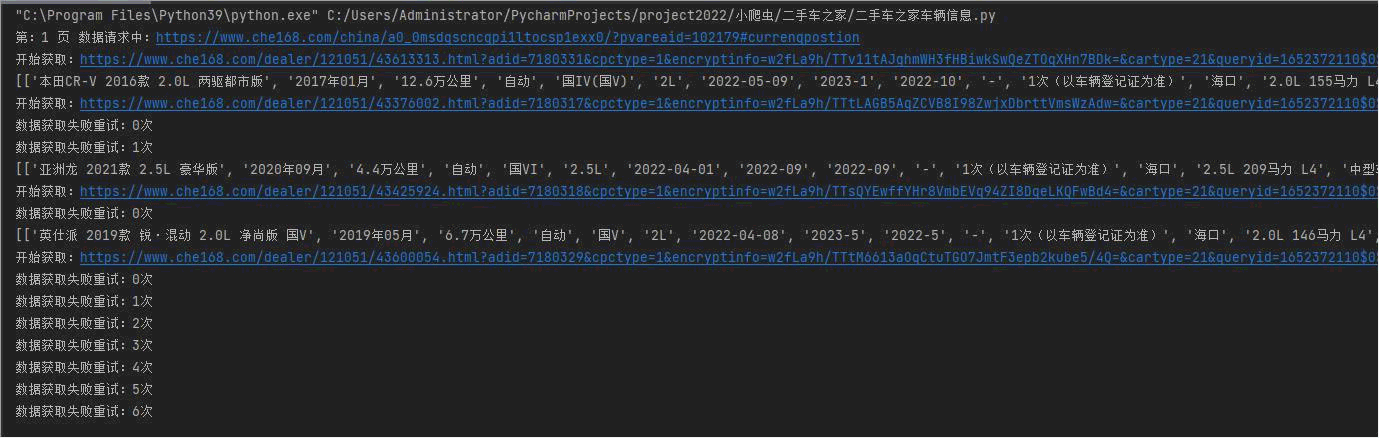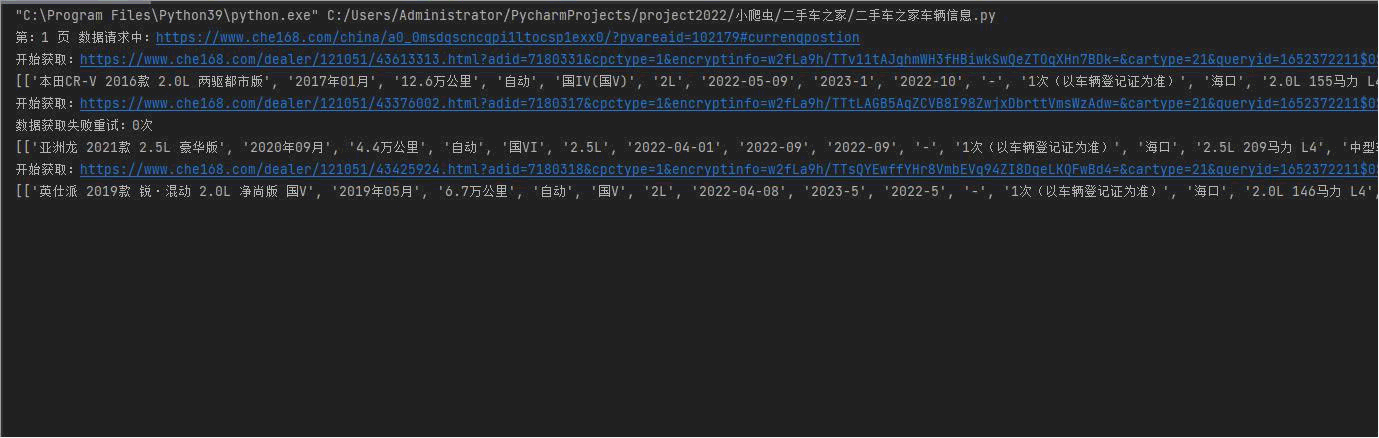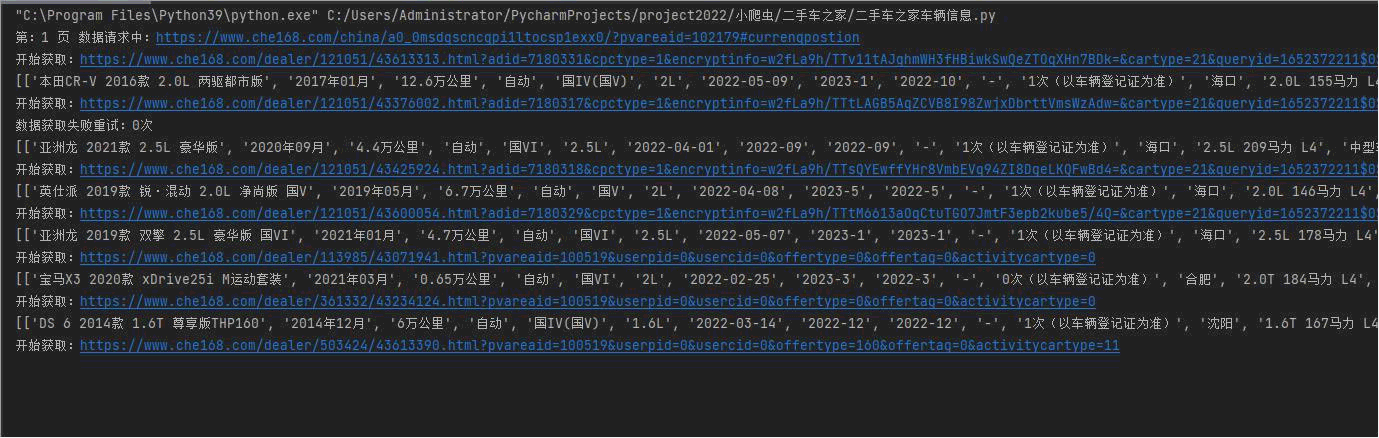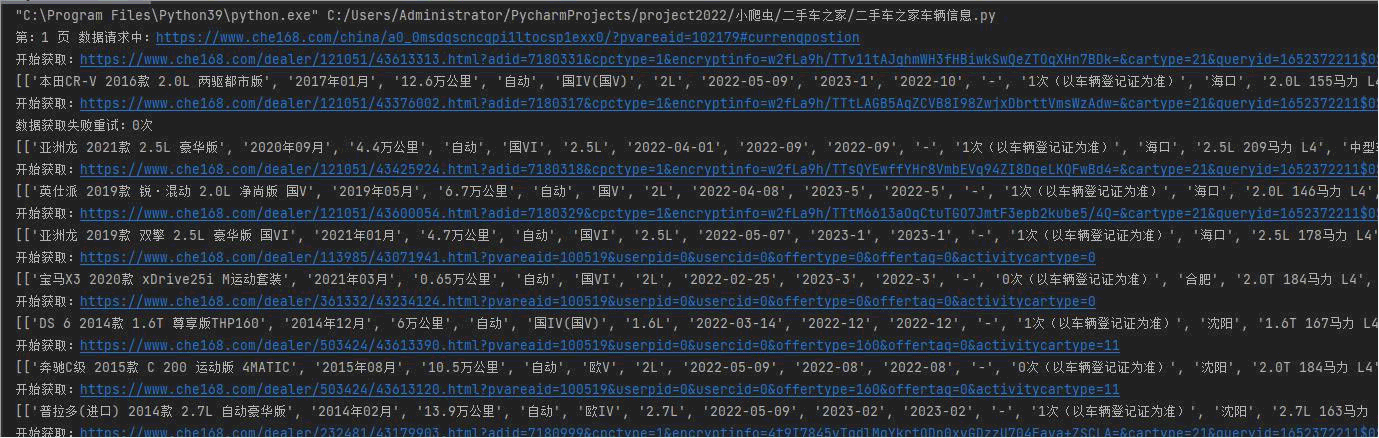
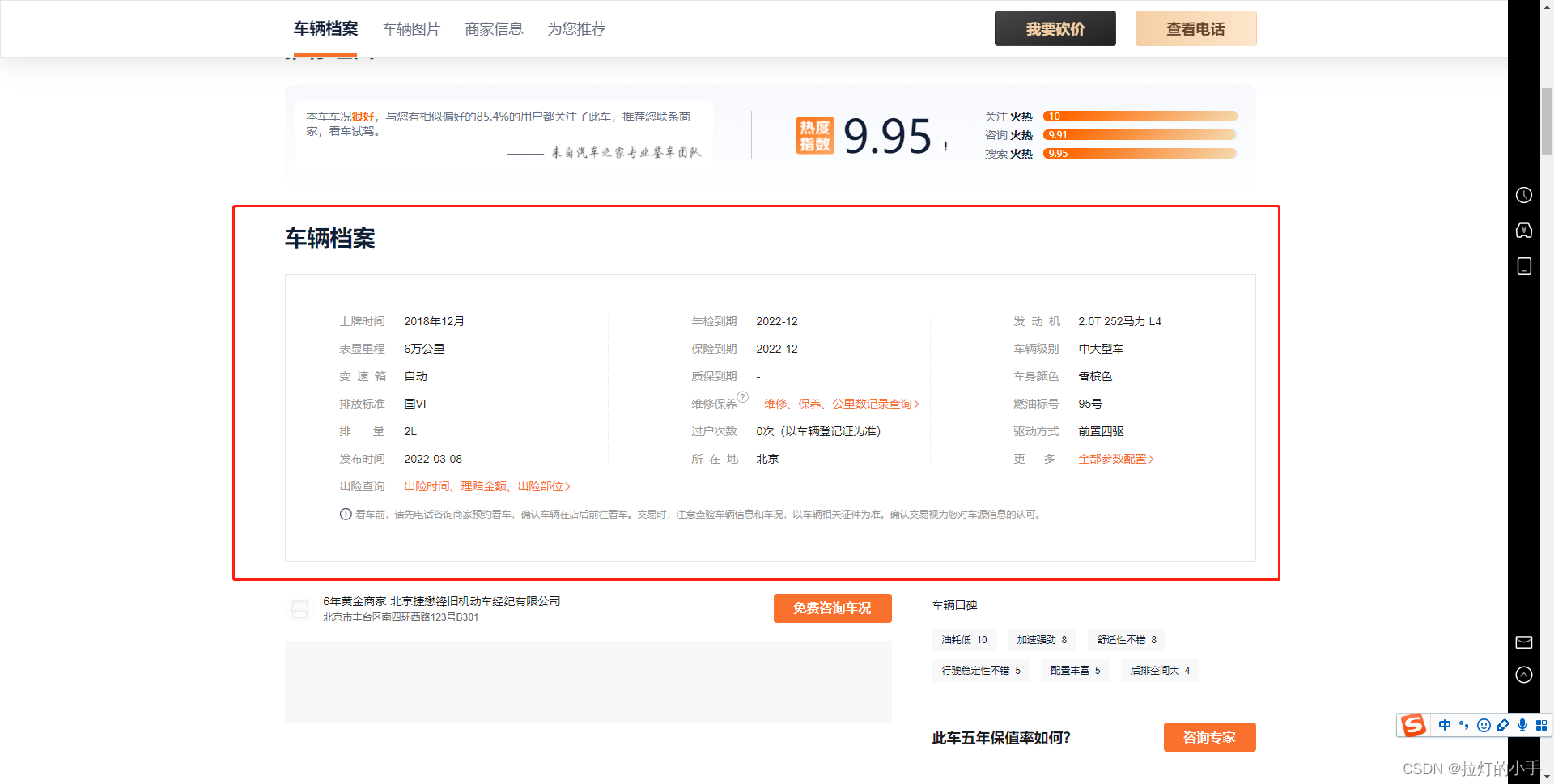
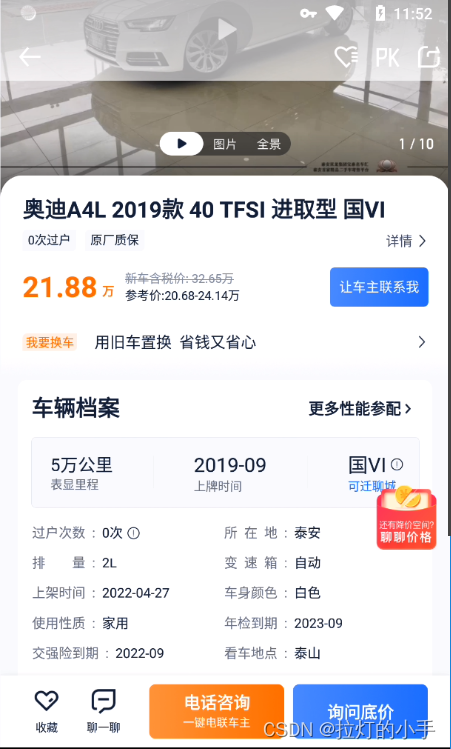
先上效果图

环境
- win10
- python3.9
- lxml、retrying、requests
需求分析
需求:
主要是需要车辆详情页中车辆档案的数据
先抓包分析一波,网页抓包没有什么有用的,转战APP
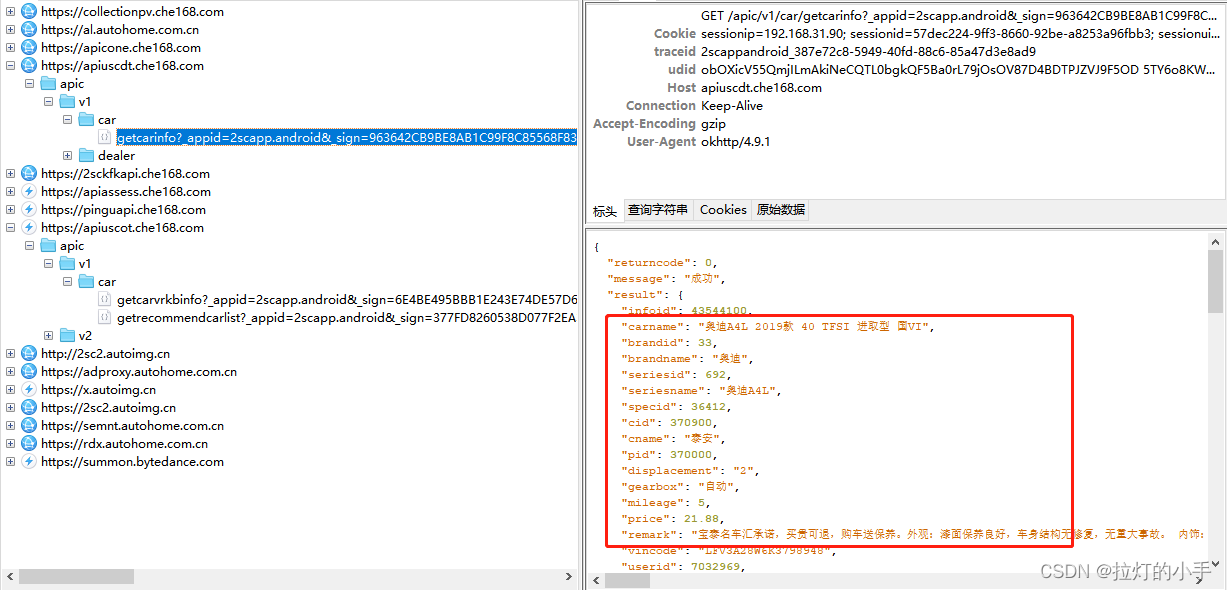
拿到数据接口就简单了,直接构造请求保存数据即可
获取车辆信息列表
def _get_car_list(self, _url: str):
"""
获取二手车信息列表
"""
res = self._parse_url(_url=_url)
ret = res.text # 解析获得字符串类型数据
result = etree.HTML(ret) # 转换数据类型为HTML,方便使用xpath
url_list = result.xpath('//*[@id="goodStartSolrQuotePriceCore0"]/ul/li/a/@href')
if not url_list:
print('获取完成!')
return
for i in url_list:
# 有些车型url直接是带域名的
if 'www.che168.com/' in i:
yield 'https://' + i[2:]
else:
yield 'https://www.che168.com' + i
获取车辆详情信息
def _get_car_info(self, _url: str):
"""
获取车辆详情信息
"""
res = self._parse_url(_url=_url)
ret = res.text # 解析获得字符串类型数据
result = etree.HTML(ret) # 转换数据类型为HTML,方便使用xpath
# 标题
title = result.xpath('//div[@class="car-box"]/h3//text()')
title = title[1].strip() if len(title) > 1 else title[0].strip()
# 上牌时间
play_time = result.xpath('//*[@id="nav1"]/div[1]/ul[1]/li[1]/text()')
play_time = play_time[0].strip() if play_time else '-'
# 表显里程
display_mileage = result.xpath('//*[@id="nav1"]/div[1]/ul[1]/li[2]/text()')
display_mileage = display_mileage[0].strip() if display_mileage else '-'
# 变速箱
gearbox = result.xpath('//*[@id="nav1"]/div[1]/ul[1]/li[3]/text()')
gearbox = gearbox[0].strip() if gearbox else '-'
# 排放标准
emission_standards = result.xpath('//*[@id="nav1"]/div[1]/ul[1]/li[4]/text()')
emission_standards = emission_standards[0].strip() if emission_standards else '-'
# 排量
displacement = result.xpath('//*[@id="nav1"]/div[1]/ul[1]/li[5]/text()')
displacement = displacement[0].strip() if displacement else '-'
# 发布时间
release_time = result.xpath('//*[@id="nav1"]/div[1]/ul[1]/li[6]/text()')
release_time = release_time[0].strip() if release_time else '-'
# 年检到期
annual_inspection_expires = result.xpath('//*[@id="nav1"]/div[1]/ul[2]/li[1]/text()')
annual_inspection_expires = annual_inspection_expires[0].strip() if annual_inspection_expires else '-'
# 保险到期
insurance_expires = result.xpath('//*[@id="nav1"]/div[1]/ul[2]/li[2]/text()')
insurance_expires = insurance_expires[0].strip() if insurance_expires else '-'
# 质保到期
warranty_expires = result.xpath('//*[@id="nav1"]/div[1]/ul[2]/li[3]/text()')
warranty_expires = warranty_expires[0].strip() if warranty_expires else '-'
# 过户次数
number_of_transfers = result.xpath('//*[@id="nav1"]/div[1]/ul[2]/li[5]/text()')
number_of_transfers = number_of_transfers[0].strip() if number_of_transfers else '-'
# 所在地
location = result.xpath('//*[@id="nav1"]/div[1]/ul[2]/li[6]/text()')
location = location[0].strip() if location else '-'
# 发动机
engine = result.xpath('//*[@id="nav1"]/div[1]/ul[3]/li[1]/text()')
engine = engine[0].strip() if engine else '-'
# 车辆级别
vehicle = result.xpath('//*[@id="nav1"]/div[1]/ul[3]/li[2]/text()')
vehicle = vehicle[0].strip() if vehicle else '-'
# 车身颜色
car_color = result.xpath('//*[@id="nav1"]/div[1]/ul[3]/li[3]/text()')
car_color = car_color[0].strip() if car_color else '-'
# 燃油标号
fuel_label = result.xpath('//*[@id="nav1"]/div[1]/ul[3]/li[4]/text()')
fuel_label = fuel_label[0].strip() if fuel_label else '-'
# 驱动方式
drive_mode = result.xpath('//*[@id="nav1"]/div[1]/ul[3]/li[5]/text()')
drive_mode = drive_mode[0].strip() if drive_mode else '-'
data = [[title, play_time, display_mileage, gearbox, emission_standards, displacement, release_time, annual_inspection_expires,
insurance_expires, warranty_expires, number_of_transfers, location, engine, vehicle, car_color, fuel_label, drive_mode, _url]]
print(data)
self._save_csv(data=data)
资源下载
https://download.csdn.net/download/qq_38154948/85358088
| 本文仅供学习交流使用,如侵立删! |
【原创】Python 二手车之家车辆档案数据爬虫的更多相关文章
- selenuim自动化爬取汽车在线谷米爱车网车辆GPS数据爬虫
#为了实时获取车辆信息,以及为了后面进行行使轨迹绘图,写了一个基于selelnium的爬虫爬取了车辆gps数据. #在这里发现selenium可以很好的实现网页解析和处理js处理 #导包 import ...
- Python爬取6271家死亡公司数据,一眼看尽十年创业公司消亡史!
小五利用python将其中的死亡公司数据爬取下来,借此来观察最近十年创业公司消亡史. 获取数据 F12,Network查看异步请求XHR,翻页. 成功找到返回json格式数据的url, 很多人 ...
- Python爬取6271家死亡公司数据,看十年创业公司消亡史
前言 文的文字及图片来源于网络,仅供学习.交流使用,不具有任何商业用途,版权归原作者所有,如有问题请及时联系我们以作处理. 作者: 朱小五 凹凸玩数据 PS:如有需要Python学习资料的小伙伴可以加 ...
- TOP100summit:【分享实录】链家网大数据平台体系构建历程
本篇文章内容来自2016年TOP100summit 链家网大数据部资深研发架构师李小龙的案例分享. 编辑:Cynthia 李小龙:链家网大数据部资深研发架构师,负责大数据工具平台化相关的工作.专注于数 ...
- python3 爬取汽车之家所有车型数据操作步骤(更新版)
题记: 互联网上关于使用python3去爬取汽车之家的汽车数据(主要是汽车基本参数,配置参数,颜色参数,内饰参数)的教程已经非常多了,但大体的方案分两种: 1.解析出汽车之家某个车型的网页,然后正则表 ...
- 利用Python进行数据分析(12) pandas基础: 数据合并
pandas 提供了三种主要方法可以对数据进行合并: pandas.merge()方法:数据库风格的合并: pandas.concat()方法:轴向连接,即沿着一条轴将多个对象堆叠到一起: 实例方法c ...
- 使用 Python 抓取欧洲足球联赛数据
Web Scraping在大数据时代,一切都要用数据来说话,大数据处理的过程一般需要经过以下的几个步骤 数据的采集和获取 数据的清洗,抽取,变形和装载 数据的分析,探索和预测 ...
- 如何用python抓取js生成的数据 - SegmentFault
如何用python抓取js生成的数据 - SegmentFault 如何用python抓取js生成的数据 1赞 踩 收藏 想写一个爬虫,但是需要抓去的的数据是js生成的,在源代码里看不到,要怎么才能抓 ...
- [原创].NET 分布式架构开发实战之三 数据访问深入一点的思考
原文:[原创].NET 分布式架构开发实战之三 数据访问深入一点的思考 .NET 分布式架构开发实战之三 数据访问深入一点的思考 前言:首先,感谢园子里的朋友对文章的支持,感谢大家,希望本系列的文章能 ...
随机推荐
- 用了Scrum越来越累?这三点帮你走出困境
摘要:你有没有一种感觉,团队用了Scrum之后,工作任务越来越多,加班越来越严重?有?好兄弟,这篇文章正好能帮你~ 本文分享自华为云社区<用了Scrum越来越累?这三点帮你走出困境>,作者 ...
- [C++STL] vector 容器的入门
vector容器的入门 #include<vector> 创建vector容器的几种方式 数据类型可以是结构体,也能是另外一个容器 vector 的初始化: (1) 创建并声明大小 vec ...
- Ubuntu 静默安装DEB包(非交互式)~解决Ubuntu下安装DEB包弹窗交互的问题
在Ubuntu环境下安装DEB包时,比如安装MySQL式经常会弹出交互式要输入密码的操作.有时候我们期望编写Shell脚本一键部署MySQL时不想要弹窗交互时,则可以使用以下方式实现自动化安装Deb软 ...
- 『忘了再学』Shell基础 — 21、变量的测试与内容置换
目录 1.什么是变量的测试与内容置换 2.变量的测试与内容置换 3.示例 例1: 例2: 例3: 1.什么是变量的测试与内容置换 我们之前说过,在Shell中,一个变量未定义,和一个变量为空值的输出效 ...
- 牛客多校赛2K Keyboard Free
Description 给定 \(3\) 个同心圆,半径分别为 \(r1,r2,r3\) ,三个点分别随机分布在三个圆上,求这个三角形期望下的面积. Solution 首先可以固定 \(A\) 点,枚 ...
- Redis分布式锁实现Redisson 15问
大家好,我是三友. 在一个分布式系统中,由于涉及到多个实例同时对同一个资源加锁的问题,像传统的synchronized.ReentrantLock等单进程情况加锁的api就不再适用,需要使用分布式锁来 ...
- java基础题(5)
6.常用API 6.1string类 1.动态字符串 描述 将一个由英文字母组成的字符串转换成从末尾开始每三个字母用逗号分隔的形式. 输入描述: 一个字符串 输出描述: 修改后的字符串 示例1 输入: ...
- ESXI系列问题整理以及记录——使用SSH为设备打VIB驱动包,同时提供一种对于ESXI不兼容螃蟹网卡(Realtek 瑞昱)的问题解决思路
对于ESXI不兼容螃蟹网卡的问题,这里建议购买一张博通的低端单口千兆网卡,先使用博通网卡完成系统部署,再按照下文方法添加螃蟹网卡的VIB驱动,最后拆除博通网卡. 螃蟹网卡VIB驱动包下载地址:http ...
- Java使用类-String
String,StringBuffer,StringBuild 大佬的理解-><深入理解Java中的String> 1.String 1.1 String 实例化 String st ...
- 从零开始实现lmax-Disruptor队列(三)多线程消费者WorkerPool原理解析
MyDisruptor V3版本介绍 在v2版本的MyDisruptor实现多消费者.消费者组间依赖功能后.按照计划,v3版本的MyDisruptor需要支持多线程消费者的功能. 由于该文属于系列博客 ...