scrapy抓取拉勾网职位信息(一)——scrapy初识及lagou爬虫项目建立
本次以scrapy抓取拉勾网职位信息作为scrapy学习的一个实战演练
python版本:3.7.1
框架:scrapy(pip直接安装可能会报错,如果是vc++环境不满足,建议直接安装一个visual studio一劳永逸,如果报错缺少前置依赖,就先安装依赖)
本篇主要对scrapy生成爬虫项目做一个基本的介绍
tips:在任意目录打开cmd的方式可以使用下面这两种方式
- shift + 右键打开cmd(window10的powershell你可以简单理解为cmd升级版)
- 在路径框直接输入cmd,回车
1、建立一个scrapy项目
在cmd窗口中输入:scrapy startproject lagou,这样就创建了一个项目文件夹,文件夹的名字是lagou

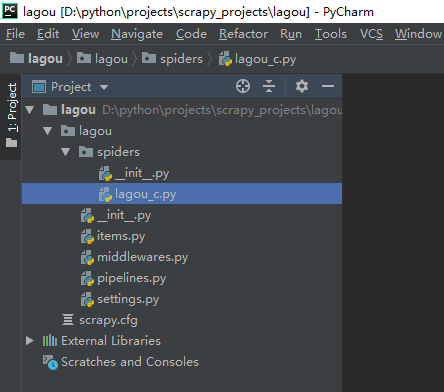
新生成一个scrapy项目,但是目前里面还没有一个爬虫,用pycharm打开外层lagou文件夹看看

从结构可以看出生成的lagou项目文件夹里面生成了一些新的文件夹和文件,
__init__.py:两个文件内容都是空的,存在的唯一目的就是让它所在的文件夹成为一个python包。
items.py:主要是用来定义要提取的字段的,比如我们要提取招聘职位的名称,薪酬,都需要对字段进行定义
middlewares.py:中间件,包括spider middleware和downloader middleware,前者可以对请求进行修改(比如加入代理,设置UA都可以在这里进行),后者可以对下载的页面进行修改
pipelines.py:主要是用来进行数据清洗,存储的
settings.py:爬虫项目的全局配置,比如全局的UA,是否开启middlewares中间键,设置延迟等
2、生成一个爬虫(注意:一个项目文件夹下面可以有多个爬虫)
首先进入到外层的lagou文件夹下
cd lagou
查看有哪些爬虫模板命令:scrapy genspider -l

一般用的比较多是basic和crawl两种,basic适合主页比较简单,url基本一致的情况,crawl适合有多种标签类别的网站
针对拉勾网,这里我们选用crawl模板生成爬虫,爬虫名称是lagou_c,爬取的首页url是lagou.com
scrapy genspider -t crawl lagou_c lagou.com (-t crawl代表以crawl模板生成爬虫,如果不加这个参数以basic模板生成的爬虫scrapy genspider lagou_c lagou.com)
注意:爬虫名称一般设置为要爬取的url名称,如lagou.com,设置为lagou为爬虫名,但爬虫名和项目名不能重复,我这里修改爬虫名为lagou_c

这样我们就建立了一个名称为lagou_c的爬虫项目,再次用pycharm打开可以看到多了一个lagou_c.py文件,这个文件就是爬虫的入口,它主要是用来产生新的请求和对返回的response进行解析。
scrapy抓取拉勾网职位信息(一)——scrapy初识及lagou爬虫项目建立的更多相关文章
- scrapy抓取拉勾网职位信息(三)——爬虫rules内容编写
在上篇中,分析了拉勾网需要跟进的页面url,本篇开始进行代码编写. 在编写代码前,需要对scrapy的数据流走向有一个大致的认识,如果不是很清楚的话建议先看下:scrapy数据流 本篇目标:让拉勾网爬 ...
- scrapy抓取拉勾网职位信息(四)——对字段进行提取
上一篇中已经分析了详情页的url规则,并且对items.py文件进行了编写,定义了我们需要提取的字段,本篇将具体的items字段提取出来 这里主要是涉及到选择器的一些用法,如果不是很熟,可以参考:sc ...
- scrapy抓取拉勾网职位信息(二)——拉勾网页面分析
网站结构分析: 四个大标签:首页.公司.校园.言职 我们最终是要得到详情页的信息,但是从首页的很多链接都能进入到一个详情页,我们需要对这些标签一个个分析,分析出哪些链接我们需要跟进. 首先是四个大标签 ...
- scrapy抓取拉勾网职位信息(八)——使用scrapyd对爬虫进行部署
上篇我们实现了分布式爬取,本篇来说下爬虫的部署. 分析:我们上节实现的分布式爬虫,需要把爬虫打包,上传到每个远程主机,然后解压后执行爬虫程序.这样做运行爬虫也可以,只不过如果以后爬虫有修改,需要重新修 ...
- scrapy抓取拉勾网职位信息(六)——反爬应对(随机UA,随机代理)
上篇已经对数据进行了清洗,本篇对反爬虫做一些应对措施,主要包括随机UserAgent.随机代理. 一.随机UA 分析:构建随机UA可以采用以下两种方法 我们可以选择很多UserAgent,形成一个列表 ...
- scrapy抓取拉勾网职位信息(七)——数据存储(MongoDB,Mysql,本地CSV)
上一篇完成了随机UA和随机代理的设置,让爬虫能更稳定的运行,本篇将爬取好的数据进行存储,包括本地文件,关系型数据库(以Mysql为例),非关系型数据库(以MongoDB为例). 实际上我们在编写爬虫r ...
- scrapy抓取拉勾网职位信息(七)——实现分布式
上篇我们实现了数据的存储,包括把数据存储到MongoDB,Mysql以及本地文件,本篇说下分布式. 我们目前实现的是一个单机爬虫,也就是只在一个机器上运行,想象一下,如果同时有多台机器同时运行这个爬虫 ...
- scrapy抓取拉勾网职位信息(五)——代码优化
上一篇我们已经让代码跑起来,各个字段也能在控制台输出,但是以item类字典的形式写的代码过于冗长,且有些字段出现的结果不统一,比如发布日期. 而且后续要把数据存到数据库,目前的字段基本都是string ...
- 【图文详解】scrapy爬虫与动态页面——爬取拉勾网职位信息(2)
上次挖了一个坑,今天终于填上了,还记得之前我们做的拉勾爬虫吗?那时我们实现了一页的爬取,今天让我们再接再厉,实现多页爬取,顺便实现职位和公司的关键词搜索功能. 之前的内容就不再介绍了,不熟悉的请一定要 ...
随机推荐
- SPOJ 104 HIGH - Highways
HIGH - Highways http://www.spoj.com/problems/HIGH/ In some countries building highways takes a lot o ...
- redhat 7 安装oracle12.1
https://oracle-base.com/articles/12c/oracle-db-12cr1-installation-on-oracle-linux-7 一定要配置yum本地源 ...
- Tomcat报错:Failed to start component [StandardEngine[Catalina].StandardHost[localhost].StandardContext[/JFreeChartTest]]
最好把项目移除,然后在tomcat的webapps发布路径下也把项目文件删掉,重新部署就好了,原因是可能在tomcat的remove覆盖中以前的文件有所保留导致冲突,亲测有效
- codechef September Challenge 2017 Fill The Matrix
这道题我们发现0就代表相同1代表少1或者大1 那么我们根据题目连边 如果存在1(边权只为或0)个数为奇数的环就是无解 #include<cstdio> #include<cstrin ...
- 【BZOJ】4147: [AMPPZ2014]Euclidean Nim
[算法]博弈论+数论 [题意]给定n个石子,两人轮流操作,规则如下: 轮到先手操作时:若石子数<p添加p个石子,否则拿走p的倍数个石子.记为属性p. 轮到后手操作时:若石子数<q添加q个石 ...
- Vuejs - 组件式开发
初识组件 组件(Component)绝对是 Vue 最强大的功能之一.它可以扩展HTML元素,封装可复用代码.从较高层面讲,可以理解组件为自定义的HTML元素,Vue 的编译器为它添加了特殊强大的功能 ...
- c语言目录操作总结
=================================================== char *getcwd( char *buffer, int maxlen ); (获取当前目 ...
- 极致的 Hybrid:航旅离线包再加速!(转)
资源离线的思路简单.场景复杂,最复杂的就是 H5 活动页面的离线化.Mobile Web 在弱网提速的唯一的办法就是坚决杜绝不必要的(运行时)网络请求,即除了 Json 格式的动态数据和其携带的商品配 ...
- Angular2.0 基础: User Input
1.Angular 2.0 中的变量 对输入值的获取,我们可以通过$event 来获取,也可以通过变量来获取. template: ` <input (keyup)="onKey($e ...
- 一个基于时间注入的perl小脚本
use strict; use warnings; use LWP::Simple; my %table_and_leng; ;;$count++){ #print "Test Table: ...