scrapy抓取拉勾网职位信息(二)——拉勾网页面分析

网站结构分析:
四个大标签:首页、公司、校园、言职
我们最终是要得到详情页的信息,但是从首页的很多链接都能进入到一个详情页,我们需要对这些标签一个个分析,分析出哪些链接我们需要跟进。
首先是四个大标签,鼠标点击进入后可以发现首页、公司、校园,这三个包含有招聘职位
1、首先是对首页的分析
首页正文部分包括:搜索栏(含热门搜索)、职业方向标签(java、php。。。)、热门职位、热门公司
搜索栏:搜索标签的岗位数量较少,我们要做全站数据爬取的话,不跟进这个标签
职业方向标签:这个标签指向的url都是lagou.com/zhaopin/.* (.*代表0个或多个任意字符)这种形式,岗位较全,需要跟进这些页面
热门职位:这个标签指向的url都是lagou.com/jobs/...这种形式,职业方向标签内详情页可能会有重复,同样不跟进
热门公司:这个标签指向的url都是lagou.com/gongsi/\d+这种形式,点进去后可以看到详情页都包含在lagou.com/gongsi/j.*这种链接中,但实际上这个与上方四个大标签的公司标签也是重复的,所以这些页面也不在首页跟进
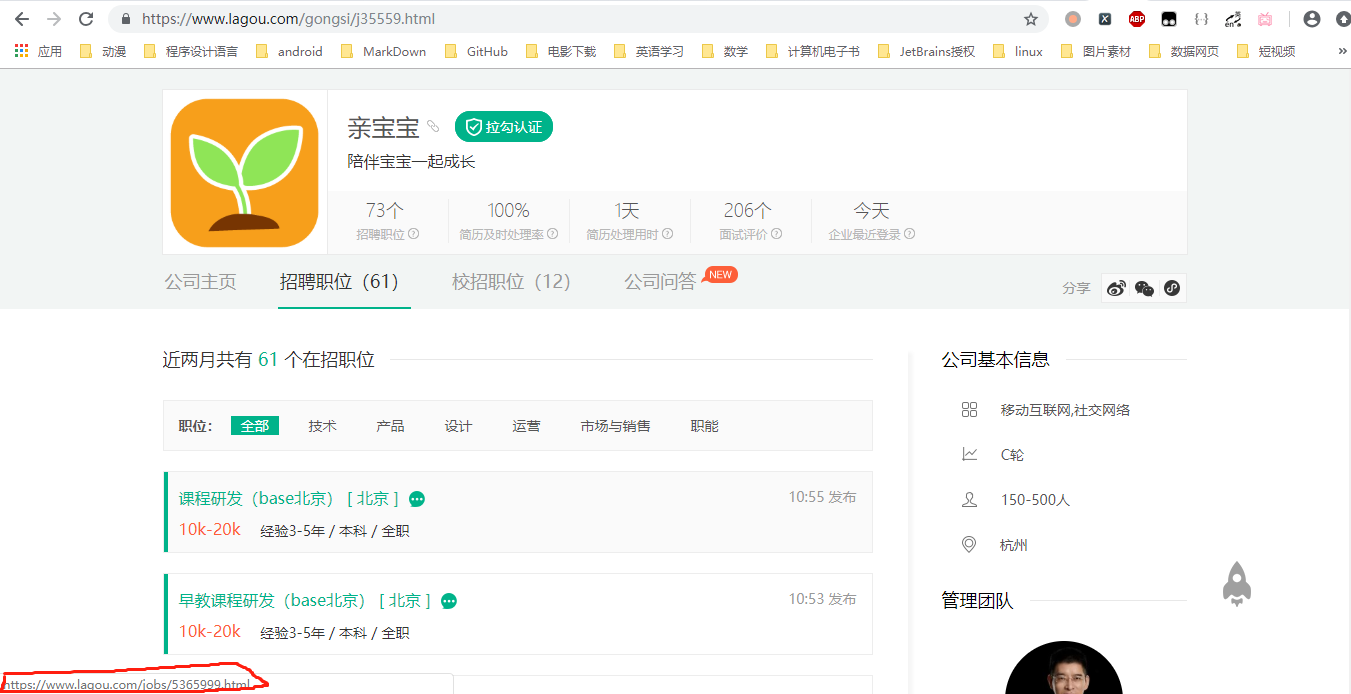
2、对大标签公司的分析
可以看到各个公司标签都包含在lagou.com/gongsi/这个链接下,每一个公司名类似lagou.com/gongsi/\d+.html(\d+代表一个或者多个数字)

进入其中一个公司页面,可以看到所有的招聘职位都在lagou.com/gongsi/j\d+.html这样的页面下(\d+代表一个或者多个数字),而岗位详情页类似lagou.com/jobs/\d+.html
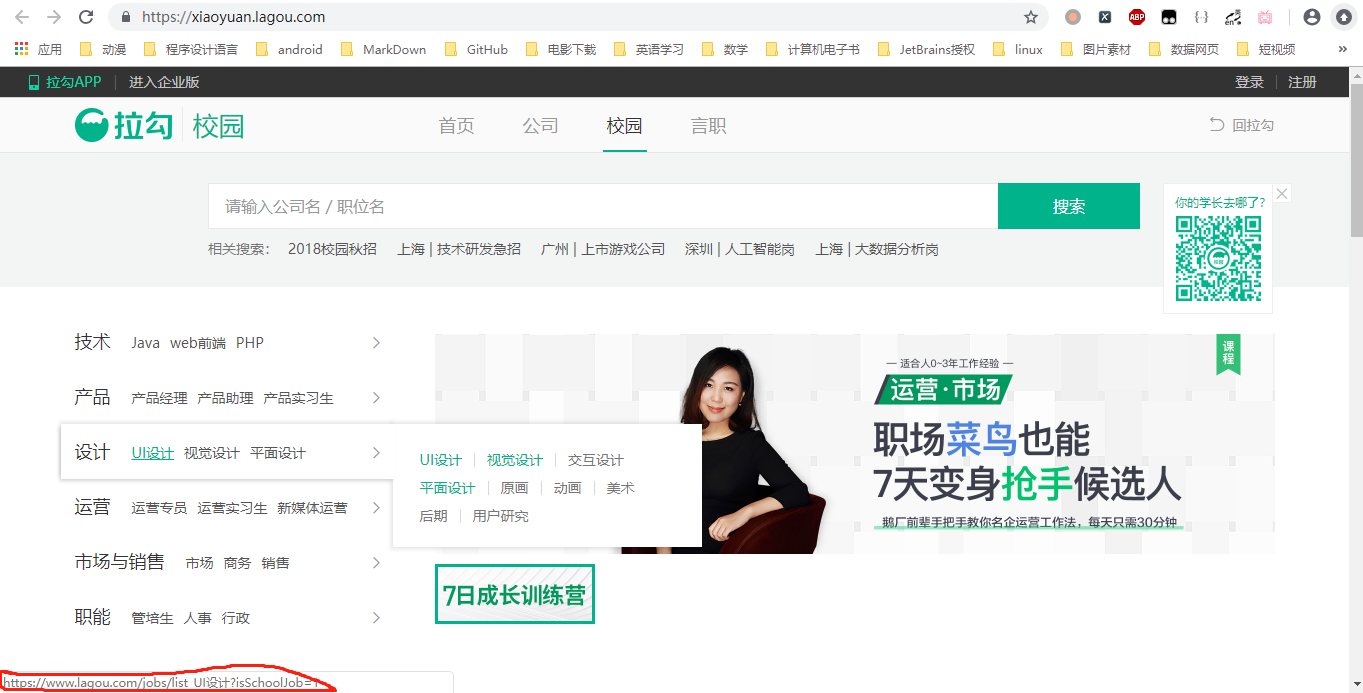
3、大标签校园的分析
可以看出来,这个和首页的结构比较类型,那我们就和首页一样,选取职业方向标签的url作为跟进的目标,可以看出每一个标签都是类似lagou.com/jobs/list_.* (.*代表0个或多个任意字符)
通过以上分析,我们就知道对于拉勾网来说,要想做到全站抓取,需要跟进哪些链接。
scrapy抓取拉勾网职位信息(二)——拉勾网页面分析的更多相关文章
- 抓取某东的TT购买记录分析TT购买趋势
最近学习了一些爬虫技术,想做个小项目检验下自己的学习成果,在逛某东的时候,突然给我推荐一个TT的产品,点击进去浏览一番之后就产生了抓取TT产品,然后进行数据分析,看下那个品牌的TT卖得最好. 本文通过 ...
- scrapy抓取拉勾网职位信息(一)——scrapy初识及lagou爬虫项目建立
本次以scrapy抓取拉勾网职位信息作为scrapy学习的一个实战演练 python版本:3.7.1 框架:scrapy(pip直接安装可能会报错,如果是vc++环境不满足,建议直接安装一个visua ...
- 【图文详解】scrapy爬虫与动态页面——爬取拉勾网职位信息(2)
上次挖了一个坑,今天终于填上了,还记得之前我们做的拉勾爬虫吗?那时我们实现了一页的爬取,今天让我们再接再厉,实现多页爬取,顺便实现职位和公司的关键词搜索功能. 之前的内容就不再介绍了,不熟悉的请一定要 ...
- scrapy抓取斗鱼APP主播信息
如何进行APP抓包 首先确保手机和电脑连接的是同一个局域网(通过路由器转发的网络,校园网好像还有些问题). 1.安装抓包工具Fiddler,并进行配置 Tools>>options> ...
- Java广度优先爬虫示例(抓取复旦新闻信息)
一.使用的技术 这个爬虫是近半个月前学习爬虫技术的一个小例子,比较简单,怕时间久了会忘,这里简单总结一下.主要用到的外部Jar包有HttpClient4.3.4,HtmlParser2.1,使用的开发 ...
- 通过Scrapy抓取QQ空间
毕业设计题目就是用Scrapy抓取QQ空间的数据,最近毕业设计弄完了,来总结以下: 首先是模拟登录的问题: 由于Tencent对模拟登录比较讨厌,各个防备,而本人能力有限,所以做的最简单的,手动登录后 ...
- python scrapy 抓取脚本之家文章(scrapy 入门使用简介)
老早之前就听说过python的scrapy.这是一个分布式爬虫的框架,可以让你轻松写出高性能的分布式异步爬虫.使用框架的最大好处当然就是不同重复造轮子了,因为有很多东西框架当中都有了,直接拿过来使用就 ...
- scrapy抓取淘宝女郎
scrapy抓取淘宝女郎 准备工作 首先在淘宝女郎的首页这里查看,当然想要爬取更多的话,当然这里要查看翻页的url,不过这操蛋的地方就是这里的翻页是使用javascript加载的,这个就有点尴尬了,找 ...
- Scrapy抓取Quotes to Scrape
# 爬虫主程序quotes.py # -*- coding: utf-8 -*- import scrapy from quotetutorial.items import QuoteItem # 启 ...
- 分布式爬虫:使用Scrapy抓取数据
分布式爬虫:使用Scrapy抓取数据 Scrapy是Python开发的一个快速,高层次的屏幕抓取和web抓取框架,用于抓取web站点并从页面中提取结构化的数据.Scrapy用途广泛,可以用于数据挖掘. ...
随机推荐
- IE8动态创建CSS
IE8动态创建CSS 最近在项目中用到在页面中动态创建CSS方法,记录一下方便以后查看 一. 在IE下动态创建(网上收集3种方法,最后一个方法未测试成功,具体不知道什么原因) 第一种(此方法很麻烦,需 ...
- 确保web安全的https、确认访问用户身份的认证(第七章、第八章)
第七章 确保web安全的https 1.http的缺点: (1)通信使用明文,内容可能会被窃听 (2)不验证通信方的身份,因此有可能遭遇伪装 (3)无法证明报文的完整性,因此有可能已遭篡改. 2.通信 ...
- ASP.NET和ASP的区别是什么
分析: ASP与ASP.NET是Microsoft公司在Web应用程序开发上的两项重要技术. ASP与ASP.NET区别如下: (1)开发语言不同:ASP的开发语言仅局限于使用non-type脚本语言 ...
- Sass 颜色函数
/* * Sass 颜色函数 * RGB 颜色函数 * 1. rgb($red,$green,$blue):根据红.绿.蓝三个值创建一个颜色: * rgb(200,40,88) //根据r:200,g ...
- 【转】IOS版本自定义字体步骤
本文转载自:http://quick.cocoachina.com/wiki/doku.php?id=ios%E7%89%88%E6%9C%AC%E4%BD%BF%E7%94%A8%E8%87%AA% ...
- MyBatis 框架系列之基础初识
MyBatis 框架系列之基础初识 1.什么是 MyBatis MyBatis 本是 apache 的一个开源项目 iBatis,后改名为 MyBatis,它 是一个优秀的持久层框架,对 jdbc 的 ...
- Python作业模拟登陆(第一周)
模拟登陆:1. 用户输入帐号密码进行登陆2. 用户信息保存在文件内3. 用户密码输入错误三次后锁定用户 思路: 1. 用户名密码文件为passwd,锁定用户文件为lock 2. 用户输入账号密码采用i ...
- Html5_sessionStrong和localStorage的灵活使用
谈谈这两个属性sessionStrong和localStorage是Html5新增点属性,用来记录一些数据在浏览器. 两者的区别sessionStrong存储的数据是暂时的,浏览器关掉后,存储下来的数 ...
- eclipse+EGIT+GitHub
下载EGIT:http://wiki.eclipse.org/EGit/FAQ#Where_can_I_find_older_releases_of_EGit.3F 1.下载eclipse版本对应的E ...
- 初识费用流 模板(spfa+slf优化) 餐巾计划问题
今天学习了最小费用最大流,是网络流算法之一.可以对于一个每条边有一个容量和一个费用(即每单位流的消耗)的图指定一个源点和汇点,求在从源点到汇点的流量最大的前提下的最小费用. 这里讲一种最基础也是最好掌 ...