OpenStack Ceilometer -- 后台数据存储优化之MongoDB的分片存储设置
https://xiaofandh12.github.io/Mongo-Shard
关于MongoDB
MongoDB中的概念与关系型数据库之间的对应:
- Database --> Database
- Collection --> Table
- Document --> Row
MongoDB相较于关系型数据库的优势:
- 简化关系型数据库复杂的关联问题
- 摆脱关系模型里面的强一致性限制
- MongoDB可以做到水平扩展和高可用
学习MongoDB有几个比较重要的方面:
- CRUD操作
- 聚合(Aggregation)操作
- 索引(Indexs)
- 存储引擎(Storage)
- 复制集(Replication)
- 分片(Sharding)
- 各种命令
MongoDB的部署
yum info mongo-10gen查看yum源中是否包含MongoDB的相关资源。vi /etc/yum.repos.d/10gen.repo添加yum源,若已有则不添加。[10gen]name=10gen Repositorybaseurl=http://downloads-distro.mongodb.org/repo/redhat/os/x86_64gpgcheck=0
yum info mongo-10gen-server,配置好yum源之后,查看yum源中是否包含MongoDB的服务器包的信息。安装MongoDB的服务器端和客户端工具:
yum install mongo-10gen-serveryum install mongo-10gen
根据需要修改
/etc/mongod.conf,启动MongoDB:service mongod start。
MongoDB的简单操作
连接MongoDB
相关操作如下:
[root@node-51 ~]# mongo --host hostIP/hostName --port portNummongos> show dbsadmin *GBceilometer *GBconfig *GBmongos> use ceilometermongos> show collectionsmeterprojectresourcesystem.indexessystem.usersuser
查询meter中所有的数据
相关操作如下:
mongos> db.meter.find()mongos> db.meter.find().count()
查询meter中所有的counter_name
相关操作如下:
mongos> db.meter.distinct("counter_name")
查询meter中各counter_name有多少条记录
相关操作如下:
mongos> db.meter.aggregate([{$group: {_id: "$counter_name",count: {$sum:1}}},{ $match: { count: { $gt: 1 } } }])
我们一般对SQL型的数据库比较熟,因此对一些复杂的查询我们可以用SQL的思维来思考,再到页面SQL to Aggregation Mapping Chart中去寻找对应的MongoDB的查询方式
查询counter_name为hardware.memory.total时,resource_id分别为什么
相关操作如下:
mongos> db.meter.aggregate([{$match: {counter_name: "hardware.memory.total"}},{$group: {_id: {counter_name: "$counter_name",resource_id: "$resource_id"}}}])
分片与复制集(Sharding与Replication)
一个完整的数据库可以备份为多份,原始的数据库和备份的数据库就组成了一个复制集,由此可以提高容错性。
一个完整的数据库的数据可以进行分片,通过分片可以把数据库中的完整数据分为多份分别存储在多台机器中,由此可以提高吞吐量。
分片和复制集是分开的两个功能,可以只做分片,也可以只做复制集。
如果既有分片又有复制集的话,那么同一个分片组成的集合就是一个复制集,如一个数据库分为两片shard1、shard2,可以再分别对shard1、shard2做两个复制shard1_1、shard1_2、shard2_1、shard2_2,那么shard1、shar1_1、shard1_2组成一个复制集,shard2、shard2_1、shard2_2组成另一个复制集。
MongoDB的每一个分片或复制集中的分片都可以不存储在同一个机器上,只要指定好IP地址和端口号即可。
本文并不讨论复制集的问题。
MongoDB的分片,分为两片,两个分片在同一台物理机上
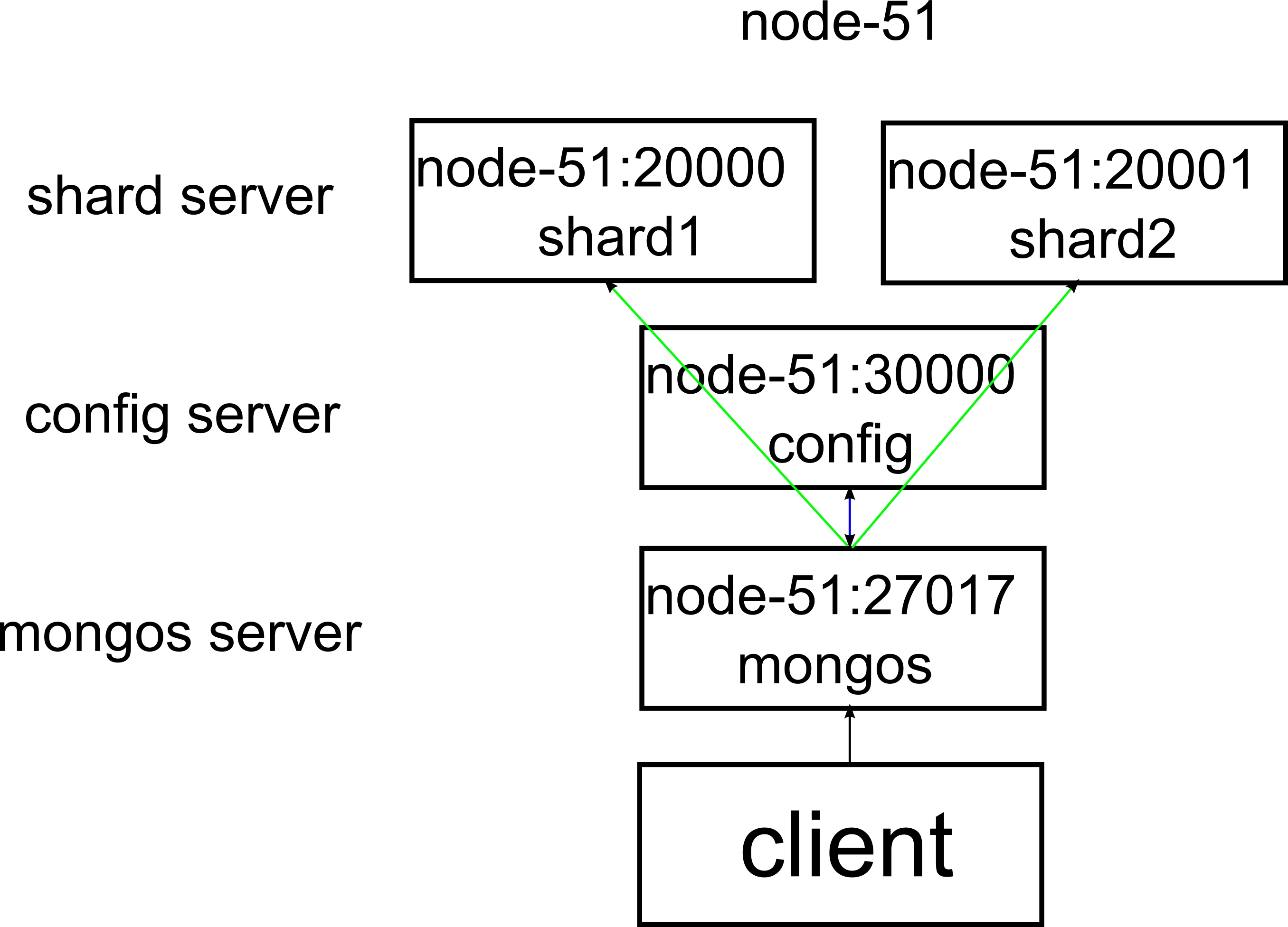
node-51为一台物理机,它的IP地址为172.31.2.51。
图中各服务所在IP和端口号,对应过来如下:
- shard1 --> 172.31.2.51:20000
- shard2 --> 172.31.2.51:20001
- config --> 172.31.2.51:30000
- mongos --> 172.31.2.51:27017
client通过mongos(172.31.2.51:27017)即可对数据库进行读写。
新建数据目录和日志目录
[root@node-51 ~]# mkdir -p /data/shard/s0[root@node-51 ~]# mkdir -p /data/shard/s1[root@node-51 ~]# mkdir -p /data/shard/log
配置shard server
[root@node-51 ~]# /usr/bin/mongod --shardsvr --port 20000 --dbpath /data/shard/s0 --fork --logpath /data/shard/log/s0.log --directoryperdb[root@node-51 ~]# /usr/bin/mongod --shardsvr --port 20001 --dbpath /data/shard/s1 --fork --logpath /data/shard/log/s1.log --directoryperdb
配置config server和route server
[root@node-51 ~]# mkdir -p /data/shard/config[root@node-51 ~]# /usr/bin/mongod --configsvr --port 30000 --dbpath /data/shard/config --fork --logpath /data/shard/log/config.log --directoryperdb[root@node-51 ~]# /usr/bin/mongos --port 27017 --configdb 172.31.2.51:30000 --fork --logpath /data/shard/log/route.log --chunkSize 1
admin数据库和ceilometer数据库配置
[root@node-51 ~]# mongo admin --host 172.31.2.51 --port 27017mongos> use adminmongos> db.runCommand({addshard:'172.31.2.51:20000'})mongos> db.runCommand({addshard:'172.31.2.51:20001'})mongos> db.runCommand({enablesharding:'ceilometer'})mongos> db.runCommand({shardcollecton:'ceilometer.meter',key:{counter_name:1}})mongos> use ceilometermongos> db.addUser("ceilometer","ceilometer")mongos> db.meter.stats()
在这里ceilometer是一个新建的数据库,OpenStack模块的openstack-ceilometer需要连接MongoDB中的ceilometer数据库,而openstack-ceilomter在连接MongoDB中的ceilometer数据库时,使用的是用户名:ceilometer,密码:ceilometer来连接的(再安装openstack-ceilometer时设置的),所以有了db.addUser("ceilometer","ceilomter")。
修改ceilometer.conf,并重启ceilometer服务
将ceilometer.conf中的connection改为如下:
connection=mongodb://ceilometer:ceilometer@172.31.2.51:27017/ceilometer
重启ceilometer服务:
[root@node-51 ~]# service openstack-ceilometer-alarm-evalutor restart[root@node-51 ~]# service openstack-ceilometer-alarm-notifier restart[root@node-51 ~]# service openstack-ceilometer-api restart[root@node-51 ~]# service openstack-ceilometer-central restart[root@node-51 ~]# service openstack-ceilometer-collector restart
Mongodb分片后的开机启动设置
现在有一个问题是,设置好分片重启机器后,又得重新执行分片的命令。目前解决的办法是在/etc/rc.d/rc.local/中新增命令。
关闭mongod开机启动:
[root@node-51 ~]# chkconfig --list | grep mongod --> 可以查出mongod在哪几个运行级别上运行了[root@node-51 ~]# chkconfig --levels 2345 mongod off
在文件/etc/rc.d/rc.local中,增加下述内容:
/usr/bin/mongod --shardsvr --port 20000 --dbpath /data/shard/s0 --fork --logpath /data/shard/log/s0.log --directoryperdb/usr/bin/mongod --shardsvr --port 20001 --dbpath /data/shard/s1 --fork --logpath /data/shard/log/s1.log --directoryperdb/usr/bin/mongod --configsvr --port 30000 --dbpath /data/shard/config --fork --logpath /data/shard/log/config.log --directoryperdb/usr/bin/mongos --port 27017 --configdb 172.31.2.51:30000 --fork --logpath /data/shard/log/route.log --chunkSize 1service openstack-ceilometer-alarm-evalutor restartservice openstack-ceilometer-alarm-notifier restartservice openstack-ceilometer-api restartservice openstack-ceilometer-central restartservice openstack-ceilometer-collector restart
这个问题没算完全解决,有空再看看《鸟哥的linux私房菜》第18章 认识系统服务(daemons)和第20章 启动流程、模块管理与Loader。
MongoDB的分片,分为三片,三个分片在不同的物理机上
这小节我会介绍一下把MongoDB中的数据库分为三片,并且把三个分片存储在不同物理机上的方法。
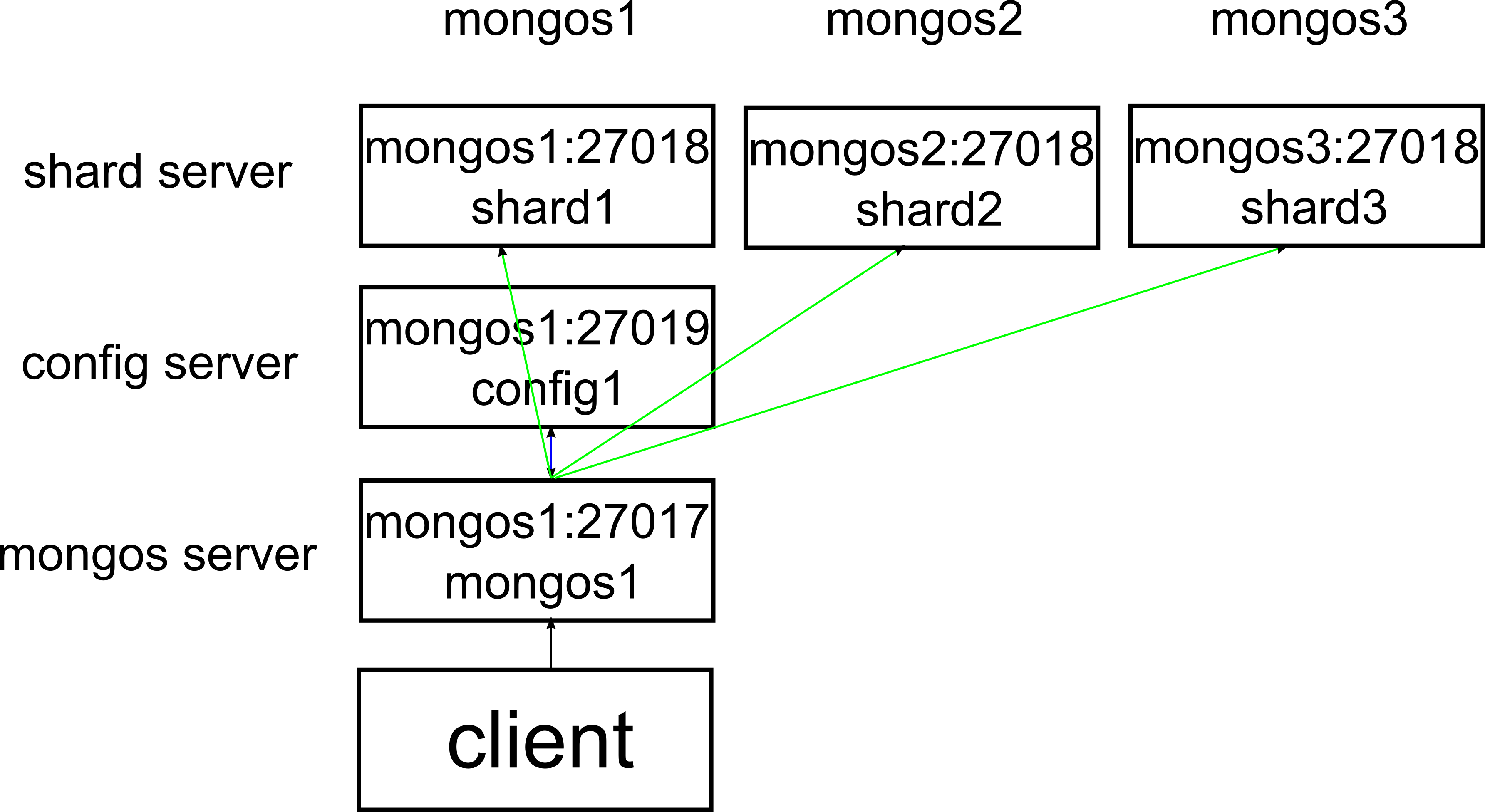
mongos1,mongos2,mongos3代表三台物理机,它们的IP地址为:
- mongos1 --> 172.31.2.135
- mongos2 --> 172.31.2.136
- mongos3 --> 172.31.2.137
图中各服务所在IP和端口号,对应过来如下:
- shard1 --> 172.31.2.135:27018
- shard2 --> 172.31.2.136:27018
- shard3 --> 172.31.2.137:27018
- config1 --> 172.31.2.135:27019
- mongos1 --> 172.31.2.135:27017
client通过连接mongos1(172.31.2.135:27017)即可对数据库进行读写。
下面详细介绍一下整个过程:
安装好操作系统,安装好MongoDB,重要提醒:关闭iptables,seLinux(因为这个我中午都没睡成午觉...)
service iptables stopsetenforce 0
在mongos1, mongos2, mongos3中新建目录
[root@mongos1 ~]# mkdir -p /data/shard/s1[root@mongos1 ~]# mkdir -p /data/shard/log[root@mongos1 ~]# mkdir -p /data/shard/config[root@mongos2 ~]# mkdir -p /data/shard/s2[root@mongos2 ~]# mkdir -p /data/shard/log[root@mongos3 ~]# mkdir -p /data/shard/s3[root@mongos3 ~]# mkdir -p /data/shard/log
在mongos1, mongos2, mongos3中配置shard server
[root@mongos1 ~]# mongod --shardsvr --port 27018 --dbpath /data/shard/s1 --fork --logpath /data/shard/log/s1.log --directoryperdb[root@mongos2 ~]# mongod --shardsvr --port 27018 --dbpath /data/shard/s2 --fork --logpath /data/shard/log/s2.log --directoryperdb[root@mongos3 ~]# mongod --shardsvr --port 27018 --dbpath /data/shard/s3 --fork --logpath /data/shard/log/s3.log --directoryperdb
在mongos1中配置config server
[root@mongos1 ~]# mongod --configsvr --port 27019 --dbpath /data/shard/config --fork --logpath /data/shard/log/config.log --directoryperdb
在mongos1中配置route server
[root@mongos1 ~]# mongos --port 27017 --configdb 172.31.2.135:27019 --fork --logpath /data/shard/log/route.log --chunkSize 1
在mongos1中配置admin数据库和ceilometer数据库
[root@mongos1 ~]# mongo admin --host 172.31.2.135 --port 27017mongos> db.runCommand({addshard:'172.31.2.135:27018'})mongos> db.runCommand({addshard:'172.31.2.136:27018'})mongos> db.runCommand({addshard:'172.31.2.137:27018'})mongos> db.runCommand({enablesharding:'ceilometer'})mongos> db.runCommand({shardCollection:'ceilometer.meter',key:{counter_name:1}})mongos> use ceilometermongos> db.addUser("ceilometer", "ceilometer")mongos> db.meter.stats()mongos> sh.status()
修改ceilometer.conf,并重启ceilometer服务
将ceilometer.conf中的connection改为如下:
connection=mongodb://ceilometer:ceilometer@172.31.2.135:27017/ceilometer
重启ceilometer服务:
[root@node-51 ~]# service openstack-ceilometer-alarm-evalutor restart[root@node-51 ~]# service openstack-ceilometer-alarm-notifier restart[root@node-51 ~]# service openstack-ceilometer-api restart[root@node-51 ~]# service openstack-ceilometer-central restart[root@node-51 ~]# service openstack-ceilometer-collector restart
可以再到mongos1中去查看数据量db.meter.find().count(),每隔一段时间执行一次,数字是不是越来越大。
MongoDB:Expire Data from Collections by Setting TTL
当MongoDB数据库中的数据量变得很大时,查询的速度也会随之下降,定期的删除或转存数据库中的数据就成为了一个很重要的需求了。
在MongoDB 2.2中就引进了一个功能,即Expire Data from Collections by Setting TTL,有了这个功能我们只要做一个简单的设置就可以定期的删除历史数据了。
在Ceilometer的配置文件中,设置了ttl的相关参数后,Ceiloemter的后台数据库就会去自动清理数据库中的历史数据,而后台数据库不论是MongoDB还是关系型数据库都可以,当后台是MongoDB时就正是利用了MongoDB 2.2中引入的Expire Data from Collections by Setting TTL这项功能。
Ceilometer中新增自动清理数据库中的历史数据的blueprint页面为:Database data TTL,review页面为:Database data TTL Review
OpenStack Ceilometer -- 后台数据存储优化之MongoDB的分片存储设置的更多相关文章
- MongoDB 搭建分片集群
在MongoDB(版本 3.2.9)中,分片是指将collection分散存储到不同的Server中,每个Server只存储collection的一部分,服务分片的所有服务器组成分片集群.分片集群(S ...
- MongoDB之分片集群(Sharding)
MongoDB之分片集群(Sharding) 一.基本概念 分片(sharding)是一个通过多台机器分配数据的方法.MongoDB使用分片支持大数据集和高吞吐量的操作.大数据集和高吞吐量的数据库系统 ...
- 树后台数据存储(採用webmethod)
树后台数据存储 关于后台数据存储将集中在此篇解说 /* *作者:方浩然 *日期:2015-05-26 *版本号:1.0 */ using System; using System.Collection ...
- Redis数据存储优化机制(转)
原文:Redis学习笔记4--Redis数据存储优化机制 1.zipmap优化hash: 前面谈到将一个对象存储在hash类型中会占用更少的内存,并且可以更方便的存取整个对象.省内存的原因是新建一个h ...
- Openstack Ceilometer监控项扩展
Openstack ceilometer主要用于监控虚拟机.服务(glance.image.network等)和事件.虚拟机的监控项主要包括CPU.磁盘.网络.instance.本文在现有监控项的基础 ...
- 中国铁路基于Intel架构超大规模OpenStack行业云的性能优化研究
1. 项目简介 铁路作为一种大众化的交通工具和非常重要的货物运输方式,其业务规模庞大.覆盖全国.服务全国各族人民.铁路面向公众提供的服务业务,主要是客运和货运两大类,且每年365天.每天7*24小时连 ...
- Kudu – 在快数据上的进行快分析的存储
转自: http://www.tuicool.com/articles/nmYf2uf Cloudera Impala Kudu – 在快数据上的进行快分析的存储 Kudu,对应中文的含义应该 ...
- <转>Openstack Ceilometer监控项扩展
Openstack ceilometer主要用于监控虚拟机.服务(glance.image.network等)和事件.虚拟机的监控项主要包含CPU.磁盘.网络.instance.本文在现有监控项的基础 ...
- <转>Openstack ceilometer 宿主机监控模块扩展
<Openstack ceilometer监控项扩展>( http://eccp.csdb.cn/blog/?p=352 )主要介绍了对虚拟机监控项扩展, 比較简单.怎样在ceilomet ...
随机推荐
- grunt的简单应用
grunt是干什么的呢,一句话:自动化.对于需要反复重复的任务,例如压缩(minification).编译.单元测试.linting等,自动化工具可以减轻你的劳动,简化你的工作.当你在 Gruntfi ...
- orchestrator-Raft集群部署
本文简要说明下orchestrator的Raft集群部署,其实部署很简单主要是好好研究下配置文件的配置,这里我的样例配置文件暂时只适用于我们这块业务 如果您自己使用请根据情况自行修改. 主要通过配置文 ...
- [转载]Css设置table网格线(无重复)
原文地址:Css设置table网格线(无重复)作者:依然贰零零柒 效果图: <!DOCTYPE html PUBLIC "-//W3C//DTD XHTML 1.0Transition ...
- Andrew Ng机器学习编程作业:Regularized Linear Regression and Bias/Variance
作业文件: machine-learning-ex5 1. 正则化线性回归 在本次练习的前半部分,我们将会正则化的线性回归模型来利用水库中水位的变化预测流出大坝的水量,后半部分我们对调试的学习算法进行 ...
- DB2中编目本机其中数据库的方法
问题:同一节点上有两个实例.假设想在当中一个实例下訪问还有一个实例中的数据库,有两种方法: 1. 使用catalog local node的方式,在当中一个实例中将另外一个实例直接编目,这样的方试中, ...
- springcloud Hystrix fallback无效
在使用feign调用服务的时候防止雪崩效应,因此需要添加熔断器.(基于springboot2.0) 一.在控制器的方法上添加 fallbackMethod ,写一个方法返回,无须在配置文件中配置,因 ...
- Tornado介绍与其Web应用结构
1.介绍 tornado是一个Python web框架和异步网络库 起初由 FriendFeed 开发. 通过使用非阻塞网络I/O, Tornado 可以支持上万级的连接,处理 长连接, WebSoc ...
- 安装vue-cli脚手架
一.安装node.js 1.什么是node.js? Node.js 是一个基于 Chrome V8 引擎的 JavaScript 运行环境. Node.js 使用了一个事件驱动.非阻塞式 I/O 的模 ...
- 连接postgresql
# psycopg2 engine=create_engine('postgresql+psycopg2://scott:tiger@localhost/mydatabase')# python 连 ...
- php采集
采集思路 采集程序的思路很简单大体可以分为以下几个步骤: 1. 获取远程文件源代码(file_get_contents或用fopen). 2.分析代码得到自己想要的内容(这里用正则匹配,一般 ...