python爬取大众点评并写入mongodb数据库和redis数据库
抓取大众点评首页左侧信息,如图:
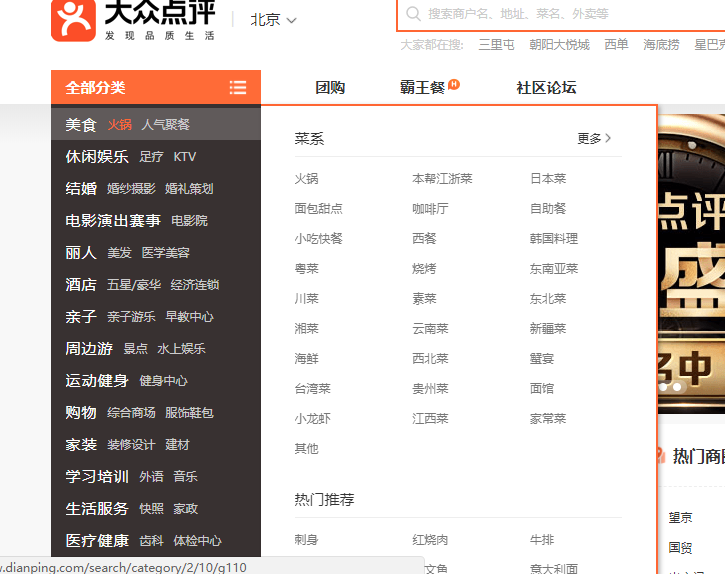
我们要实现把中文名字都存到mongodb,而每个链接存入redis数据库。
因为将数据存到mongodb时每一个信息都会有一个对应的id,那样就方便我们存入redis可以不出错。
# -*- coding: utf-8 -*-
import re
from urllib.request import urlopen
from urllib.request import Request
from bs4 import BeautifulSoup
from lxml import etree
import pymongo client = pymongo.MongoClient(host="127.0.0.1")
db = client.dianping #库名dianping
collection = db.classification #表名classification import redis #导入redis数据库
r = redis.Redis(host='127.0.0.1', port=6379, db=0) # client = pymongo.MongoClient(host="192.168.60.112")
# myip = client['myip'] # 给数据库命名
def secClassFind(selector, classid):
secItems = selector.xpath('//div[@class="sec-items"]/a')
for secItem in secItems:
url = secItem.get('href') #得到url
title = secItem.text
classid = collection.insert({'classname': title, 'pid': classid})
classurl = '%s,%s' % (classid, url) #拼串
r.lpush('classurl', classurl) #入库 def Public(url):
headers = {'User-Agent': 'Mozilla/5.0 (Windows; U; Windows NT 6.1; en-US; rv:1.9.1.6) Gecko/20091201 Firefox/3.5.6'} #协议头
req_timeout = 5
req = Request(url=url, headers=headers)
f = urlopen(req, None, req_timeout)
s = f.read()
s = s.decode("utf-8")
# beautifulsoup提取
soup = BeautifulSoup(s, 'html.parser')
links = soup.find_all(name='li', class_="first-item")
for link in links:
selector = etree.HTML(str(link))
# indexTitleUrls = selector.xpath('//a[@class="index-title"]/@href')
# # 获取一级类别url和title
# for titleurl in indexTitleUrls:
# print(titleurl)
indexTitles = selector.xpath('//a[@class="index-title"]/text()')
for title in indexTitles:
# 第二级url
print(title)
classid = collection.insert({'classname': title, 'pid': None})
secClassFind(selector, classid)
print('---------')
# secItems = selector.xpath('//div[@class="sec-items"]/a')
# for secItem in secItems:
# print(secItem.get('href'))
# print(secItem.text)
print('-----------------------------')
#
# myip.collection.insert({'name':secItem.text})
# r.lpush('mylist', secItem.get('href')) # collection.find_one({'_id': ObjectId('5a14c8916d123842bcea5835')}) # connection = pymongo.MongoClient(host="192.168.60.112") # 连接MongDB数据库 # post_info = connection.myip # 指定数据库名称(yande_test),没有则创建
# post_sub = post_info.test # 获取集合名:test
Public('http://www.dianping.com/')
python爬取大众点评并写入mongodb数据库和redis数据库的更多相关文章
- python爬取大众点评
拖了好久的代码 1.首先进入页面确定自己要抓取的数据(我们要抓取的是左侧分类栏-----包括美食.火锅)先爬取第一级分类(美食.婚纱摄影.电影),之后根据第一级链接爬取第二层(火锅).要注意第二级的p ...
- Python 爬取大众点评 50 页数据,最好吃的成都火锅竟是它!
前言 文的文字及图片来源于网络,仅供学习.交流使用,不具有任何商业用途,版权归原作者所有,如有问题请及时联系我们以作处理. 作者: 胡萝卜酱 PS:如有需要Python学习资料的小伙伴可以加点击下方链 ...
- 用Python爬取大众点评数据,推荐火锅店里最受欢迎的食品
前言 文的文字及图片来源于网络,仅供学习.交流使用,不具有任何商业用途,版权归原作者所有,如有问题请及时联系我们以作处理. 作者:有趣的Python PS:如有需要Python学习资料的小伙伴可以加点 ...
- python爬虫实战---爬取大众点评评论
python爬虫实战—爬取大众点评评论(加密字体) 1.首先打开一个店铺找到评论 很多人学习python,不知道从何学起.很多人学习python,掌握了基本语法过后,不知道在哪里寻找案例上手.很多已经 ...
- python爬虫爬取大众点评并导入redis
直接上代码,导入redis的中文编码没有解决,日后解决了会第一时间上代码!新手上路,多多包涵! # -*- coding: utf-8 -*- import re import requests fr ...
- python 爬取段子网段子写入文件
import requests import re 进入网址 for i in range(1,5): page_url = requests.get(f"http://duanziwang ...
- 利用Python爬取豆瓣电影
目标:使用Python爬取豆瓣电影并保存MongoDB数据库中 我们先来看一下通过浏览器的方式来筛选某些特定的电影: 我们把URL来复制出来分析分析: https://movie.douban.com ...
- Python爬取豆瓣音乐存储MongoDB数据库(Python爬虫实战1)
1. 爬虫设计的技术 1)数据获取,通过http获取网站的数据,如urllib,urllib2,requests等模块: 2)数据提取,将web站点所获取的数据进行处理,获取所需要的数据,常使用的技 ...
- Python:将爬取的网页数据写入Excel文件中
Python:将爬取的网页数据写入Excel文件中 通过网络爬虫爬取信息后,我们一般是将内容存入txt文件或者数据库中,也可以写入Excel文件中,这里介绍关于使用Excel文件保存爬取到的网页数据的 ...
随机推荐
- css随笔属性
anchor伪类,用于阅读文章.a:link(没有接触过的链接),用于链接常规状态 (末访问的链接)a:hover(鼠标放在链接上的状态) 用于产生视觉效果(已访问的链接)a:visited(访问过的 ...
- java连接VMware虚拟机Oracle数据库问题
最近在电脑上装了虚拟机,为的是在虚拟机上安装Oracle数据库,Oracle实在太占内存,配置低的电脑装个Oracle几乎就瘫了,没办法,搞个虚拟机玩玩.我虚拟机用的是xp系统,顺便怀念下经典.装好O ...
- zzuli 1815: easy problem 打表
1815: easy problem Time Limit: 1 Sec Memory Limit: 128 MB Submit: 243 Solved: 108 SubmitStatusWeb ...
- Linux下如何彻底删除MySQL
1.查找以前是否装有mysql 命令:rpm -qa|grep -i mysql可以看到如下图的所示: 说明之前安装了:MySQL-client-5.5.25a-1.rhel5MySQL-server ...
- Python的字符编码
Python的字符编码 1. Python字符编码简介 1. 1 ASCII Python解释器在加载.py文件的代码时,会对内容进行编码,一般默认为ASCII码.ASCII(American St ...
- poj 1035KINA Is Not Abbreviation
题目链接:http://poj.org/problem?id=4054 本题的题意是在下面那部分待检验的单词中找到与之相对应的正确的代词,包含几种情况,一是全部字母相同,二是有一个字母不相同,三是多一 ...
- 智能合约语言 Solidity 教程系列4 - 数据存储位置分析
写在前面 Solidity 是以太坊智能合约编程语言,阅读本文前,你应该对以太坊.智能合约有所了解, 如果你还不了解,建议你先看以太坊是什么 这部分的内容官方英文文档讲的不是很透,因此我在参考Soli ...
- RUP 方法简介
1.什么是RUP: Rational Unified Process(以下简称RUP) 是一套软件工程方法,主要由 Ivar Jacobson的 The Objectory Approch 和 The ...
- 面试题(php部分)
1.用PHP打印出前一天的时间格式是2006-5-10 22:21:21(2分) [答案] $a = date("Y-m-d H:i:s", strtotime("-1 ...
- [原创]mysql的zip包如何在windows下安装
今天在尝试zipkin的链路数据写入mysql,本机恰好没有按照mysql.找到一个很久前谁发的mysql-5.6.19-winx64.zip,版本不新?别挑剔啦,只是本机测试,能用就好哈哈.. 解压 ...