Chapter 3. Programming with RDDs
Programming with RDDs
This chapter introduces Spark’s core abstraction for working with data, the resilient
distributed dataset (RDD). An RDD is simply a distributed collection of elements. In
Spark all work is expressed as either creating new RDDs, transforming existing RDDs, or
calling operations on RDDs to compute a result.RDDs are the core concept
in Spark.
RDD Basics
An RDD in Spark is simply an immutable distributed collection of objects. Each RDD is split into multiple partitions, which may be computed on different nodes of the cluster.
1、Create an RDD
by loading an external dataset, or by distributing a collection of objects (e.g., a list or set) in their driver program. We have already seen loading a text file as an RDD of strings using SparkContext.textFile().
lines = sc.textFile(“README.md”)
2、两种操作
RDDs offer two types of operations
|————transformations
|————actions
***Transformations construct a new RDD from a previous one,for example:
pythonLines = lines.filter(lambda line: “Python” in line)
***Actions, on the other hand, compute a result based on an RDD, and either return it to the driver program or save it to an external storage system
pythonLines.first()
Transformations and actions are different because of the way Spark computes RDDs.具体而言,你可以随时定义一个RDD,但是spark计算RDD采取的一种懒惰方式(lazzy fashion)——transformation操作不会去真正的扫描计算RDD,直到你使用Action操作的时候,这个时候才会真正的计算RDD。比如上面的lines=sc.textFile("")不会立即把文件读入内存,知道使用了一个Action操作linses.first()的时候才真正的scans RDD的数据,而且不是完全扫描,一部分一部分数据加载,找到第一个满足条件的结果就结束。
3、Finally, Spark’s RDDs are by default recomputed each time you run an action on them. If you would like to reuse an RDD in multiple actions, you can ask Spark to persist it using RDD.persist().其实这也相当于是一种优化,重用计算结果。如果不persist下来,默认情况下spark会把计算出来的结果消除,这在大数据的场景中也是合理的,这样可以节省cluster宝贵的memory。
To summarize, every Spark program and shell session will work as follows:
1. Create some input RDDs from external data.
2. Transform them to define new RDDs using transformations like filter().
3. Ask Spark to persist() any intermediate RDDs that will need to be reused.
4. Launch actions such as count() and first() to kick off a parallel computation,
which is then optimized and executed by Spark.
Tip
cache() is the same as calling persist() with the default storage level.
====================================================
后面是对上面四部中涉及到的操作展开介绍。
1、Creating RDDs
Spark provides two ways to create RDDs: loading an external dataset and parallelizing a collection in your driver program.
(1)The simplest way to create RDDs is to take an existing collection in your program and pass it to SparkContext’s parallelize() method。 Keep in mind, however, that outside of prototyping and testing, this is not widely used since it requires that you have your entire dataset in memory on one machine.
examples:
lines = sc.parallelize([“pandas”, “i like pandas”]) #python
JavaRDD<String> lines = sc.parallelize(Arrays.asList(“pandas”, “i like pandas”)); //java
(2) a more common way
sc.textFiel("/path/to/README.md");
RDD Operations
As we’ve discussed, RDDs support two types of operations: transformations and actions.Transformations are operations on RDDs that return a new RDD, such as map() and filter(). Actions are operations that return a result to the driver program or write it to storage, and kick off a computation, such as count() and first(). Spark treats transformations and actions very differently, so understanding which type of operation you are performing will be important. If you are ever confused whether a given function is a transformation or an action, you can look at its return type: transformations return RDDs, whereas actions return some other data type.
(一)Transformations
Transformations are operations on RDDs that return a new RDD. As discussed in “Lazy Evaluation”, transformed RDDs are computed lazily, only when you use them in an action. Many transformations are element-wise; that is, they work on one element at a time; but this is not true for all transformations.
filter() transformation in Python
inputRDD = sc.textFile(“log.txt”)
errorsRDD = inputRDD.filter(lambda x: “error” in x)
filter() transformation in Java
JavaRDD<String> inputRDD = sc.textFile(“log.txt”);
JavaRDD<String> errorsRDD = inputRDD.filter(
new Function<String, Boolean>() {
public Boolean call(String x) { return x.contains(“error”); }
}
});
Note that the filter() operation does not mutate the existing inputRDD. Instead, it returns a pointer to an entirely new RDD.
Finally, as you derive new RDDs from each other using transformations, Spark keeps track of the set of dependencies between different RDDs, called the lineage graph.(这张图有点类似于类的集成关系图,一旦发生错误或数据丢失的时候的时候,可以及时恢复)
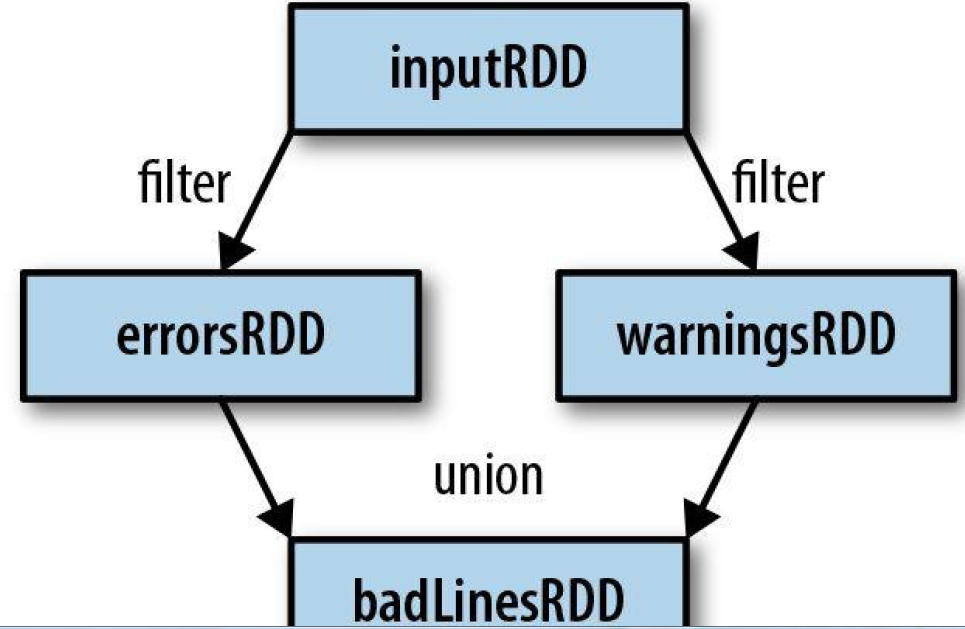
(二)Actions
Actions are the second type of RDD operation. They are the operations that return a final value to the driver program or write data to an external storage system.
#Python error count using actions
print “Input had “ + badLinesRDD.count() + ” concerning lines”
print “Here are 10 examples:”
for line in badLinesRDD.take(10):
print line
Java error count using actions
System.out.println(“Input had “ + badLinesRDD.count() + ” concerning lines”)
System.out.println(“Here are 10 examples:”)
for (String line: badLinesRDD.take(10)) {
System.out.println(line);
}
Note : take() VS collect
RDDs also have a collect() function aproximately equaling to take(), which can retrieve the entire RDD. Keep in mind that your entire dataset must fit in memory on a single machine to use collect() on it, so collect() shouldn’t be used on large datasets.
In most cases RDDs can’t just be collect()ed to the driver because they are too large. In these cases, it’s common to write data out to a distributed storage system such as HDFS or Amazon S3. You can save the contents of an RDD using the saveAsTextFile() action, saveAsSequenceFile(), or any of a number of actions for various built-in formats. We will cover the different options for exporting data in Chapter 5.
It is important to note that each time we call a new action, the entire RDD must be computed “from scratch.” To avoid this inefficiency, users can persist intermediate results, as we will cover in “Persistence (Caching)”.
(三)Lazy Evaluation
Rather than thinking of
an RDD as containing specific data, it is best to think of each RDD as consisting of
instructions on how to compute the data that we build up through transformations.
Passing Functions to Spark
当然也是三种语言的形式,这里主要介绍的是Python和java版本,其实传递函数的方法,前面已经介绍过了。
这里说明Python的传递函数时要注意的一一个问题,
One issue to watch out for when passing functions is inadvertently serializing the object containing the function. When you pass a function that is the member of an object, or contains references to fields in an object (e.g., self.field), Spark sends the entire object to worker nodes, which can be much larger than the bit of information you need (seeExample 3-19). Sometimes this can also cause your program to fail, if your class containsobjects that Python can’t figure out how to pickle.
Example 3-19. Passing a function with field references (don’t do this!)
class SearchFunctions(object):
def __init__(self, query):
self.query = query
def isMatch(self, s):
return self.query in s
def getMatchesFunctionReference(self, rdd):
# Problem: references all of “self” in “self.isMatch”
return rdd.filter(self.isMatch)
def getMatchesMemberReference(self, rdd):
# Problem: references all of “self” in “self.query”
return rdd.filter(lambda x: self.query in x)
作者所说的问题,上面带注释的地方就是表明的,就是传参,尤其是传递对象中的某个域的时候,一定先把域中的内容extract出来,用一个本地变量报错,然后传递这个本地变量,像下面这样操作:
class WordFunctions(object):
…
def getMatchesNoReference(self, rdd):
# Safe: extract only the field we need into a local variable
query = self.query
return rdd.filter(lambda x: query in x
Java
In Java, functions are specified as objects that implement one of Spark’s function interfaces from the org.apache.spark.api.java.function package. There are a number of different interfaces based on the return type of the function. We show the most basic function interfaces in Table 3-1, and cover a number of other function interfaces for when we need to return special types of data, like key/value data, in “Java”.
Table 3-1. Standard Java function interfaces
Function name Method to implement Usage
(1)Function<T, R> R call(T) Take in one input and return one output, for use with operations like map() and filter().
(2)Function2<T1, T2, R> R call(T1, T2) Take in two inputs and return one output, for use with operations like aggregate() or fold().(3)FlatMapFunction<T,R> Iterable<R>call(T) Take in one input and return zero or more outputs, for use with operationslike flatMap().
We can either define our function classes inline as anonymous inner classes (Example 3-
22), or create a named class (Example 3-23).
Example 3-22. Java function passing with anonymous inner class
RDD<String> errors = lines.filter(new Function<String, Boolean>() {
public Boolean call(String x) { return x.contains(“error”); }
});
Example 3-23. Java function passing with named class
class ContainsError implements Function<String, Boolean>() {
public Boolean call(String x) { return x.contains(“error”); }
}
RDD<String> errors = lines.filter(new ContainsError());
The style to choose is a personal preference, but we find that top-level named functions
are often cleaner for organizing large programs. One other benefit of top-level functions is
that you can give them constructor parameters, as shown in Example 3-24.
Example 3-24. Java function class with parameters
class Contains implements Function<String, Boolean>() {
private String query;
public Contains(String query) { this.query = query; }
public Boolean call(String x) { return x.contains(query); }
}
RDD<String> errors = lines.filter(new Contains(“error”));
In Java 8, you can also use lambda expressions to concisely implement the function
interfaces. Since Java 8 is still relatively new as of this writing, our examples use the more
verbose syntax for defining classes in previous versions of Java. However, with lambda
expressions, our search example would look like Example 3-25.
Example 3-25. Java function passing with lambda expression in Java 8
RDD<String> errors = lines.filter(s -> s.contains(“error”));
If you are interested in using Java 8’s lambda expression, refer to Oracle’s documentation
and the Databricks blog post on how to use lambdas with Spark.
Tip
Both anonymous inner classes and lambda expressions can reference any final variables
in the method enclosing them, so you can pass these variables to Spark just as in Python
and Scala.
接下来开始认真的介绍常用的一些transfornation和Action操作
map()凡是有key/value味道的操作,都可以使用这个map()操作,其核心是给map传递一个实际执行的函数,比如
Python squaring the values in an RDD
nums = sc.parallelize([1, 2, 3, 4])
squared = nums.map(lambda x: x * x).collect()
for num in squared:
print “%i “ % (num)
Java squaring the values in an RDD
JavaRDD<Integer> rdd = sc.parallelize(Arrays.asList(1, 2, 3, 4));
JavaRDD<Integer> result = rdd.map(new Function<Integer, Integer>() {
public Integer call(Integer x) { return x*x; }
});
System.out.println(StringUtils.join(result.collect(), “,”));
filter(),前面也多次使用,比如inputRDD.filter(lambda x: "error" inm x)
flatMap() 用一个输入,得到多个输出内容时,我们使用这个函数,比如:
flatMap() in Python, splitting lines into words
lines = sc.parallelize([“hello world”, “hi”])
words = lines.flatMap(lambda line: line.split(” “))
words.first() # returns “hello”
flatMap() in Java, splitting lines into multiple words
JavaRDD<String> lines = sc.parallelize(Arrays.asList(“hello world”, “hi”));
JavaRDD<String> words =
lines.flatMap(new FlatMapFunction<String, String>() {
public Iterable<String> call(String line) {
return Arrays.asList(line.split(” “));
}
});
words.first(); // returns “hello”
通俗的将map()和flatMap()的区别:
- Spark 中 map函数会对每一条输入进行指定的操作,然后为每一条输入返回一个对象;
- 而flatMap函数则是两个操作的集合——正是“先映射后扁平化”:
操作1:同map函数一样:对每一条输入进行指定的操作,然后为每一条输入返回一个对象
操作2:最后将所有对象合并为一个对象
具体而言就像上面的例子:
lines = sc.parralize(["hello world", "hi lilei"])
wordsMap = lines.map(lambda line : line.split(" "))
wordsMap.first() # ["hello", "word"]
worsFlatMap = lines.FlatMap(lambda line : line.split(" "))
wordsFlatMap.first() # 'hello'
wordsMap: {['hello', 'word'], ['hi', 'lilei']}
wordFlatmap: {'hello', 'world', 'hi', 'lilei'}
RDD支持一些伪集合操作:
包括,distinct, union , intersection , subtract(就是差集)
cartesian(),用来计算两个RDD的笛卡尔积Cartesian Product
=====再来总结一下常见的transformation====
1、对单个rdd使用的
map() 对每一个元素操作,进来多少个元素,返回的元素个数不变
flatMap()对每一个元素操作,最终把每一个元素又变成更小的不能拆的元素
fileter() distinct() distinct()
2、对两个rdd操作
union() intersaction() subtract() cartisian()
Actions
reduce()操作:可以方便的实现sum求和,计算rdd中元素的个数等等.reduce(binary_function)
reduce将RDD中元素前两个传给输入函数,产生一个新的return值,新产生的return值与RDD中下一个元素(第三个元素)组成两个元素,再被传给输入函数,直到最后只有一个值为止。
Python中的示例代码
sum = rdd.reduce(lambda x, y: x + y)
Java中的实例代码:
Integer sum = rdd.reduce(new Function2<Integer, Integer, Integer>() {
public Integer call(Integer x, Integer y) { return x + y; }
});
aggregate()aggregate函数将每个分区里面的元素进行聚合,然后用combine函数将每个分区的结果和初始值(zeroValue)进行combine操作。这个函数最终返回的类型不需要和RDD中元素类型一致。说实话这里aggregate的Python示例代码看的不是很明白,但是java版本的示例代码看的还是听明白的。
aggregate() in Python:
sumCount = nums.aggregate((0, 0),
(lambda acc, value: (acc[0] + value, acc[1] + 1),
(lambda acc1, acc2: (acc1[0] + acc2[0], acc1[1] + acc2[1]))))
return sumCount[0] / float(sumCount[1])
aggregate() in Java:
class AvgCount implements Serializable {
public AvgCount(int total, int num) {
this.total = total;
this.num = num;
}
public int total;
public int num;
public double avg() {
return total / (double) num;
}
} Function2<AvgCount, Integer, AvgCount> addAndCount =
new Function2<AvgCount, Integer, AvgCount>() {
public AvgCount call(AvgCount a, Integer x) {
a.total += x;
a.num += 1;
return a;
}
};
Function2<AvgCount, AvgCount, AvgCount> combine =
new Function2<AvgCount, AvgCount, AvgCount>() {
public AvgCount call(AvgCount a, AvgCount b) {
a.total += b.total;
a.num += b.num;
return a;
}
};
AvgCount initial = new AvgCount(0, 0);
AvgCount result = rdd.aggregate(initial, addAndCount, combine);
System.out.println(result.avg());
collect(), which returns the entire RDD’s contents. collect() is commonly used in unit
tests where the entire contents of the RDD are expected to fit in memory, as that makes it easy to compare the value of our RDD with our expected result.
take(n) returns n elements from the RDD and attempts to minimize the number of
partitions it accesses, so it may represent a biased collection. It’s important to note that
these operations do not return the elements in the order you might expect.
top() If there is an ordering defined on our data, we can also extract the top elements from an RDD using top(). top() will use the default ordering on the data, but we can supply our own comparison function to extract the top elements.
takeSample(withReplacement, num, seed) function allows us to take a sample of our
data either with or without replacement.
当然还有很多的Action的操作,这里就怒在一一列举,具体,可以参看书的P69总结的一个列表。
Converting Between RDD TypesRDD之间的类型转换
在spark中有一些函数只能操作数值型的RDD(numeric rdds),有一些函数只能操作数值对类型RDD(key/values RDD)。注意这些函数在Scala和Java中不是使用标准类的定义。
Persistence (Caching)
这个意思说说Spark的缓存机制,因为有些数据需要多次使用,所以就把相应的RDD缓存在机器中。
Python,java和Scala一种三种缓存机制,java和scala的缓存机制一样,是吧RDD中的数据缓存在jvm的heap中,Python则是把数据序列化出来写到硬盘中。
缓存技术有很多的等级,persistence levels,这个可以详细参见P72的table3-6,比如有MEMORY_ONLY,MEMORY_ONL_SER,MERORY_AND_DISK,MEMORY_AND_DISK_SER,DISK_ONLY
并分析了各种缓存策略的cpu时间,内存占用率等。下面是一段Scala的实例代码
val result = input.map(x => x * x)
result.persist(StorageLevel.DISK_ONLY)
println(result.count())
println(result.collect().mkString(“,”))
Notice that we called persist() on the RDD before the first action. The persist() call
on its own doesn’t force evaluation.
If you attempt to cache too much data to fit in memory, Spark will automatically evict old partitions using a Least Recently Used (LRU) cache policy. For the memory-only storage levels, it will recompute these partitions the next time they are accessed, while for the memory-and-disk ones, it will write them out to disk. In either case, this means that you don’t have to worry about your job breaking if you ask Spark to cache too much data.However, caching unnecessary data can lead to eviction of useful data and more recomputation time.
Finally, RDDs come with a method called unpersist() that lets you manually remove
them from the cache.
到这里chapter 3就讲完了。作者在结余里面这样说:The ability to always recompute an RDD is actually why RDDs are called “resilient.” When a machine holding RDD data fails, Spark uses this ability to recompute the missing partitions, transparent to the user.RDD总是能够被重复计算的能力就是RDD被称为“弹性”的实际原因,当一台机器所拥有的RDD数据失败的时候,Spark会使用这种弹性计算的能力重复计算丢失的部分,这个过程对用户而言完全是透明的。
Chapter 3. Programming with RDDs的更多相关文章
- Beginning Linux Programming 学习--chapter 17 Programming KDE using QT
KDE: KDE,K桌面环境(K Desktop Environment)的缩写.一种著名的运行于 Linux.Unix 以及FreeBSD 等操作系统上的自由图形桌面环境,整个系统采用的都是 Tro ...
- [core python programming]chapter 7 programming MS office
excel.pyw会有问题,解决如下: 因为python3x中没有tkMessageBox模块,Tkinter改成了tkinter你可以查看你的py当前支持的模块.在交互式命令行下输入>> ...
- <Spark><Programming><RDDs>
Introduction to Core Spark Concepts driver program: 在集群上启动一系列的并行操作 包含应用的main函数,定义集群上的分布式数据集,操作数据集 通过 ...
- 串口通信编程向导 Serial Programming Guide for POSIX Operating Systems
https://www.cmrr.umn.edu/~strupp/serial.html#CONTENTS Introduction Chapter 1, Basics of Serial Commu ...
- 系统架构--分布式计算系统spark学习(三)
通过搭建和运行example,我们初步认识了spark. 大概是这么一个流程 ------------------------------ -------------- ...
- Learning to write a compiler
http://stackoverflow.com/questions/1669/learning-to-write-a-compiler?rq=1 Big List of Resources: A N ...
- locations in main memory to be referenced by descriptive names rather than by numeric addresses
Computer Science An Overview _J. Glenn Brookshear _11th Edition Chapter 6 Programming Languages As s ...
- compiler
http://www.lingcc.com/2012/05/16/12048/ a list of compiler books — 汗牛充栋的编译器参考资料 Posted on 2012年5月16日 ...
- 一个人写的操作系统 - Sparrow OS
一个人写的操作系统 - Sparrow OS 自己写一个操作系统,这是在过去的几年里我一直为之努力的目标,现在终于完成了. 缘起 自己动手写操作系统的动机最初来自于学习Linux遇到的困难. 我是一个 ...
随机推荐
- 条形码--JsBarcode
介绍一下在GitHub生成条形码的js插件→JsBarcode 支持的条形码: 条码支持的有: CODE128 CODE128 (自动模式切换) CODE128 A/B/C (强制模式)EAN ...
- Socket通信流程
Socket通信流程 HTTP 底层就是通过socket建立连接通信管道,实现数据传输 HTTP是一个TCP的传输协议(方式),它是一个可靠,安全的协议
- java_XML_STAX
xml文件 <?xml version="1.0" encoding="UTF-8"?> <bookstore> <book ca ...
- JAVA中的小数
JAVA中的小数称为浮点数 1.有两种类型: float:单精度浮点数.4个字节. double:双精度浮点数.8个字节. 2.类型转换 容量小 -------------------------- ...
- mysql 打开sql日志,记录所有sql
我使用的mysql版本为:5.7.11 win7环境 记录下下载地址,省得每次百度搜了:http://dev.mysql.com/downloads/installer/ mysql 默认没有开启sq ...
- iOS程序生命周期 AppDelegate
iOS的应用程序的生命周期,还有程序是运行在前台还是后台,应用程序各个状态的变换,这些对于开发者来说都是很重要的. iOS系统的资源是有限的,应用程序在前台和在后台的状态是不一样的.在后台时,程序会受 ...
- Dynamics CRM 2015-Form之控制Ribbon Button
在上一篇中,我用一个例子,简单介绍了如何添加Ribbon Button,以及如何理解RibbonDiffXml,对这方面还不清楚的,可以先看看这篇博文:Dynamics CRM 2015-Form之添 ...
- ZooKeeper 学习笔记
ZooKeeper学习笔记 1. zookeeper基本概念 zookeeper是一个分布式的,开放源码的分布式应用程序协调服务,是hadoop和Habase的重要组件,是为分布式应用提供一致性服 ...
- slf4j+log4j的使用
maven依赖引入 <dependency> <groupId>org.slf4j</groupId> <artifactId>slf4j-log4j1 ...
- spring+struts2+ibatis 框架整合以及解析
一. spring+struts2+ibatis 框架 搭建教程 参考:http://biancheng.dnbcw.net/linux/394565.html 二.分层 1.dao: 数据访问层(增 ...