图像检索中为什么仍用BOW和LSH
原文链接:http://blog.csdn.net/jwh_bupt/article/details/27713453
去年年底的时候在一篇博客中,用ANN的框架解释了BOW模型[1],并与LSH[2]等哈希方法做了比较,当时得出了结论,BOW就是一种经过学习的Hash函数。去年再早些时候,又简单介绍过LLC[3]等稀疏的表示模型,当时的相关论文几乎一致地得出结论,这些稀疏表示的方法在图像识别方面的性能一致地好于BOW的效果。后来我就逐渐产生两个疑问:
1)BOW在检索时好于LSH,那么为什么不在任何时候都用BOW代替LSH呢?
2)既然ScSPM,LLC等新提出的方法一致地好于BOW,那能否直接用这些稀疏模型代替BOW来表示图像的特征?
粗略想了一下,心中逐渐对这两个问题有了答案。这篇博文我就试图在检索问题上,谈一谈Bag-of-words模型与LSH存在的必要性。
一、回顾LSH
LSH方法本身已经在很多文章中有过介绍,大家可以参考这里和这里。其主要思想就是在特征空间中对所有点进行多次随机投影(相当于对特征空间的随机划分),越相近的点,随机投影后的值就越有可能相同。通常投影后的值是个binary
code(0或者1),那么点xi经过N次随机投影后就可以得到一个N维的二值向量qi,qi就是xi经过LSH编码后的值。
问题是LSH是一种随机投影(见图1),上篇博客中也提到这样随机其实没有充分利用到样本的实际分布信息,因此N需要取一个十分大的数才能取得好的效果。因此,[2]中作者理所当然地就想到对LSH的投影函数进行学习(用BoostSSC和RBM来做学习),效果可以见图3。经过学习的LSH就可以通过更少的投影函数取得更好的区分性。这就和BOW的作用有点像了(都是通过学习对原始的特征空间进行划分),只不过BOW对特征空间的划分是非线性的(见图2),而LSH则是线性的。
图1

图2
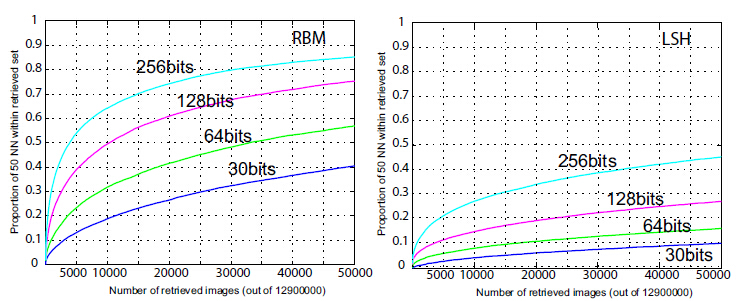
图3
二、LSH VS BOW:检索的时候对什么特征做编码?
( 以下对LSH的介绍将不区分是否利用BoostSSC和RBM来做学习)。LSH一般是对图像的全局特征做LSH。比如图像的GIST,HOG,HSV等全局的特征。可以说,LSH是将一个特征编码成另外一个特征。这有一点降维的味道。经过N次随机投影后,特征被降维为一个长度为N的二值特征了。
BOW一般是对图像的局部特征做编码,比如SIFT,MSER等。BOW是将一组特征(局部特征)编码成一个特征(全局特征),带有一种aggregation的性质。这是它与LSH最大的不同之处。
三、LSH VS BOW:检索和排序的过程有何不同?
先来说说LSH。假设两个样本x1和y1经过LSH编码后得到q1和q2,那么两个样本之间的相似度可以这么计算:
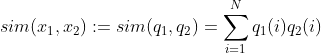
(1)
这就是LSH编码后两个样本之间的汉明距离。假设我们有一个dataset,把dataset里面的图片记做di。有一个查询图片query,记做q。假设已经对dataset和query的所有图片经过LSH编码了,会有两种方式进行图片检索:
a) 建立一张哈希表,di编码后的code做为哈希值(键值)。每个di都有唯一的一个键值。query编码后,在这张哈希表上进行查找,凡是与query不超过D个bits不同的codes,就认为是与query近邻的,也就把这些键值下的图片检索出来。这种做法十分快速(几乎不用做任何计算),缺点在于Hash table将会非常大,大小是。
b) 如果N大于30(这时(a)中的hash table太大了),通常采用exhaustive search,即按照(1)式计算q到di的hamming距离,并做排序。因为是binary code,所以速度会非常快(12M图片不用1秒钟就能得到结果)。
再来说说BOW如何做检索(这个大家都很熟悉了)。假设已经通过BOW得到了图像的全局特征向量,通常通过计算两个向量的直方图距离确定两个向量的相似度,然后进行排序。因为BOW特征是比较稀疏的,所以可以利用倒排索引提高检索速度。
四、BOW能否代替LSH
BOW是从一组特征到一个特征之间的映射。你可能会说,当“一组特征”就是一个特征(也就是全局特征)的时候,BOW不也能用来对全局特征做编码么?这样做是不好的,因为这时BOW并不和LSH等效。为什么呢?一幅图像只能提取出一个GIST向量,经过BOW编码后,整个向量将会只有在1个bin上的取值为1,而在其他bin上的取值为0。于是乎,两幅图像之间的相似度要么为0,要么为1。想像在一个真实的图像检索系统中,dataset中的相似度要么是0要么是1,相似的图片相似度都是1,被两级化了,几乎无法衡量相似的程度了。所以说BOW还是比较适合和局部特征搭配起来用。其实LSH的索引a)方法也很类似,Hash值(codes)一样的图像之间是比较不出相似程度的。确实也如此,但是LSH和BOW相比仍然有处不同,便是经过LSH编码后不会像BOW那样极端(整个向量只有1个值为1,其它值为0)。所以通过1)式计算出的相似度依然能够反映两特征原始的相似度。所以在比较全局特征的时候,还是LSH比较好用些。
五、LSH能否代替BOW
BOW在处理局部特征的时候,相当于两幅图像之间做点点匹配。如果把LSH编码的所有可能级联成一维向量的话,我觉得在一定程度上是起到了BOW相似的作用的。
六、LLC能否代替BOW
不完全可以吧。尽管在识别问题上,LLC性能是比BOW好,但是由于HKM[4]和AKM[5]的提出,BOW的码书可以训练到非常大(可以达到1000000维)。而LLC之类的学习方法就没那么幸运了,说到天上去也就几万维吧。尽管相同维数下BOW性能不那么好,但是放到100万维上,优势就体现出来了。所以在检索问题上,BOW依然如此流行。
----------------------------
参考文献:
[1]Video Google: A Text Retrieval Approach to Object Matching in Videos
[2]Small Codes and Large Image Databases for Recognition
[3]Locality-constrained Linear Coding for Image Classification
[4]Scalable Recognition with a Vocabulary Tree
[5]Object retrieval with large vocabularies and fast spatial matching
作者的另外一篇文章:CVPR14与图像视频检索相关的论文:http://blog.csdn.net/jwh_bupt/article/details/23039357
图像检索中为什么仍用BOW和LSH的更多相关文章
- 计算机视觉中的词袋模型(Bow,Bag-of-words)
计算机视觉中的词袋模型(Bow,Bag-of-words) Bag-of-words 读 'xw20084898的专栏'的blogBag-of-words model in computer visi ...
- 图像检索(6):局部敏感哈希索引(LSH)
图像检索中,对一幅图像编码后的向量的维度是很高.以VLAD为例,基于SIFT特征点,设视觉词汇表的大小为256,那么一幅图像编码后的VLAD向量的长度为$128 \times 256 = 32768 ...
- lecture7图像检索-七月在线-cv
http://blog.csdn.net/u014568921/article/details/52518587 图像相似性搜索的原理 BOW 原理及代码解析 Bag Of Visual Words ...
- Bag of Features (BOF)图像检索算法
1.首先.我们用surf算法生成图像库中每幅图的特征点及描写叙述符. 2.再用k-means算法对图像库中的特征点进行训练,生成类心. 3.生成每幅图像的BOF.详细方法为:推断图像的每一个特征点与哪 ...
- 图像检索(4):IF-IDF,RootSift,VLAD
TF-IDF RootSift VLAD TF-IDF TF-IDF是一种用于信息检索的常用加权技术,在文本检索中,用以评估词语对于一个文件数据库中的其中一份文件的重要程度.词语的重要性随着它在文件中 ...
- 相似图像识别检 —基于图像签名(LSH)
原文链接:http://grunt1223.iteye.com/blog/828192 参考:人工智能,一种现代方法 第 617页,且原始论文给出了完整的证明过程.在ANN方法中,LSH算一种可靠的紧 ...
- BoW算法及DBoW2库简介
由于在ORB-SLAM2中扩展图像识别模块,因此总结一下BoW算法,并对DBoW2库做简单介绍. 1. BoW算法 BoW算法即Bag of Words模型,是图像检索领域最常用的方法,也是基于内容的 ...
- 图像检索——VLAD
今天主要回顾一下关于图像检索中VLAD(Vector of Aggragate Locally Descriptor)算法,免得时间一长都忘记了.关于源码有时间就整理整理. 一.简介 虽然现在深度学习 ...
- Spring Batch在大型企业中的最佳实践
在大型企业中,由于业务复杂.数据量大.数据格式不同.数据交互格式繁杂,并非所有的操作都能通过交互界面进行处理.而有一些操作需要定期读取大批量的数据,然后进行一系列的后续处理.这样的过程就是" ...
随机推荐
- 优秀的web端 vue框架
之前得到消息vue在GitHub已经超过react,成为第一大框架,让我们来看看以vue为基础的开发框架有哪些? Element(start-28128) 饿了么前端推出的基于 Vue.js 2.0 ...
- 51nod1212 无向图最小生成树
N个点M条边的无向连通图,每条边有一个权值,求该图的最小生成树. Input 第1行:2个数N,M中间用空格分隔,N为点的数量,M为边的数量.(2 <= N <= 1000, 1 < ...
- 51nod1256 乘法逆元【扩展欧几里得】
给出2个数M和N(M < N),且M与N互质,找出一个数K满足0 < K < N且K * M % N = 1,如果有多个满足条件的,输出最小的. Input 输入2个数M, N中间用 ...
- mysql查询表里的重复数据
先贴个简单的SQL语句 select username,count(*) as count from hk_test group by username having count>1; 使用详情 ...
- ro多层的事务处理失败的困惑
现象: 用 :: ::'' 在客户端用上面的语句取得数据,然后修改数据,通过RO的web service提交数据失败: 用 -- ::-- ::'‘ 在客户端用上面的语句取得数据,然后修改数据,通过R ...
- hdu 1568关于斐波那契数列的公式及其思维技巧
先看对数的性质,loga(b^c)=c*loga(b),loga(b*c)=loga(b)+loga(c); 假设给出一个数10234432,那么log10(10234432)=log10(1.023 ...
- 0619数据库_MySQL_由浅入深理解索引的实现
转自http://blog.csdn.net/u010003835/article/details/51563348 这篇文章是介绍MySQL数据库中的索引是如何根据需求一步步演变最终成为B+树结构的 ...
- 介绍一个不错的服务器综合监控工具脚本集aspersa
http://blog.csdn.net/jackyrongvip/article/details/9217869
- 【ACM】hdu_zs1_1001_水仙花数_201307271504
水仙花数 Time Limit : 2000/1000ms (Java/Other) Memory Limit : 65536/32768K (Java/Other)Total Submissio ...
- 【ACM】hdu_1096_A+BVIII_201307261748
A+B for Input-Output Practice (VIII)Time Limit: 2000/1000 MS (Java/Others) Memory Limit: 65536/32 ...